Automate incident creation with Alerts
January 17, 2024

Alerts
Automatically creating incidents has been a tremendously helpful feature for incident responders, removing the need to manually create incidents every time there is a page or ensuring there is an incident channel home to quickly take action when there is a legitimate issue.
However, up until recently, customers have only been able to automatically create incidents from their paging solutions (e.g. PagerDuty, Opsgenie) or via the API.
Unsurprisingly, we’ve had requests for organizations to auto-create incidents from other sources as well. So, we are excited to share our latest feature: Alerts!
Alerts will allow organizations to connect your alert sources to incident.io to automatically create incidents. This new feature will also provide additional customization so we can better route alerts into incidents and build more sophisticated automations (ie. workflows) off the back of those alerts.
Alert sources
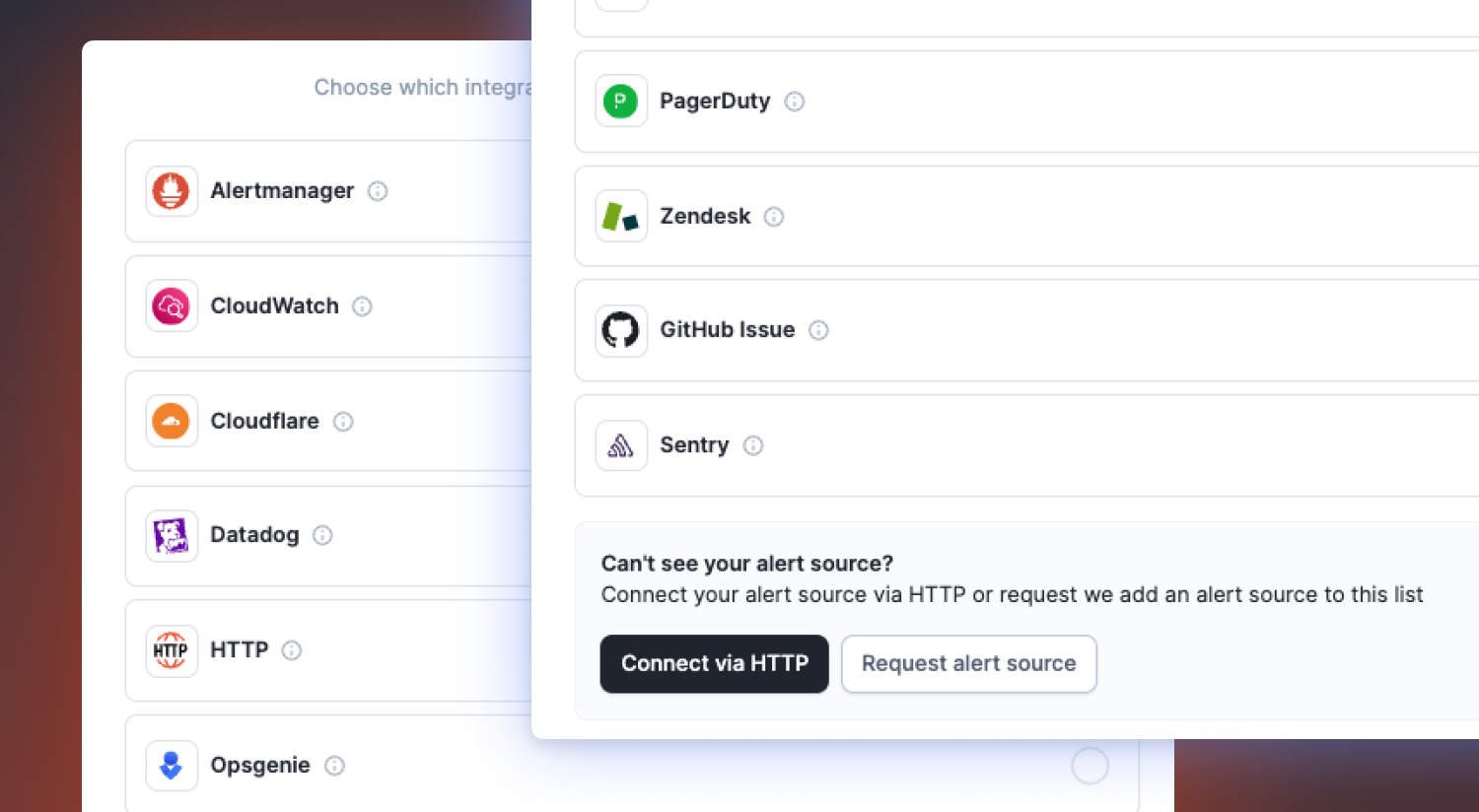
To get started using Alerts, you will need to set up the connection between incident.io and your alert source(s). We connect with a variety of alert sources:
- Paging tools such as Opsgenie or PagerDuty
- Monitoring tools such as Datadog or Prometheus
- Service management tools like Zendesk
If we don’t have an integration in place for your preferred source, you can simply connect via HTTP, which will work with most solutions that use webhooks.
