Building Workflows, Part 2 – the executor and evaluation
September 14, 2022 — 26 min read

This is the second in a two part series on how we built our workflow engine, and continues from Building workflows (part 1).
Having covered core workflow concepts and a deep-dive into the Workflow Builder in part one, this post describes the workflow executor, and concludes the series with an evaluation of the project against our goals.
- Part 1
- Part 2
Workflow executor
We’ve discussed the user-facing aspects of building and configuring workflows, and the APIs that power those flows. But after you’ve created a workflow, what decides when it should run? And executes each of the steps of a workflow, tracking progress along the way?
This is the responsibility of the workflow executor, which interprets the workflow configuration and uses engine constructs to power the execution.
Taking a high-level view, the process looks like this:

First, parts of the incident system will fire a message saying “a workflow trigger event has occurred”. If you think about the incident.updated trigger, this will be fired whenever anything happens to an incident from its status changing to a custom field being updated, and should be interpreted as “workflows with an incident.updated trigger may need executing in response to this”.
The executor listens for these events, which contain trigger-specific payload such as the organisation and incident ID that it relates to. We search for any workflows that match this trigger, loading both the workflows and the most recent workflow_versions, then check if the conditions apply for a scope built from the trigger parameters.
If conditions match, we create workflow_runs row in the database, and fire a workflow-run-enqueued event, which the executor subscribes to and will respond by executing the workflow step-by-step.
Quite simple, but there’s a few technical nuances around how we built the executor that are worth discussing, particularly around:
- How often workflows run: most workflows should only run once per incident, or for some other type of ‘once-for’ configuration
- Avoiding concurrent executions, and at-least once retries
- Tracking and exposing workflow progress and error to users
We’ll answer this below, starting with a view of the workflow data model.
Data model
It’s useful to begin with the data model of workflows, as this helps join the concept of the configuration that users create to the data tracking workflow executions.
As we use Postgres as our datastore, the data model is relational, using normalised tables. It’s useful to mention Postgres as we use some specific features for execution, though we’ll get to them later.
In total, we have four tables:
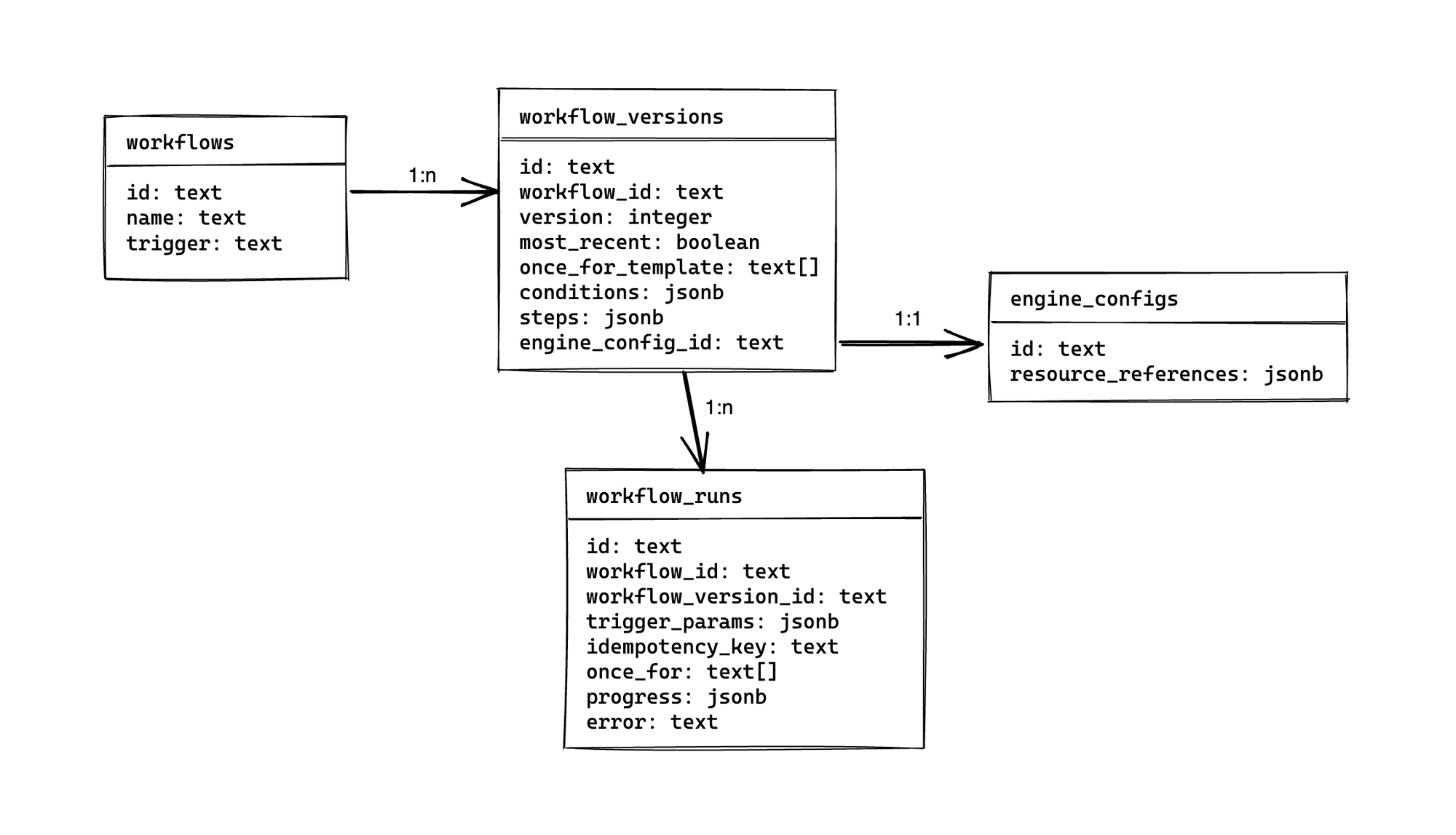
At the top we have workflows, with one row for each workflow. It stores the name of the workflow and the trigger (e.g. incident.updated or custom_field.updated), with the trigger being stored right as workflow triggers are immutable.
Each workflow has one or more workflow_versions, which is where we store the bulk of workflow configuration. You’ll see columns for conditions and steps which store the workflow config in JSON format, along with the version and most_recent columns used to track changes to workflow config and identify the most recent (active) configuration.
