Why we built our own AI tooling suite


At incident.io our number one priority is pace. We’ve built our culture around shipping great, quality product, as fast as possible and iterating quickly based on feedback.
Our first generation of AI features were tightly focused and effective - each one solving a specific problem with carefully crafted prompts. We built some lightweight internal tooling to support these efforts, which has helped us maintain a high quality user experience.
Towards the end of last year, we embarked on something much more ambitious: creating an AI agent that will investigate, triage, and help resolve your incidents for you. It was clear that our existing tooling wasn’t suitable to build something so complex, missing things like an eval suite, graders, scorecards, and many other key tools.
With dozens of AI tooling startups popping up every week, the obvious choice might have been to buy a product off-the-shelf to get started quickly. There’s some great tools out there like Galileo and Braintrust that are building a lot of momentum in the space.
In general, we’re a team that actively prefers to buy software than build it, so we can focus our efforts on building an excellent product. But for our AI tooling, we took a different path.
Here's why we made that choice, what we built, and why it turned out to be the right call for us.
What does good look like?
As a team, we’d never built AI products like this before, which presented a challenge: how could we know what “good” looked like?
If we bought a tool, we’d have to trust their marketing in lieu of our own experience, and any tool would come with a feature-set we’d feel inclined to use, even if those features were a poor fit for us.
The last thing we wanted was to unknowingly adopt a product built for a team/context very different from our own, especially if it meant we’d skip the hard work required to learn the problems in AI engineering from first principles.
Instead, we decided to keep things simple and build tools only once we really understood what problem we wanted to solve. We kept the bar to invest low, but leveraged our expertise building developer tools and familiarity in our codebase to iterate quickly. We created a toolchain designed exactly for our team and problem, every piece created for a key purpose we understood well.
Introducing: Workbench
The result was Workbench - our internal AI tooling suite.
Here are a few highlights:
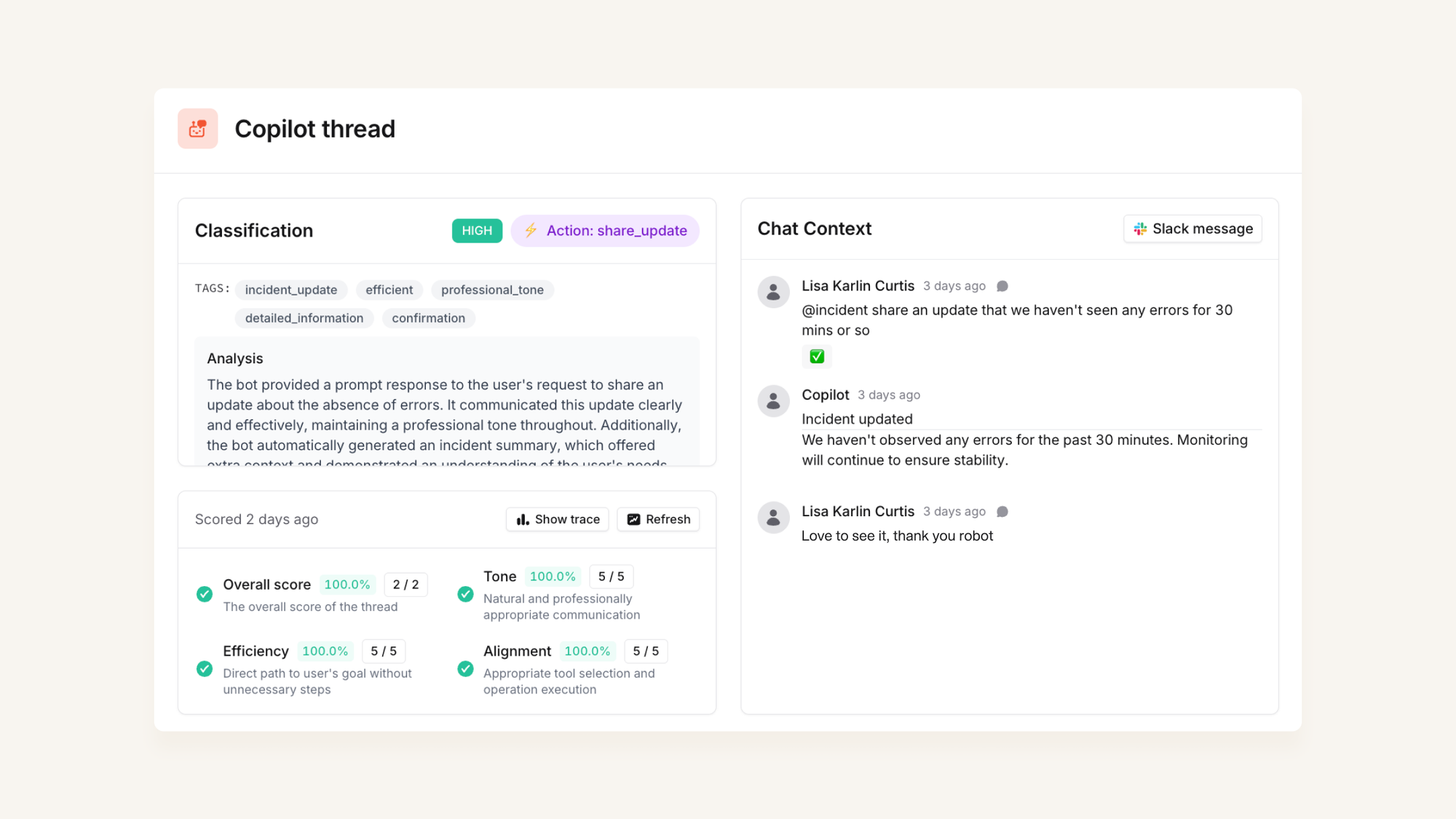
Thread explorer
When someone interacts with us via @incident, we run some further LLM prompts to classify and score the interaction.