Once you have selected the source you’d like to connect, we provide easy-to-follow instructions on how to start receiving alerts into incident.io.
Custom alert attributes
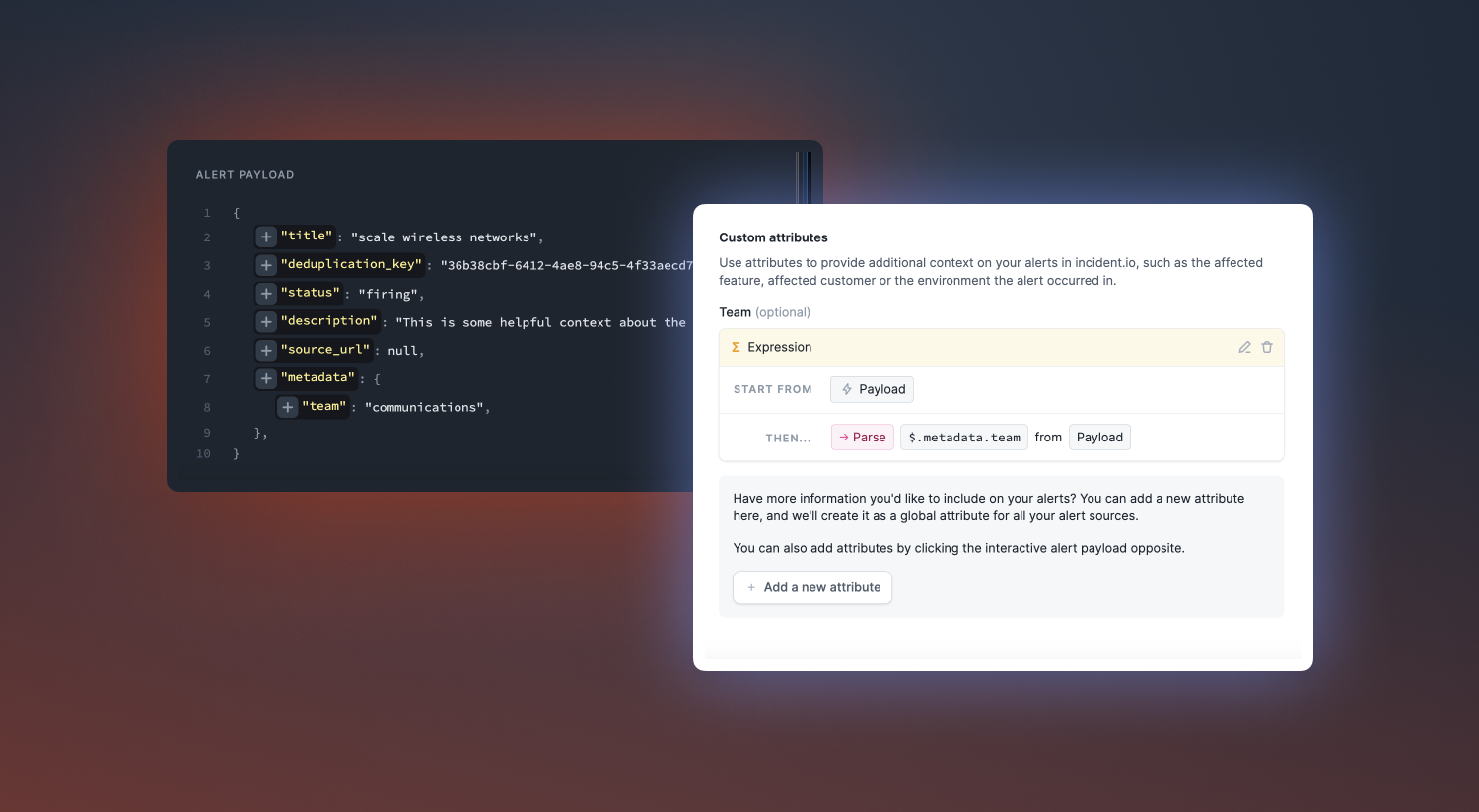
When connecting your alert sources to incident.io, you can add custom attributes to provide more context to your alerts. Examples include: team, affected customer, affected feature or environment. This allows you to pull values from your alert payload into rich data on your incidents.