For each workflow_versions row we also store an engine_configs. We don’t make use of this for workflow execution: these rows store a JSONB array of referenced resources that, backed by a GIN-index, allow us to quickly find any workflows that might reference other incident.io resources (such as a custom field) so we can warn before you delete them.
Finally, the table that is most relevant to workflow execution: workflow_runs, which has a row created for every workflow execution, and is linked to a specific workflow_versions in order to lock the config that is used for this execution.
That’s a complete picture of everything we store, and will be a useful reference as we discuss the implementation.
Controlling how often workflows run
Triggering workflows might seem simple, but the naive approach breaks down quickly.
Take a workflow that escalates to a PagerDuty policy whenever an incident severity is greater than Major.
One way to power this workflow would be a ‘severity-updated’ trigger, firing whenever an incident’s severity has been changed. The executor will check if the conditions match (is severity > Major?) and if so, enqueue and execute a workflow run.
Seems good, but there’s a couple of problems even in this simple case.
Firstly, this workflow (escalating the PagerDuty) is something you want to run just once, the first time the conditions match for a given incident. But any subsequent severity update would fire this trigger, which could cause us to escalate repeatedly.
Then we must consider what happens when first creating an incident. As you can declare incidents with a specific severity, an incident could be created with a severity > Major – matching our workflow – and we probably want it to execute then, too. But a trigger called ‘severity-updated’ doesn’t make this clear, and might confuse people.
Worse than both these issues, though, is what happens when a workflow is configured with conditions that span more than a single incident dimension. Using our example of a paging workflow, imagine we add to the conditions that “the Affected Service custom field must be Production”, to ensure we only page when we’re impacting production services.
If a user was to create an incident, set the Affected Service custom field and then update the severity, we’d be fine. But it’s equally valid to first update the severity and only then set the Affected Service field, in which case we would:
- Update severity, firing the severity-updated trigger, but as conditions don’t match (Affected Service is unset) we don’t execute
- Set Affected Service, which does not fire the severity-updated trigger, so the workflow never executes
It’s very reasonable to expect our workflow would fire in this situation, and we’ll probably have unhappy customers when they don’t get paged.
We can fix all these problems with a solution in two parts. Part one is offering a single ‘incident-updated’ trigger which fires whenever anything about an incident has been changed, and part two is to build the concept of idempotency into the workflow executor.
