Making Go errors play nice with Sentry
April 6, 2022 — 8 min read

Here at incident.io, we provide a comprehensive Slack-based incident response tool, powered by a monolithic Go backend service. This service manages API interactions for Slack, powers a web dashboard, and runs background jobs essential for incident management.
Incidents are high-stakes, and we want to know when something has gone wrong. One of the tools we use is Sentry, which is where our Go backend sends its errors.
When something goes wrong, we:
- Open the error in Sentry
- Use the stacktrace to find the code that went wrong
- Go into the code to apply a fix
Sadly, standard Go errors don't have stacktraces. The way Go wants to model errors makes it hard to get much value from a tool like Sentry at all.
We've had a nightmare getting errors to work for us. While we're a long way from perfect, our setup is much closer to what we were used to in other languages, and Sentry is much more useful as a result.
Here's how we did it.
Why stacktraces are essential for Go error reporting
Sentry is almost useless without a stacktrace.
As Go's standard library opts not to implement them, we need to find a library that does.
Written by Dave Cheney, pkg/errors is the de-facto standard for Go applications. For years this package has been the standard error library for Go, though the project is now archived. I suggest we ignore that, as the library's ubiquity means it's unlikely to disappear, and there isn't an alternative that offers the same functionality.
pkg/errors implements a StackTracer error which provides what we need. Many tools have been built against this interface – Sentry included – so provided we use its errors.New, Sentry will be able to extract the trace and present it.
import (
"github.com/pkg/errors"
)
func main() {
errors.New("it ded") // will include a stacktrace
}
As a sidenote, it took a while to understand which package to use. While pkg/errors seems to have won, it's archived and unmaintained, which isn't the best of signs. Then xerrors had similar goals, but is also shutdown and only partly incorporated in the standard library.
For something as critical as how to handle errors, it's a confusing ecosystem to find yourself in.
Ensuring consistent stacktraces across your Go codebase
With pkg/errors we can now create errors which include stacktraces. But it's not always our code that produces the error, and while we can lint our own code to ensure we always use pkg/errors, a lot of our dependencies (including the standard library) won't.
If, for example, we have:
f, err := os.Open(filename)
We're stuffed, as the err won't have a stacktrace at all.
The errors returned from the stdlib are extremely basic, and don't want to pay the performance penalty of building a stacktrace. As an example, here's the definition of fs.PathError which you receive if Open can't find a file:
type PathError struct {
Op string
Path string
Err error
}
As you can see, there's no stacktrace to be found in that struct.
To fix this, we're going to try 'wrapping' our errors, using the Wrap function that comes with pkg/errors.
In our codebase, you'll almost always see the following pattern when handling errors:
f, err := os.Open(filename)
if err != nil {
return errors.Wrap(err, "opening configuration file")
}
Wrap does two things here: first, it creates an error with a stacktrace set to wherever you called Wrap. When we send this error to Sentry, it will include a stacktrace, helping us in our debugging.
Secondly, it prefixes the error message with our contextual hint. The full message, once wrapped, might be:
opening configuration file: open /etc/config.json: no such file or directory
By consistently wrapping our errors, we help generate stacktraces at the deepest frame possible, helping the Sentry exception give as much context as possible about how this error occurred.
Challenges of wrapping errors in Go
You might think that is all: sadly, there is more to go.
While wrapping errors has ensured any errors that reach Sentry have a stacktrace, some of our errors start looking very strange when they finally get to Sentry.
Take this code, for example:
package main
import (
"time"
"github.com/getsentry/sentry-go"
"github.com/pkg/errors"
)
func main() {
sentry.CaptureException(one())
}
func one() error {
return errors.Wrap(two(), "trying one")
}
func two() error {
return errors.Wrap(three(), "trying three")
}
func three() error {
return errors.New("it ded")
}
While contrived, most of your application code will end up like this, where a source error is wrapped several times over.