We can then review each interaction in workbench, alongside our classification and scorecard. We also include extra context around the interaction so we can see if the user provided any relevant feedback in the thread (e.g. ‘thank-you’ or ‘argh that’s not what I meant’).
This means we can quickly assess the quality of the interaction, and also validate that our automated classification and scoring is working as expected.
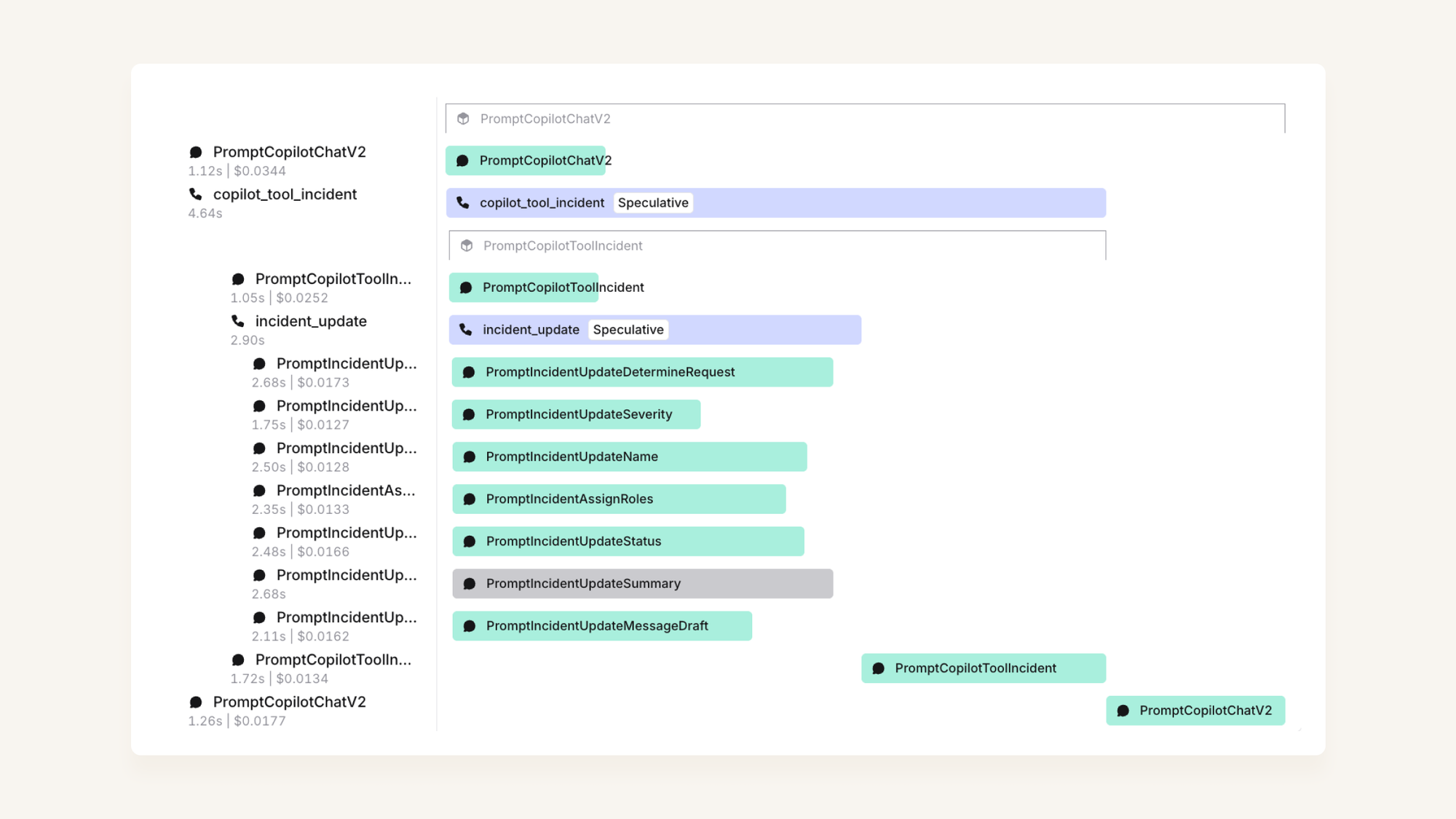
At the bottom of the page we have a….
Trace view
We use this trace view to show us the series of prompts that were run to power a given interaction, enabling us to debug more complex examples: you can easily see what path our interaction took through our prompt tree, and any errors that we encounter come up clearly in red.
You can also click on each bar to see the inputs and outputs of that particular request, and re-run the request in question to see if the outcome is consistent.
We can also understand how each prompt is contributing to the latency of a given interaction (e.g. in this case, we can see that our speculative tool calling has saved us about 2s of latency).
We've written about using speculative tool calls to reduce interaction latency.
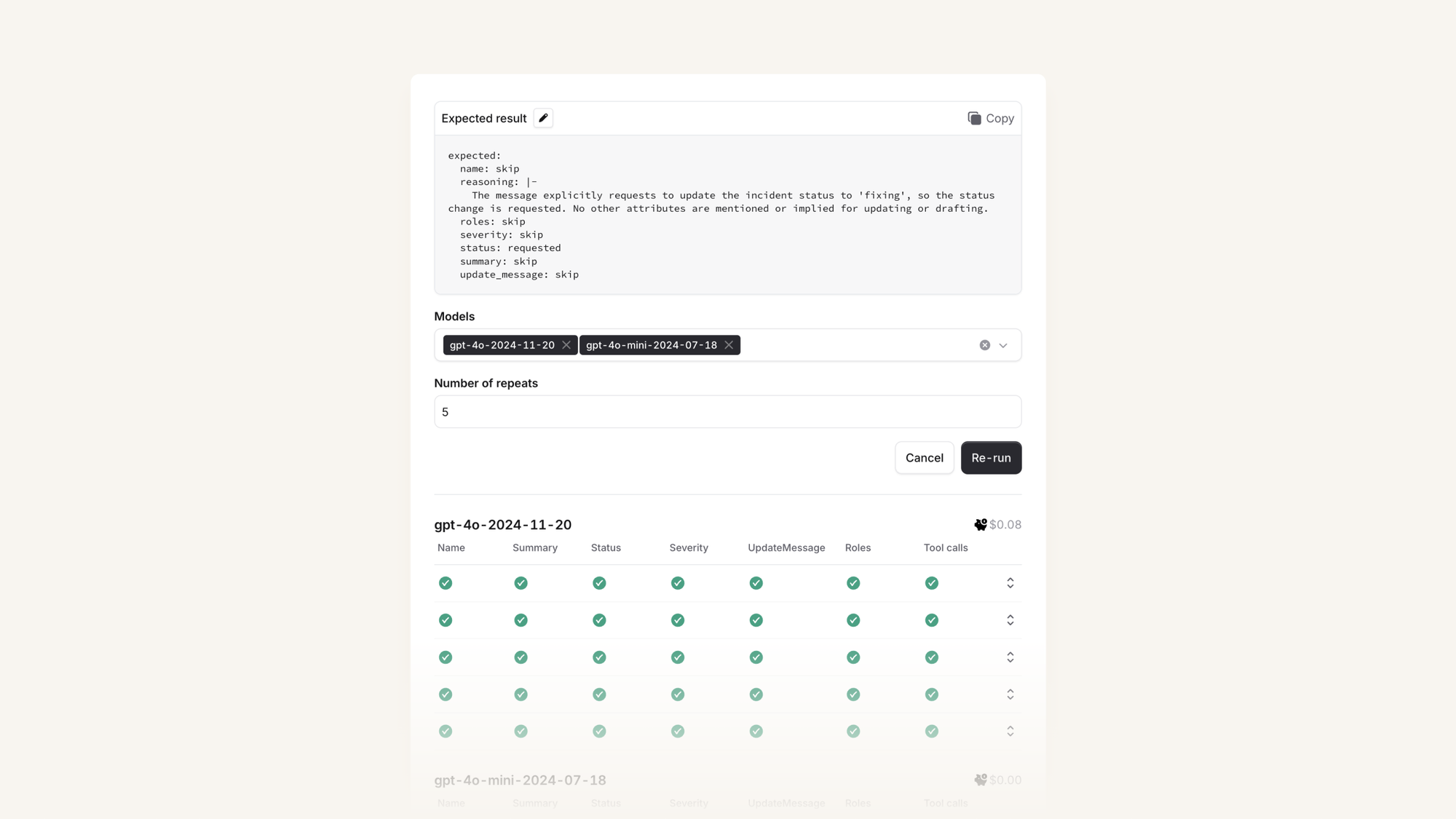
Prompt leaderboard
LLMs are, by definition, non deterministic. If you have a specific LLM request which has returned an unexpected result, it’s useful to be able to re-run it a few times to see if it's an easily reproducible failure case, or an unpredictable one.
When you run a request a few times against the same model, you can get a feel for whether the failure rate is more like 1%, 10% or 100% (provided you avoid receiving a cached result).
You can also use this to test a request against a variety of models: perhaps this is a task that Sonnet 3.7 performs better on? Or have we used a mini model where in fact, the task is just too complex.
This UI feels like a natural extension of our product, because it is. We built it using the same components, design system and principles we use throughout the rest of our application.
Key benefits
Obviously there is a trade-off here, in that building these tools is not free: it does take time away from building customer-facing product. For us, the decision has resulted in some significant advantages:
Development speed
Workbench is compiled alongside our production code and uses all the same build and deploy tooling as our primary codebase, as well all our frontend components and backend helpers.
That means we can iterate really fast. We’ve invested a lot in our developer experience, with building blocks that we use every day to develop APIs, forms and UIs. From day 1, we’ve prioritised laying rails that enable us to ship high quality product at pace, and this is no exception.