For the ‘incident-updated’ trigger, the incident.io system would fire an event in response to:
- Someone updating an incident custom field
- An incident status being changed
- Whenever an incident update modifies the incident severity
And whatever else that might change the result of evaluating workflow conditions. This means we fix the problem of not activating if changes to an incident come in the wrong order, because now we check workflow conditions on every change, firing as soon as all conditions match.
This leaves the final issue, which is about repeatedly executing a workflow: something that has got much worse now we encourage most workflows to use this ‘incident-updated’ trigger, rather than more specific triggers like ‘severity-updated’ which fire far less frequently.
We solve this by introducing a concept of ‘once-for’ workflow configuration, as in, “this workflow should only run once for a given circumstance”.

The workflow_versions table stores a list of scope references in a once_for_template column, which the executor uses to generate the once_for column for the workflow_runs whenever it decides workflow conditions are satisfied and an execution is due.
Triggers decide the default once_for_template for a workflow, and the ‘incident-updated’ trigger defaults to ["incident"], meaning we produce once_for values of a singleton array containing the incident ID.
Recall that we create a workflow run before we enqueue the event that tries executing it? Well the trick comes by adding a unique index to the workflow_runs table on the once_for column, meaning Postgres prevents us from ever creating more than one workflow run with the same once_for value for any given workflow.
CREATE UNIQUE INDEX idx_workflow_runs_idempotency_key
ON workflow_runs USING btree (workflow_id, once_for);
COMMENT ON INDEX idx_workflow_runs_idempotency_key
IS 'Only one run can be created for a given workflow/once-for combination.';
We catch the conflict in the executor code, and know that such a conflict means we’ve already satisfied the once-for configuration for this workflow, and need not enqueue a fresh run.
func (wf *Workflow) CreateWorkflowRun(ctx context.Context, db *gorm.DB) (*domain.WorkflowRun, error) {
// build the workflow run payload
// ...
run, err := domain.NewQuerier[domain.WorkflowRun](db).
Clauses(clause.OnConflict{DoNothing: true}).
Create(ctx, payload)
if err != nil {
return nil, errors.Wrap(err, "creating workflow run in database")
}
// This means we've had a conflict, and found another workflow run
// with the same once-for and workflow id. Take no action.
if run == nil || run.ID == "" {
return nil, nil
}
return run, nil
}
That the executor now handles idempotency helps us in a number of ways, both by solving the issues around workflow ergonomics that we explained before, but also making us robust to a number of situations that might have double-run workflows before.
For example, it means the event consumer for our trigger events can be retryable, as we know workflows can only be created once for any once-for configuration. And powered by a database index, the conflict checking is cheap, with Postgres guaranteeing consistency for us.
Finally, our users benefit too: the workflows UI permits tweaking the once-for to achieve very specific workflow behaviour. We’ve seen people create workflows on the ‘incident-channel-joined’ trigger with a once-for on ["user"], which they use to send a Slack DM to users whenever they first join an incident channel, along with other surprising use cases.
Concurrent execution, and at-least once retries
Now the executor ensures we only ever create one workflow run in the database for any once-for/workflow combination, we’ve handled the major causes of double running workflows.
There is still an issue, though, in that our async worker system is Google Pub/Sub. Like most event systems, Pub/Sub aims for at least once delivery of events, which opens us to number of issues around publishing the ‘engine-workflow-run-enqueued’ event after creating a workflow run in the database.
They are:
- Pub/Sub could deliver this message to more than one consumer, causing two consumer to attempt execution of the same workflow run concurrently
- Network failure could mean a consumer starts processing the message, executes the workflow run, but then never successfully acks the message in Pub/Sub: this will cause the message to be redelivered to another consumer, which will process the workflow run again
- If a consumer fails halfway through processing a workflow – e.g. step 2/3 – then retrying the message will re-run steps if it begins from the start of the workflow run
We don’t want any of these issues, and want to minimise any other sources of double-running.
The solution is to make workflow execution incremental, and leverage the database for concurrency-control.
In psuedocode, processing an ‘engine-workflow-run-enqueued’ message looks like:
def execute(workflow_run)
loop do
lock_workflow_run(workflow_run.id) do |workflow_run|
step_index, complete, error = work_next_step(workflow_run)
raise error if error
update_progress(workflow_run, step_index, now())
break if complete
end
end
mark_as_complete(workflow_run)
end
Execution happens in a loop, attempting to execute the workflow one step at a time.