This makes Sentry quite sad, as instead of getting a single stacktrace, you'll get one for every time you wrapped an error:
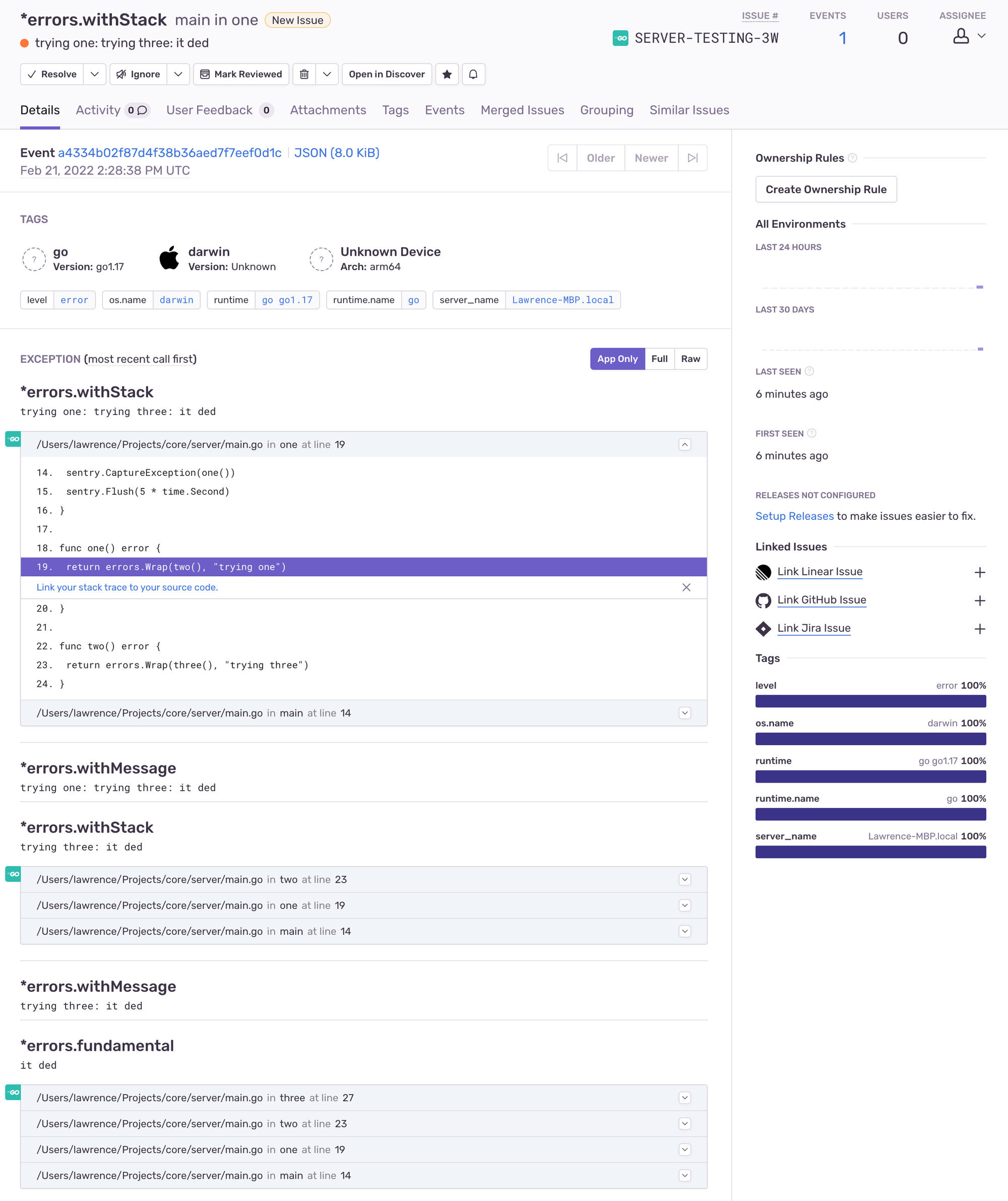
That's not ideal: each stacktrace is just a subset of the other, as they're taken one at a time with a single frame removed. Larger callstacks can get even worse, making it much harder to get value from the report.
Even worse, sometimes the error will exceed Sentry's size limit and get dropped before you ever see it.
Well, this needs fixing.
Creating a custom pkg/errors for better error handling in Go
At this point, it was clear we needed to take control over how we produced errors if we wanted our tools to work well with each other.
First step, then: we created our own pkg/errors, and applied a linting rule that banned any imports of errors or github.com/pkg/errors to ensure consistency.
Our package exported several of the key pkg/errors functions, as we have no reason to change how they behave:
package errors
import (
"github.com/pkg/errors"
)
// Export a number of functions or variables from pkg/errors.
// We want people to be able to use them, if only via the
// entrypoints we've vetted in this file.
var (
As = errors.As
Is = errors.Is
Cause = errors.Cause
Unwrap = errors.Unwrap
)
What we did want to change, though, was how Wrap behaved. Where the original would add a stacktrace each time it was called, ours should only add a stacktrace if the error didn't already have a trace that we were an ancestor of.
The term ancestor may need some explaining, so let's go back to our previous example. Let's comment the stacktraces we'd create when wrapping each error at the callsite of one and three:
// main
// one
func one() error {
return errors.Wrap(two(), "trying one")
}
// main
// one
// two
// three
func three() error {
return errors.New("it ded")
}
When we wrap the error in one, it will already have a stacktrace attached from when we wrapped it in three. Our Wrap function will:
- Evaluate the current stacktrace at the point of wrapping (main, one)
- Look into the original error for an existing stacktrace (we will find one, it will be main, one, two, three)
- If our current stacktrace prefix matches the existing stacktrace, we know we're an ancestor and can avoid generating a new trace
Switching our example code to use the de-duplicating Wrap means we'll produce just one trace, and it'll be the most comprehensive (ie, the deepest).
