Best incident management tools for customer success: Customer-facing incidents
January 30, 2026 — 18 min read
Updated January 30, 2026
TL;DR: The gap between Engineering fixing an incident and Customer Success managing customer communication creates friction that extends MTTR and erodes trust. The solution is automation. Define "Customer Impact" using service-level metrics, not gut feel. Automate status updates from your technical incident channel directly to public pages. Create a "Customer Liaison" role in your incident response workflow so CS has visibility without distracting engineers. Teams that treat customer communication as a technical pipeline reduce MTTR by eliminating coordination overhead and reduce support ticket volume by 20-60% through proactive communication.
Why the gap between Engineering and CS hurts MTTR
It takes an average of 23 minutes and 15 seconds to get back on track after a distraction. During a SEV1 outage at 3 AM, every Slack DM asking "Is it fixed yet?" costs your incident commander 23 minutes of cognitive recovery time. Multitasking or switching between tasks drains up to 40% of productivity, according to research on context switching costs for developers.
The distraction tax is real. When your SRE is juggling Datadog alerts, a Zoom bridge with five engineers, and a Slack channel with 47 messages, the last thing they need is your CS lead DMing "Customer X is on the phone, what do I tell them?" That question, however valid, just cost you 15 minutes of troubleshooting momentum.
The problem compounds when communication fractures. Engineering says "investigating Redis latency" in their war room. CS tells customers "the entire platform is down." Your biggest customer tweets "been down for an hour with no update" while your team is 20 minutes into active resolution. Trust evaporates on both sides.
Miscommunication or lack of coordination leads to delays in incident resolution and exacerbates customer impact. Fragmented communication and delayed information sharing hinder response efforts. Without a centralized platform, teams experience missed updates, duplicated efforts, and conflicting information reaching customers.
"I appreciate how incident.io consolidates workflows that were spread across multiple tools into one centralized hub within Slack, which is really helpful because everyone's already there. It really helps teams manage and tackle incidences in a more uniform way." - Alex N. on G2
Defining "Customer Impact" to align SRE and CS teams
You cannot coordinate if you don't agree on what "down" means. High CPU is an Engineering issue (SEV3). High CPU causing 500 errors on checkout is a Customer issue (SEV1). The difference is measurable customer impact, not technical severity.
Define Customer Impact using three dimensions: scope (how many customers), functionality (what's broken), and duration (how long). A severity matrix maps technical symptoms to customer impact. At Atlassian, SEV1 is "a critical incident with very high impact" including customer data loss, security breach, or when a client-facing service is down for all customers. SEV2 is "a major incident with significant impact." SEV3 is "a minor incident with low impact."
Create this matrix with your CS team before the next incident:
| Technical Severity | Technical Symptom | Customer Impact | Communication Required |
|---|---|---|---|
| SEV1 | Service completely down for all users | No customers can access core product functionality | Immediate status page update within 15 minutes, updates every 30 minutes |
| SEV2 | Degraded performance or partial outage | Subset of customers experiencing delays or errors | Status page update within 30 minutes, updates every 60 minutes |
| SEV3 | Minor performance issues | Minimal customer-facing impact, most users unaffected | Optional status page update, internal communication sufficient |
Determine who needs to be notified and what actions must be taken at each severity level to provide a clear escalation matrix. This prevents confusion and ensures critical incidents receive immediate attention. A system outage during peak hours might be SEV1, while the same issue during off-hours might be SEV2, based on actual customer impact rather than technical metrics alone.
Map your monitoring data to these definitions. Configure Datadog or Prometheus to tag alerts with customer impact severity automatically. When error rates on the payment API exceed 5%, that's SEV1 because checkout is broken. When background job latency climbs, that's SEV3 because customers don't see it.