The first thing to note is that we lock the workflow run at the start of the loop. In this case, we are using Postgres to lock the entire workflow_runs row in FOR UPDATE, ensuring our executor thread is the only connection permitted to be working with the row until we release the lock.
This solves our concurrent execution problem, as we lock and fetch the most up to date version of the workflow run in one atomic operation, which we then use to decide which step to next work.
We decide the next step by examining the progress column, which looks like this:
[
{
"step": "slack.send_message",
"status": "complete",
"completed_at": "2021-11-30T12:57:53.164562Z"
},
{
"step": "pagerduty.escalate",
"status": "pending",
"completed_at": null
}
]
This example shows the workflow has two steps – sending a Slack message, then escalating to PagerDuty – and that only the first has completed.
Our work_next_step function uses this progress marker to decide the next step to execute is escalating to PagerDuty, and our execution loop will save the result of executing that step back into the progress field on the workflow run, before we ever release our lock.
This locking ensures even with many competing consumers trying to execute the same workflow run that only one step will ever be processed at a time, and we’ll never process the same step more than once. The steps might be distributed across several processes, but the workflow will behave as if it was executed serially on a single thread.
And in the case that a consumer dies midway through executing a workflow, the next consumer to pick up the job will restart from the last workflow step processed.
Tracking and exposing workflow progress
From what we’ve discussed, it should be clear that executing workflows can become complex, and customers have strict expectations around when and how we execute them.
Systems like this benefit from showing their work, ideally persisted, and immutable.
As a side effect of what the solutions we’ve discussed, the executor does just this: the progress column exposes step-by-step details about how and when they were executed, and workflow runs store timestamps about completion/failure/stalling and even track the errors they saw, if one occurs.
This is useful if we ever need to debug the system, but it’s also useful for our customers, who want to see when and where a workflow has been run.
Having stored workflow runs as we have, exposing a GET /workflow_runs endpoint is trivial, and can be used to power an audit log that we display on the workflows show page in the dashboard:
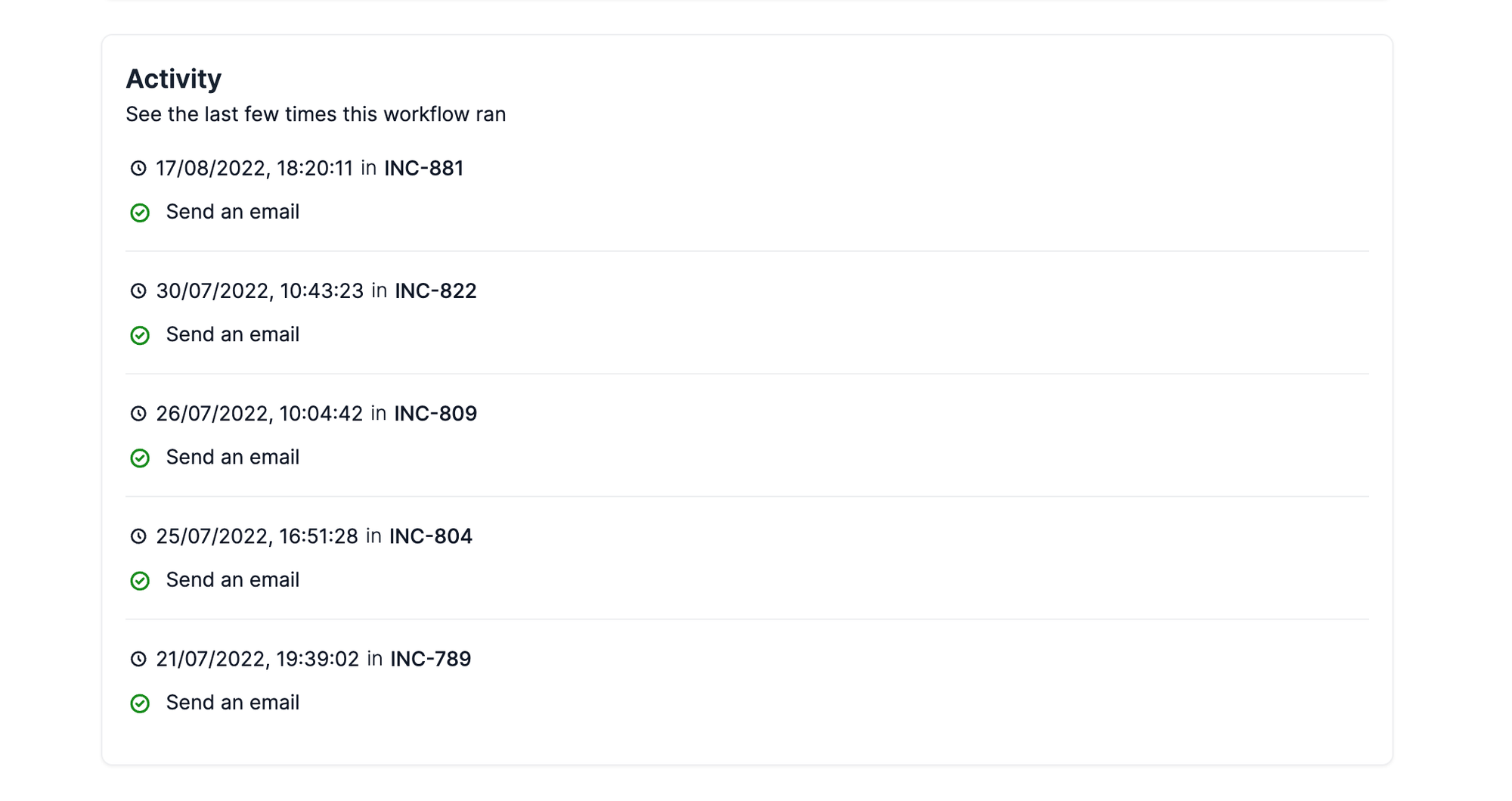
It’s an example of how the underlying design of the system can add value at the user level, and doesn’t have to be just an implementation detail.
Evaluation