Here's what that looks like in Sentry:
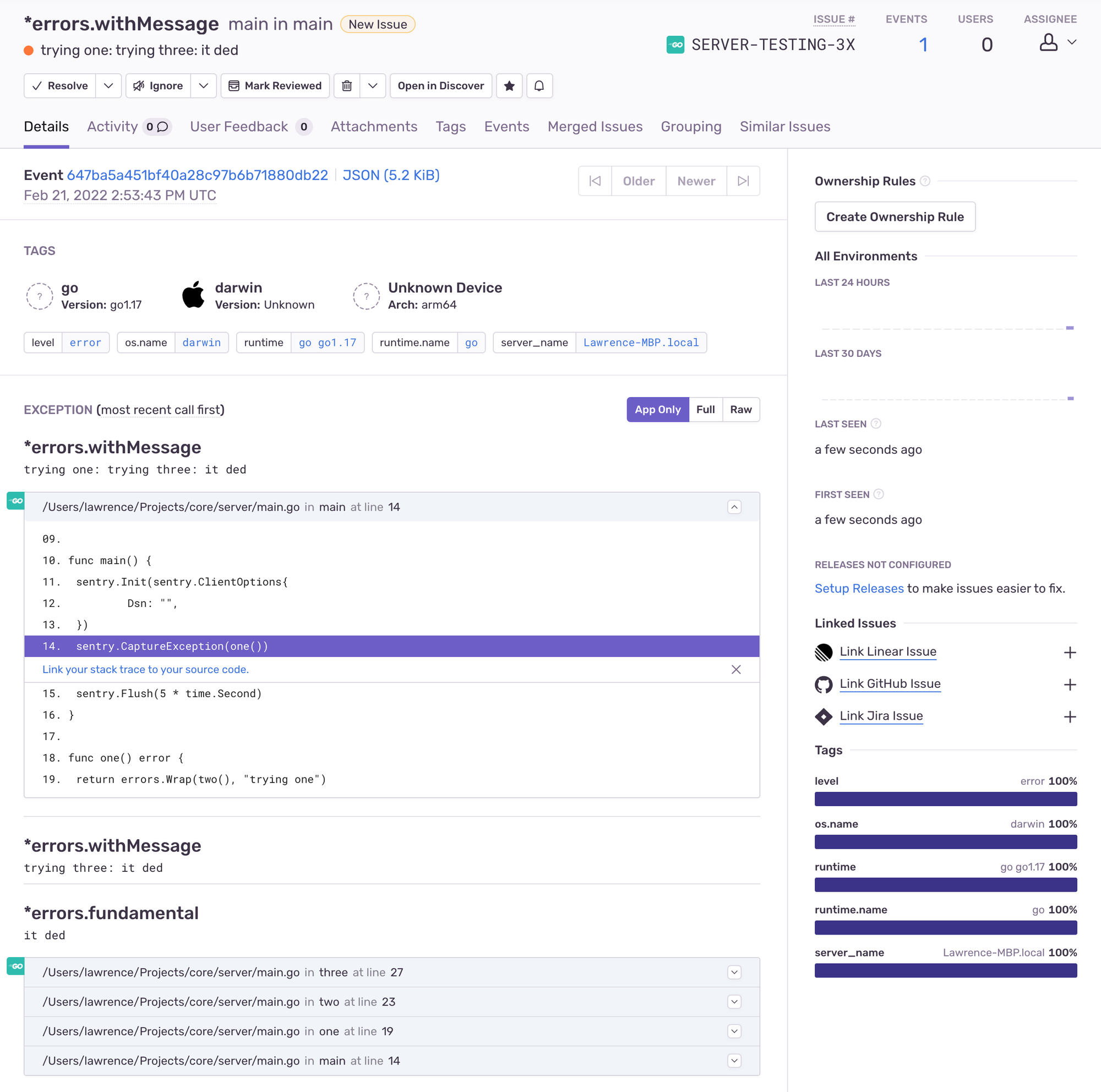
De-duping can work really nicely, as prefix matching the stacktraces means:
- Only direct ancestor stacktraces are de-duplicated
- If you wrap errors from other goroutines, you retain the separate stacktraces, as goroutines begin with an empty stack
- Errors passed along channels will also fail to prefix match, preserving the individual stacktraces
It was fiddly to implement, so we've uploaded a copy to this gist if you'd like to use it yourself.
That's a wrap!
Go can be a tricky language, sometimes. Coming from a background working with Rails, a lot of the things I took for granted when building web applications either aren't there or aren't as good, and it's hard to find consistent answers from the wider community.
Exception/error reporting is an example of this. As a team, we were surprised at how difficult it was to get well configured error reporting into our app, especially when this would've worked out the box in other languages.
Thankfully we've found some workarounds that get us closer to what we miss. It's a gradual process of finding and removing awkward trapdoors, and like this article, getting the language to play with the tools we're used to.
We've since extended our pkg/errors to support error urgency and general metadata, which we'll save for another post. This should be a good head-start for those facing similar issues, and avoid other teams hitting the same speed bumps!

Lawrence Jones
Product Engineer
See related articles

Don't add a read replica until you've read this
Our learnings from implementing a product-wide read replica migrations, including some useful patterns for routing queries to replica and primary
 Johanna Larsson
Johanna LarssonJuly 21, 2026

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