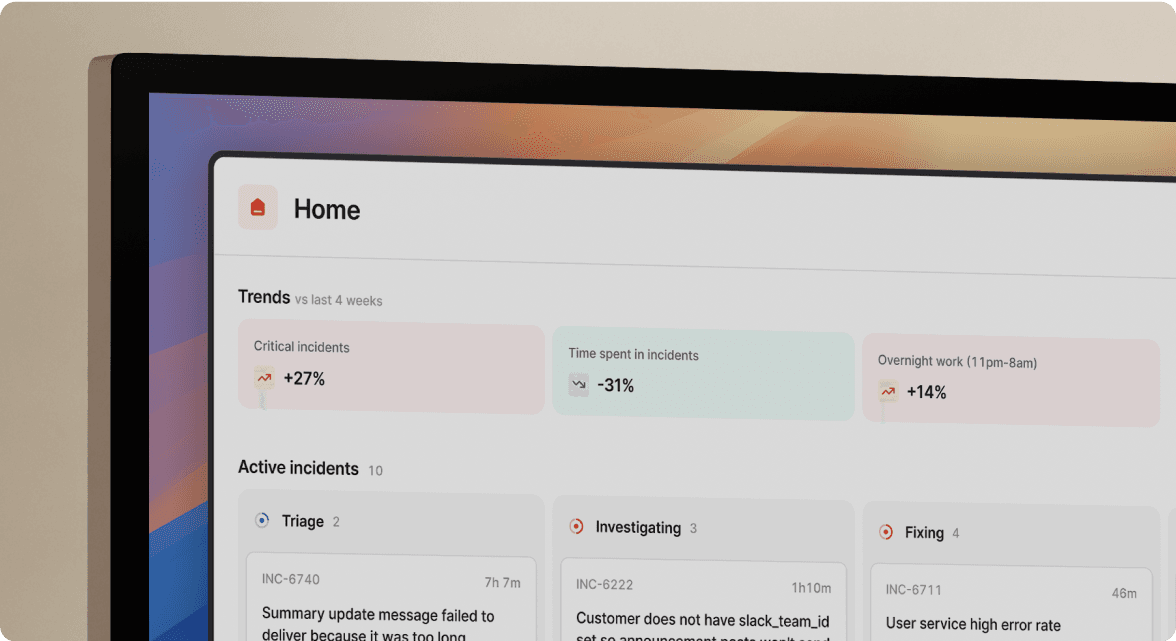
Automating the communication pipeline from alert to status page
The workflow starts with an alert. Monitoring tools flag a potential issue. Within minutes, the on-call engineer triages it, confirming if it's real or a false alarm. If confirmed, the Incident Commander declares an incident, recording its start time and scope. The Communications Lead quickly posts the first public update, usually within 10 to 15 minutes, stating what's affected, who's impacted, and when to expect the next update.
The ideal flow eliminates manual handoffs:
- Alert fires from Datadog/Prometheus detecting customer-facing error rates
- Incident declared via
/incidentcommand in Slack - Channel auto-created with on-call engineers, service owners, and designated CS liaison
- Internal updates posted in-channel by Incident Commander
- Status page draft auto-generated from latest incident summary
- Public update published from Slack with one command
- Updates repeat every 30-60 minutes until resolution
- Resolution posted automatically when incident closes
incident.io's workflow automation opens a Slack channel dedicated to the incident that includes on-call engineers and the service owner. The process repeats with regular updates until resolution, with incident.io ensuring it's followed consistently every time.
The key is eliminating context switches. Your Incident Commander should never open a browser tab to update a separate status page tool while troubleshooting. The update happens where the work happens.
For a visual walkthrough of automating incident response across operations, Slack demonstrates how integrated workflows reduce manual coordination overhead during critical moments.
Crafting effective incident communications with copy-paste templates
Translate "technical truth" into "customer assurance." Your engineers think in services and dependencies. Your customers think in outcomes and workarounds.
Before (too technical): "Postgres connection pool exhaustion in us-east-1 causing elevated p99 latency on API endpoints."
After (customer facing): "We are investigating delays affecting customers in the US East region. Our team is working on a resolution and will provide updates every 30 minutes."
Use these three templates for incident communication that balance transparency with clarity:
Template 1: Investigating
We are currently experiencing [describe impact in customer terms] with [affected service/feature]. Our engineering team is investigating the cause and working on a resolution. [Affected customer segment] may be affected. We will update this status page in [30/60] minutes.
Template 2: Identified
We have identified the issue causing [describe impact]. The problem is [brief non-technical explanation]. Our team is actively working on [fix description]. We expect [service/feature] to be fully restored by [estimated time] and will provide another update in [30/60] minutes.
