Exclude weekends from your incident policies
June 25, 2024

Last week we had a company offsite in Marseille!
We had a lot of fun, toured some vineyards, made some lovely soap, pretended we were competing for the pink jersey, rode down a mountainside in an open top bus at the sort of speed only a rural driver can and discovered Americans aren’t all that bad at football!
But… alongside all that fun, in a laptops-by-the-pool fashion we also shipped some really cool stuff!
Here’s some of the highlights, at least one of which I can confirm was shipped from a train to Gare du Lyon.

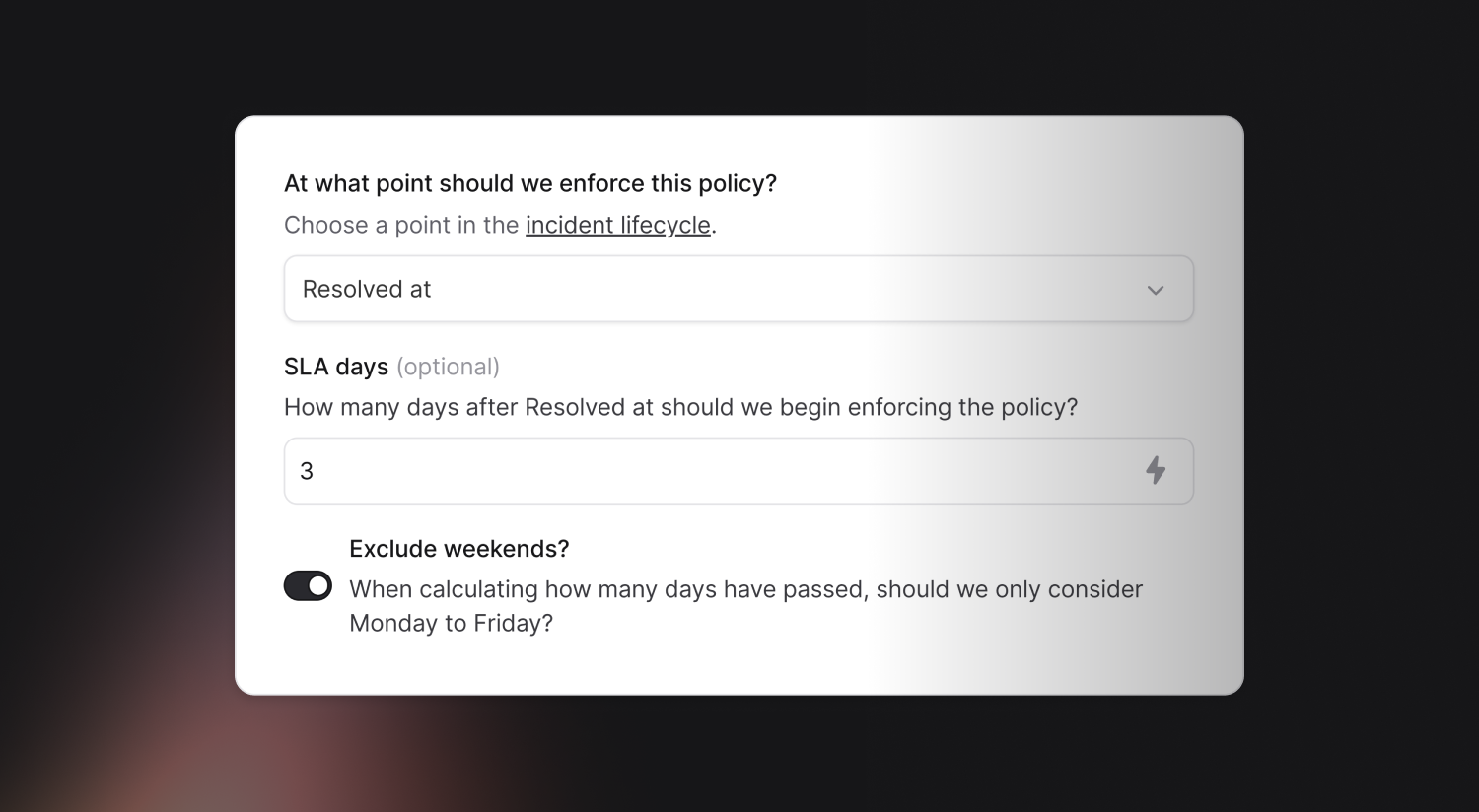
Polices can now exclude weekends
In our product it's possible to create a policy to help ensure that incident response is consistent across your organisation, such as:
after an incident in resolved, follow-ups should be assigned with 2 days
However, previously, if you had a policy like this and resolved an incident on a Friday, we would have bothered you on the Sunday that you'd not hit your SLA 🤦♀️
Now, you can choose whether or not to exclude weekends from your policies!
To enable this, you can change the configuration of SLA Days on your policy, and adjust the time accordingly. For example, if your existing policy took 7 days to violate, you'd probably want to change that to 5 days if you're excluding weekends.
Note that we re-sync violations every hour, on the hour, so you'll just need to wait a little while for your existing violations to be adjusted when making changes.
New alert source: Crowdstrike
You can now send alerts from Crowdstrike Falcon to incident.io!
Configure your webhook endpoint and any workflows you need in Falcon, and you’ll be able to have those alerts appear in incident.io, allowing you to take full advantage of our powerful features Alerts and Catalog.
Use our JavaScript alert evaluation to only alert when certain endpoints are affected, or the rules which triggered an alert match a regex pattern!