These can provide helpful clues for responders when digging into the alert issue. Plus, it will be a helpful way of grouping and filtering your alerts into incidents via alert routes.
Alert routes
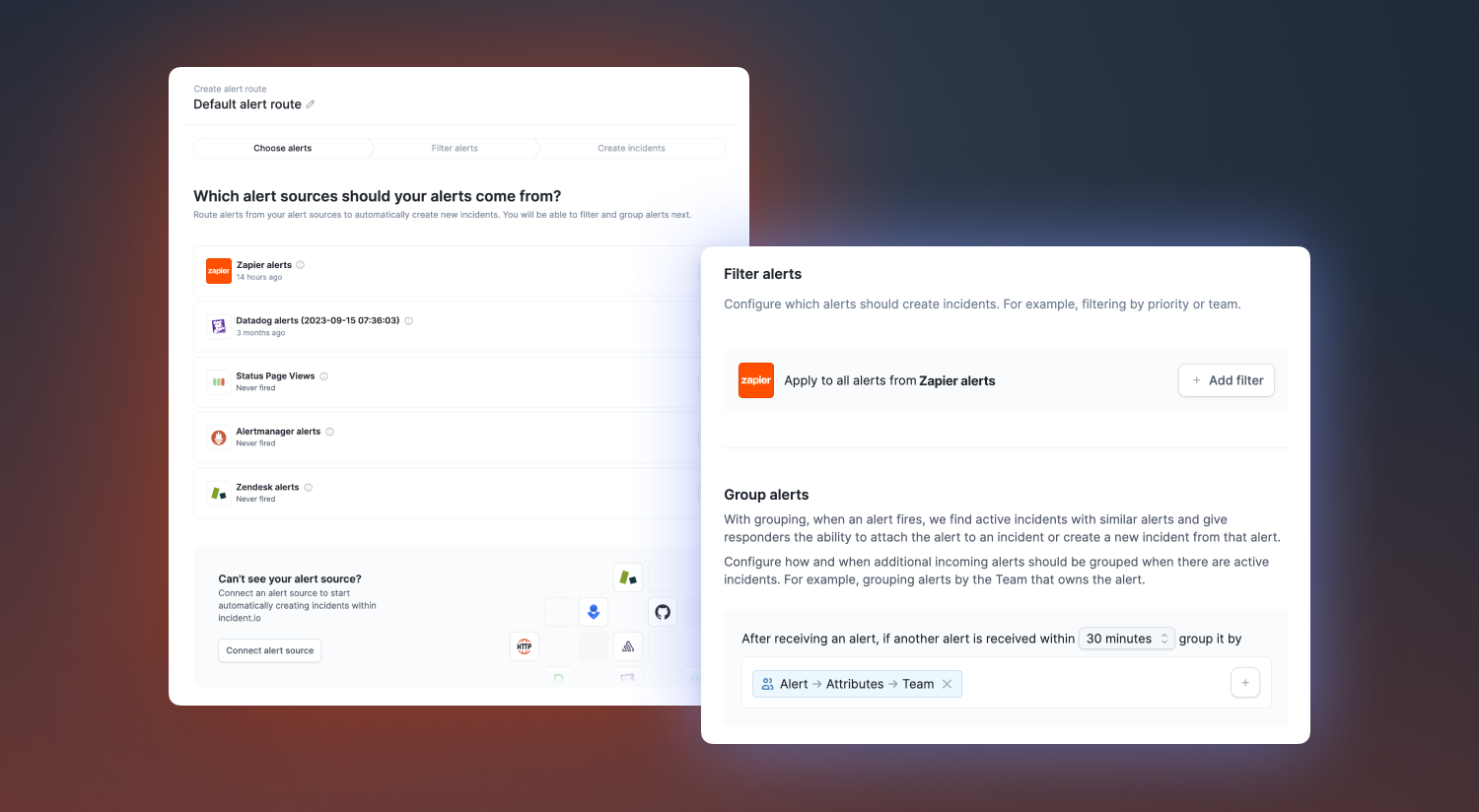
Once you have connected your alert sources, to automatically create incidents, you’ll need to set up your alert routes. With alert routes you can:
- Select one (or multiple!) alert sources to auto-create incidents
- Filter any alerts you do not want to auto-create incidents for (i.e. low priority alerts)
- Group alerts, so when an alert fires, we find active incidents with similar alerts and give responders the ability to attach the alert to an incident or create a new incident from that alert (ie. grouping alerts by the team that owns the alert)
- Configure how incidents are created (ie. populating custom fields from alert data)
After your alert routes are set and your alert source is firing, you will start to see auto-creation in action! This should relieve stress on your responders, reducing need to manually create incidents and providing additional information to help mitigate issues quickly.
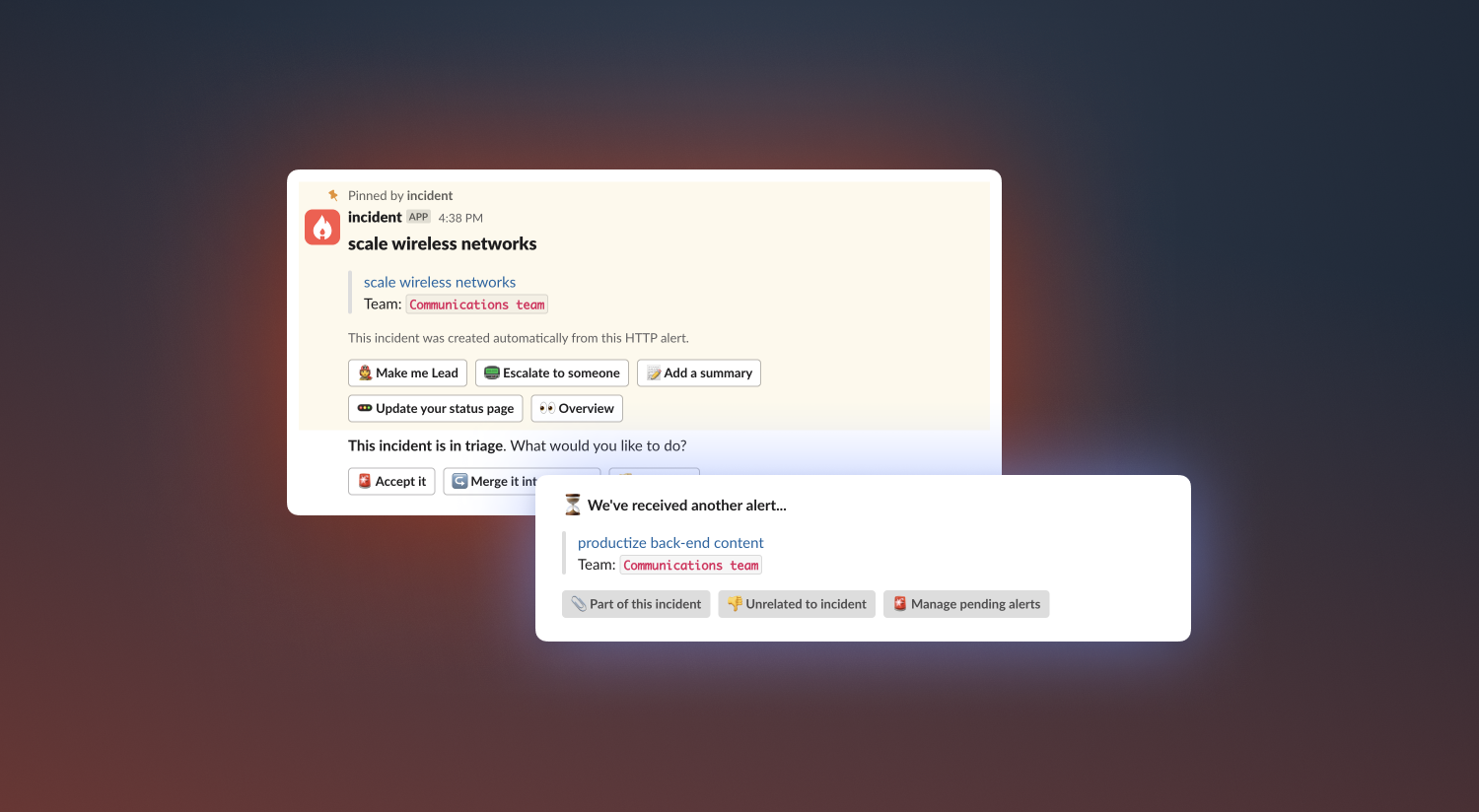
There are plenty of new bells and whistles with the new Alerts feature, so please refer to our handy help docs (here and here) for more support as you dig in!
New ways to generate incident summary