Template 3: Resolved
The issue affecting [service/feature] has been fully resolved as of [time and timezone]. All systems are now operational. We sincerely apologize for any inconvenience during this [duration] outage. Our team will conduct a thorough post-incident review.
These status page templates for incident management provide starting points you can customize for your specific services and customer base. The goal is consistency. Pre-approved templates let your CS liaison post updates fast without waiting for engineering approval on every word.
Best practice is posting the first public update within 10 to 15 minutes, stating what's affected, who's impacted, and when to expect the next update. For major incidents, publish an initial status update within 1 hour of incident start time, with updates posted every 30 minutes thereafter as new information becomes available.
Comparing tools for managing customer-facing incident communication
Not all incident management platforms bridge the Engineering and CS gap equally. Here's how the major tools handle customer communication:
| Platform | Status Page Integration | Update Method | CS Team Visibility | Strengths | Limitations |
|---|---|---|---|---|---|
| incident.io | Built-in, Slack-native | /inc status command in incident channel | CS liaison role in incident channel | Unified workflow, no context switching, automated updates from Slack | Requires Slack/Teams as central hub |
| PagerDuty | Separate add-on required | Manual login to separate tool | Limited unless shared access configured | Strong alerting and escalation | Siloed from actual incident workflow, requires separate status page tool |
| Atlassian Statuspage | Standalone tool | Manual login to web dashboard | No native incident channel access | Industry standard, robust customization | Manual updates frequently forgotten during incidents |
incident.io treats Status Pages as built into your incident workflow, prompting you to post when it matters most. You can automate updates entirely or use templates with pre-approved messaging to move faster. Share updates with customers or internal teams through integrated Status Pages published directly from Slack.
In contrast, PagerDuty focuses on alerting and on-call scheduling. While excellent for waking people up, it creates a silo where CS has no visibility into the technical response. Teams typically juggle PagerDuty for alerting, Slack for communication, Jira for tracking, Confluence for documentation, and a separate tool like Statuspage for customer updates. That's five tools during a high-pressure incident.
Atlassian's Statuspage is the industry standard for public status communication, but it's often disconnected from actual incident workflows. Engineers must remember to open a separate browser tab, log in, find the correct incident, and type an update while simultaneously troubleshooting in Slack. This context switching leads to forgotten updates and stale information.
"incident.io allows us to focus on resolving the incident, not the admin around it. Being integrated with Slack makes it really easy, quick and comfortable to use for anyone in the company, with no prior training required." - Andrew J on G2
Measuring the impact of your communication strategy
Track three metrics jointly between SRE and CS teams:
1. Time to First Public Update
Measure minutes from incident declaration to first customer-facing status page post. Industry benchmark for SEV1 incidents is 10 to 15 minutes. Track this in your incident timeline. If you're consistently missing this window, your process has too many manual handoffs.
2. Support Ticket Volume During Incidents
Count inbound tickets specifically asking "Is the system down?" or "When will this be fixed?" Teams using proactive status pages report an average 24% fewer support tickets during incidents. Some companies see 20-40% reduction in ticket volume with proactive communication. One SaaS company reduced incident tickets by over 60% after launching their public status page.
3. Customer Satisfaction During Incidents
Survey customers who contacted support during outages. Ask "Did you feel informed about the incident progress?" and "How would you rate our communication during the issue?" Track CSAT or NPS specifically for incident periods. According to PWC research, 32% of consumers would stop doing business with a brand they loved after just one bad experience, highlighting the importance of effective incident communication.
Build a dashboard showing these three metrics over time. Present it quarterly to leadership showing how communication improvements reduce support load and maintain customer trust during outages.
How incident.io eliminates the Engineering and CS communication gap
Three specific capabilities solve the coordination problem:
1. Status Pages published directly from Slack
When you're 15 minutes into a critical incident, the last thing you need is opening a browser tab to update a separate status page. With incident.io, type /inc status in your incident channel, fill out a modal with the customer-facing message, and publish. The update goes live on your public or internal status page instantly.
The workflow is: Type command, fill modal, post update. No context switching. No separate login. The status page lives inside your incident response workflow, not beside it. You can configure status page subscriptions so customers receive email or SMS notifications automatically when you publish updates.