Congratulations, you’ve made it through a long and detailed walkthrough of one of our most complex product features. That’s the technical content done, and we’ll finish by considering if this project achieved its goals. I’ll try and keep it punchy!
As a start-up, you want to try avoiding big up-front projects, and over-engineering can be disastrous.
That’s why workflows felt a bit strange: we began the project with a discussion of how minimal our ‘MVP’ should be, and ended up building something very similar to the end result from the get go.
This was a deliberate break from our standard practice, but was driven by:
- Conviction that workflows were to become a core part of our product, integral to future features, and were extremely unlikely to go away.
- My (the author’s) personal experience having worked with workflow systems before, where I’d seen how the same operational problems crop up time and again. Some – such as integrity checking of workflows – were issues that can be solved efficiently if designed up-front, but become extremely costly if grafted into the system later.
- Our belief that the engine at the heart of workflows would enable building other, totally different product experiences.
- Knowing that once we had a workflow framework, we’d eventually add a library of other steps, triggers and resources, and we’d like that to be very minimal effort.
We can understand the success of the project through whether these predictions were accurate, and if we saw the return on investment that we expected.
Build effort
Development time can be split into the initial project that built the workflow framework, followed by ad-hoc feature requests and small tweaks we’ve made in response to customers and as part of running the service, mostly around expanding the number of steps, triggers and resources.
The initial build began on October 12th 2021, with 2 developers taking 3 weeks to release the first customer facing aspect of workflows: a product feature called Anouncement Rules, which was implemented on top of the workflow engine.
After this, it took 3 additional weeks to build the workflow builder UI that we describe in this post, and 1 more week to fully release workflows.
That totals to 7 weeks of 2 developers or 70 days of developer time, and resulted in a release that supported 3 triggers, 13 steps and 20 different resources. That’s a significant investment for a company of our size (we had 3 developers at the time) and even with announcement rules being released in the middle, it was a while to go without shipping big features.
But if we think back to our motivation picking this path, we expected workflows to be extremely popular, and for us to add a significant number of additional workflow capabilities in response to customer feedback.
On both counts we were correct, and we can see it from charting how we developed these features over time.