Previously, we would only suggest you a new summary whenever you provide an incident update. Now, there’s a shiny Generate button on the /inc summary and /inc resolve modals which will create a new summary for you!
Additionally, you will see a Generate button on the Do you want to add a summary? nudge.
🚀 What else we’ve shipped
New
- In v3.1 of our Terraform provider, you can now set the
type_nameof a catalog type, so it can be referred to asCustom[”Team”]elsewhere in your configuration - You can now subscribe to a webhook that fires when an incident's status changes
- When you're using a 'send Slack message' step in the workflow builder, we will default to the incident Slack channel
- You can now control whether to show your component uptime percentage on your status pages
- Show suggested related incidents first when you are manually linking incidents within the dashboard
- You can customise the section names for suggested summaries
- If you communicate in a non-English language in the incident channel, we can now enable incident summary suggestions in your preferred language
Improvements
- On external status pages, to avoid ambiguity we now show time zone info in the list of updates for an incident
- Announcement settings are now in the 'respond' section of settings, where they belong
- You can now use a catalog entry's external ID when setting custom fields via the public API
- Cancelled incidents will be removed from internal status page reporting
- Policy descriptions are now preset in the Slack channel post
- Workflow expressions have a better UI to handle default If/Else statements
- Adding private incident types to your announcement rule will show you a warning notification
- Improved the warning when attempting to merge triage incidents when there are no active incidents
- Users assigned to roles in retrospective incidents will be added to the channel automatically
- Display what incident modes a workflow runs on from the expanded view
- Add a StartsWith operator to workflow text evaluation
Bug fixes
- When a policy was linked to an archived channel, it would crash the page on load. Now it shows the channel as "archived"
- Custom field options will be truncated to 50 characters in the dashboard and inform the user when approaching the limit
- When trying to mark two incidents as related, the dropdown to select the related incident would sometimes be empty
- Viewing the component settings for status pages was very slow for pages with a lot of components. It's now blazing fast.
- In the workflow builder, the 'triage' status category was not available, even if you had triage enabled. Now it is!
- Allow alerts to create private incidents if the incident type is private-only
- Fix advanced settings displaying the incorrect state
- Custom field in post-incident flow not working
- Pinning in a retro incident now adds the item to the incident timeline
- Round up status page view spike multiples so that we represent 1.8X as 2X (rather than 1X)
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