For a demonstration of post-incident workflows in incident.io, watch how the platform streamlines communication from resolution through customer notification.
2. Customer Liaison role with controlled access
Using incident.io's Roles, you can easily assemble the cross-functional team needed to resolve incidents. Create a "Customer Liaison" role assigned to your CS lead or on-call support manager. This role has permission to:
- View the incident timeline and all messages
- Post status page updates using approved templates
- Add notes and questions in designated threads
- But NOT run technical commands or assign engineering tasks
This gives CS visibility into the technical response without cluttering the channel with non-essential chatter. The liaison translates engineering updates into customer-facing messages in real time, eliminating the DM barrage to your Incident Commander.
Configure role permissions so only specific team members can create, manage, or post to status pages, maintaining quality control while distributing responsibility.
"The slackbot gives you all of the incident management functions you need at your finger tips: pinning to track important discoveries, actions taken/completed, and prompts to broadcast updates." - Paul S on G2
3. AI-drafted summaries for customer updates
incident.io's AI synthesizes key events, decisions, and outcomes from your Slack incident channel into coherent summaries. You'll see a suggestion when there's enough information to produce a good summary, and the existing summary is starting to go stale.
The AI considers conversation in the channel, timeline events, and role assignments to draft an update. Your Customer Liaison reviews it, adjusts technical language to customer-friendly terms, and publishes in seconds. This eliminates the "staring at a blank text box" problem when you need to write the third update in an hour while still troubleshooting.
We started with AI features like suggested summaries and follow-ups that reduce operational overhead from configuring alerts to finishing follow-ups so you can focus on actually fixing the issue.
"Incident provides a great user experience when it comes to incident management. The app helps the incident lead when it comes to assigning tasks and following them up... In a moment when efforts need to be fully focused on actually handling whatever is happening, Incident releases quite a lot of burden off the team's shoulders." - Verified user on G2
Recommended approach for giving CS access to incident channels
Use a two-part strategy based on Google SRE best practices. Centralized communication is an important principle. When disaster strikes, SREs gather in a "war room." The key is gathering all incident responders in one place and communicating in real time to manage and ultimately resolve an incident.
1. Assign a single designated liaison
Don't invite your entire CS team to every incident channel. Designate one person per shift as the "Customer Liaison" using incident.io's role system. This person joins the incident channel automatically when declared, watches the technical conversation, and owns all customer-facing communication.
The liaison asks clarifying questions in dedicated threads to keep the main channel clear for responders. They translate "Redis connection pool exhausted" into "experiencing delays with checkout" without requiring the Incident Commander to stop and explain.
2. Create communication guardrails
Set expectations in your incident response documentation:
- Technical discussion happens in main channel: Engineers post updates, theories, and decisions here
- CS questions go in threads: Liaison can ask "Is checkout completely down or just slow?" in a thread, not interrupting the main flow
- Status updates get pinned: When someone posts a good summary, pin it so the liaison can reference it
If you need extensive back-channel communication, create a separate private #incident-cs-sync channel for coordinating customer response strategy without cluttering the technical war room.
"Without incident.io our incident response culture would be caustic, and our process would be chaos. It empowers anybody to raise an incident and helps us quickly coordinate any response across technical, operational and support teams." - Matt B on G2
Understanding how internal status page subscriptions differ from public ones helps you design appropriate visibility for different stakeholder groups.
Key terms
Customer Impact Duration: The specific time window where users experienced degradation or outage, distinct from the total time engineers spent investigating and fixing the root cause. Used to set accurate expectations in customer communications.
Status Page: A public or private dashboard communicating real-time health status of services to users. Reduces support ticket volume by proactively informing customers about known issues and resolution progress.
Incident Liaison: A designated role responsible for translating technical updates from the incident response team into customer-facing communications. Acts as the bridge between Engineering and Customer Success during active incidents.
SEV1/SEV2/SEV3: Severity classifications based on customer impact scope and urgency. SEV1 typically means complete service outage affecting all or most customers, requiring immediate communication and round-the-clock response.
Ready to eliminate the communication gap between your SRE team and Customer Success? Try incident.io in a free demo and test the Status Page integration with your next incident. Run a game day scenario to see how the Customer Liaison role keeps CS informed without distracting your responders.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