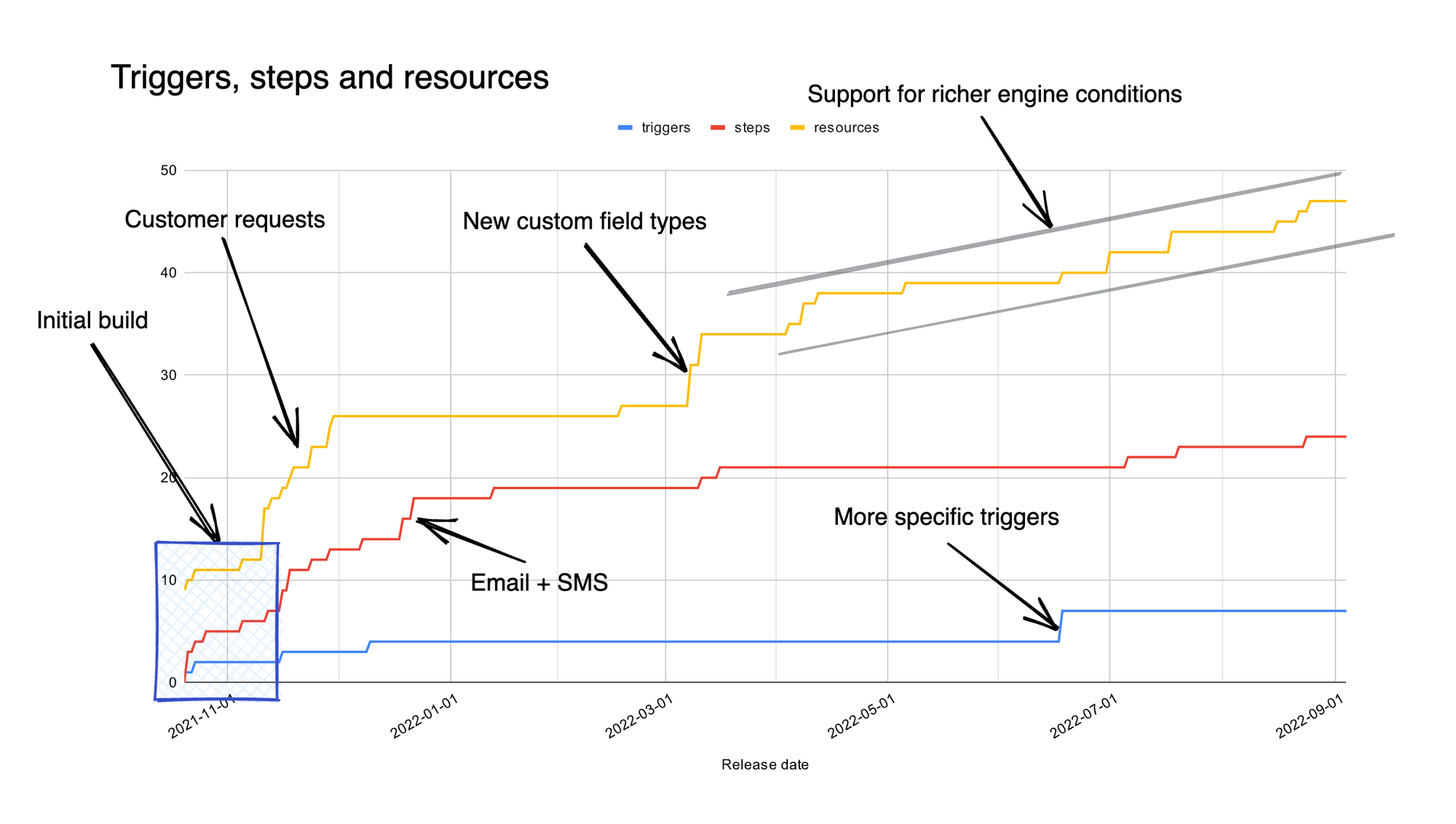
The chart spans almost 10 months, and shows how the majority of workflow functionality has been added after the initial build of the framework. In fact, we have more than 2x as many triggers and steps and almost 3x as many resources, all built in response to customers demand.
We were right about demand, then, but what about effort? If adding each trigger, step or resource takes a couple of days, that means we’d have spent ~70 developer days on extensions which is almost as long as we spent on the initial build itself.
Thankfully, analysis of our ticket board and git logs suggests this isn’t true. From that data, most resources were added in <0.5 days and often several in just one morning/afternoon, and each additional trigger took a couple of hours.
More impressively, adding steps also comes in at <0.5 days per step. When you consider a step can range from “set incident role” to “escalate to PagerDuty”, these are entirely new capabilities added to incident in a single morning. The fact that you can write the backend step and have the entire UI derived automatically is what makes this possible: I tried adding email and SMS steps for fun, and managed to build both in a single day.