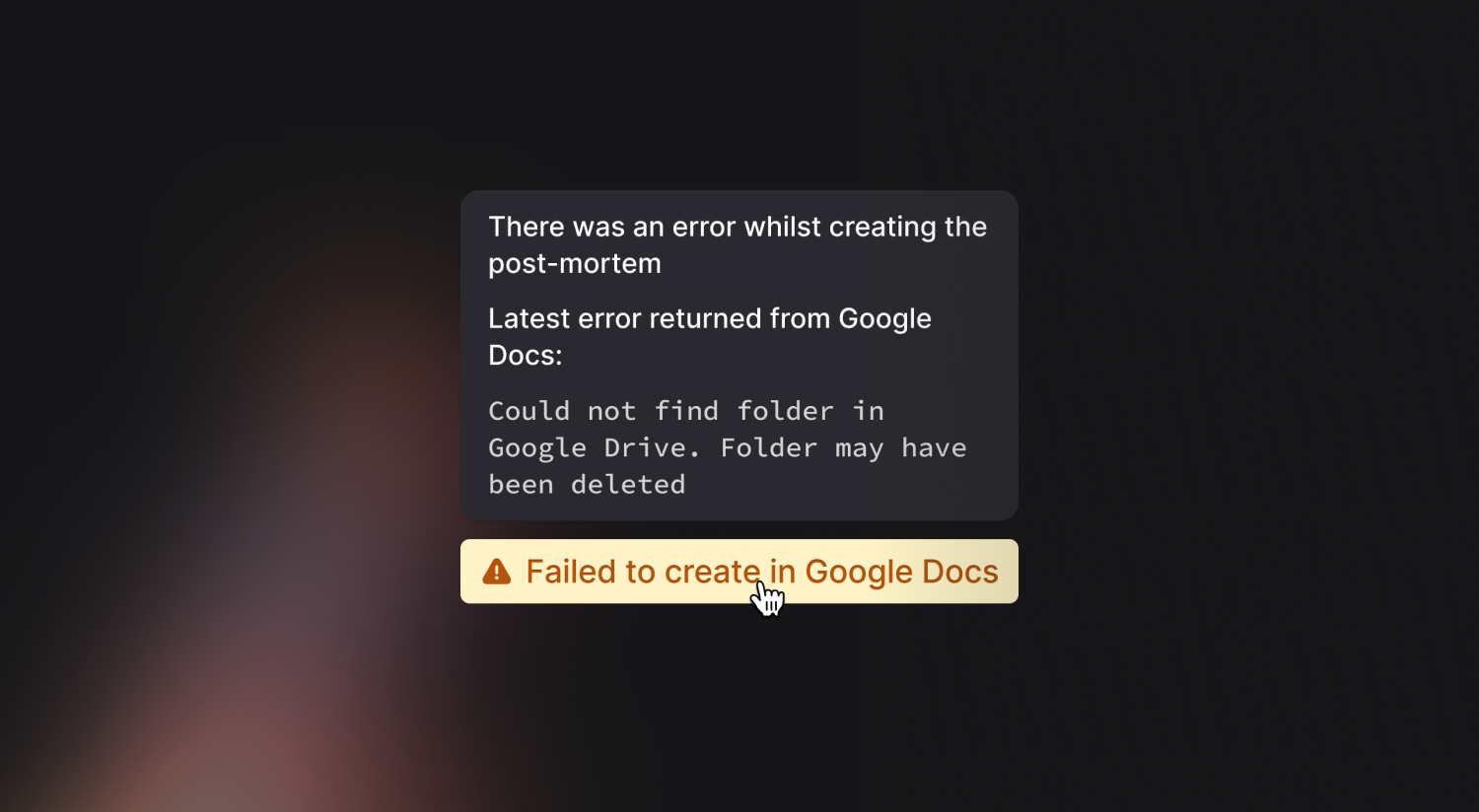
Better postmortem exports
Previously, our Postmortem export flow occurred in what nerds call a ‘synchronous’ fashion. This meant when you clicked the button in our UI to export a Postmortem, we sent that request to your document provider, waited for that to complete, then told you if it had been successful.
This can feel sluggish - we have to send a load of requests and if you had a complicated or slow export this wouldn’t be a great experience.
We’ve fixed this, now this’ll happen in the background, making the experience feel much more snappy. We’ve also totally overhauled how we report errors, meaning in the unlikely event that your document fails to export - you’ll be able to work out why that happened.
🚀 What else we’ve shipped
New
- You can now connect a GitLab issue as a follow-up by pasting it into an incident channel
- You can now access the status page incidents that an incident is connected to in workflows
- We now support scheduled maintenance events on status page sub-pages
Improvements
- You can now reference the source of an incident in post mortem templates
Bug fixes
- Fixed a bug where it wasn't possible to save smart escalation paths with no repeats
- Fixed a bug which would send duplicate notifications when an integration breaks
- Improved retries for slow responses when talking to Jira
- Catalog ranking is now respected for components on a status page sub-page
- Fixed an issue with some insights dashboards not being visible in the dashboard switcher
- Long workflow names are now displayed correctly on the workflows list page
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