Onboarding and defects
That’s not to say this has been entirely smooth sailing. In fact, one thing we’ve learned is to warn new joiners about workflows before they dive right in: it’s more complex than the rest of our codebase, and you have to learn how things work before you can leverage the abstractions.
But once you get it, you can build stuff really quickly at a high quality. And that tends to result in happy developers.

And as a final comment on build quality, I’m happy that since the first release of workflows, there have been no bugs that were fundamental to the framework.
That doesn’t mean no bugs at all: we’ve seen things like our workflow builder screw up variable interpolation in the editor, and permitted workflow configurations that couldn’t possibly make sense (mostly around once-for).
But the core of the workflow builder and the APIs that power it have been rock solid. Provided you implement the workflow and engine interfaces correctly, you’ll get a working feature, and that’s worth some up-front learning.
Extensibility and robustness
And almost most importantly, the idea that workflows and its engine would power an increasingly large surface area of our product was a big motivator to properly invest.
In theory, the engine was much more general than workflows: it was about modelling ‘things’ and allowing our customers to ask questions about them, and take actions on them. As a platform that derives a lot of its value from tying together various systems, this felt like a core competency we didn’t want to skirt on.
This has now paid off, as we’ve started to use engine conditions separately of workflows for a number of product features. One example is powering Incident Types, where core account configuration like custom fields and incident roles can make themselves conditional on a specific incident type (and anything else supported by the engine!) and – more recently – in Incident Policies, where you can describe compliant incidents in terms of engine conditions.

It’s useful to reuse the engine for these features so you can benefit from everything that comes alongside it: your frontend for configuring conditions is free, as is the backend code for evaluating them, and you get the supporting infrastructure too.
One of the most key examples of consolidating our investment is in deletion protection. Consider a case where a workflow has conditions about a custom fields – e.g. Affected Service is Production – or steps that try messaging someone assigned to a specific incident role.
What do you do when the customer tries deleting the Affected Service field? Or the incident role they’re trying to message?
The naive answer is you just delete that custom field or role, but that will effectively break all workflows that depend on it. That could be really problematic, as we’ve seen how people depend on workflows for all sorts of critical processes.
Our ideal solution would be to warn the user that deleting this resource will affect some workflows, and ideally list them, so they can make a decision on how to adapt the configuration. The only issue is how do you find what workflows reference the resource you’re trying to delete? Do we need to exhaustively scan all workflows?
We knew this would be a problem from the start, which is why we created the engine_configs table with the resource_references column, as shown in Execution > Data model. Whenever a workflow or anything that uses engine resources is saved, we build a list that looks like this:
[
{
"type": "IncidentSeverity",
"value": null
}, {
"type": "IncidentSeverity",
"value": "01FD7MSVXV954DD0B3WWAE859Q"
}
]
That can be understood as “this config makes use of the IncidentSeverity resource type, and of the specific IncidentSeverity value of 01FD7MSVXV954DD0B3WWAE859Q". Storing this in the engine_configs table and using a GIN index, we can make array subset matches against this column almost free, allowing us to quickly ask “which workflows use X resource type/with value Y?”.
We use this reverse lookup to power our deletion warnings, which look like this:

And because policies and workflows both use the underlying engine abstraction, they automatically gain support for deletion protection for any of the resources they might reference.
That’s a feature we might’ve struggled to build had we not found a generic solution for it, and would have been difficult to graft onto an engine framework that less formally modelled it’s types and values.
Round-up
Workflows are at the heart of incident.io, and we do more with them every day.
It’s one of the most complex parts of our product, no doubt about that. But the consistency, polish and developer velocity we get from leveraging them has more than paid for that complexity. That’s easy to see from how much the team enjoys working on the projects that use them, and how fast we can build those features.
I hope this gives an insight into how a core part of a software’s architecture evolves alongside an engineering team, and a candid look into our priorities and how we made our decisions. Behind-the-scenes views are rare, and it’s not often people share both the technical details of how something was built, and the effort evolved in maintaining and extending it over time.
And a final call: if work like this excites you, be sure to check our open roles, as we’re always hiring for engineers.

Lawrence Jones
Product Engineer
See related articles

Don't add a read replica until you've read this
Our learnings from implementing a product-wide read replica migrations, including some useful patterns for routing queries to replica and primary
 Johanna Larsson
Johanna LarssonJuly 21, 2026

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