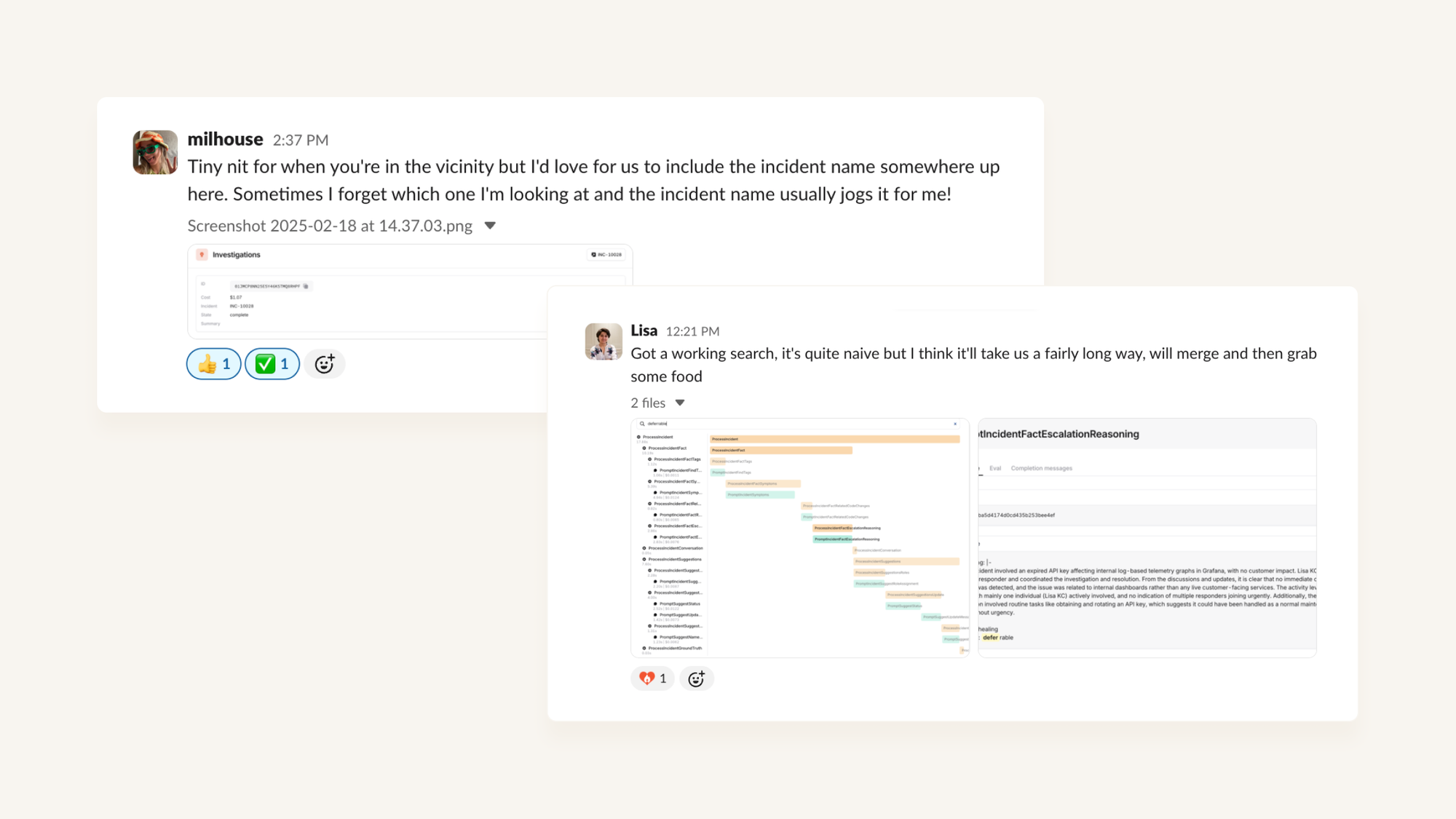
Building ourselves means we can build tooling that’s bespoke to our specific problem set - for example, to help us understand the performance of searches, or view Slack emoji reactions.
What starts as an idea at a morning standup can be in production by lunchtime, and we can smooth off any rough edges as we go.
When we’re working on AI features, our engineers are spending most of their day in our internal tooling, evaluating our results and identifying opportunities to improve our performance on a particular task.
Taking as much friction as we can out of that process means we can move even faster, and spend more time thinking deeply about how to improve the product.
Deep integration with our product
Building this alongside our product gives us a ‘single pane of glass’ where we can see all the information we need, without constantly context-switching between different tools. We can view the outcome of an investigation (the artefacts we produced, the code changes we identified) right alongside the LLM calls that we made to get there.
We can also reuse components across our product: for example, to view our investigation results alongside all the other context we’re used to seeing for an incident.
Here, we use our incident filtering APIs to help us divide a dataset into segments, based on properties about the incidents in question.
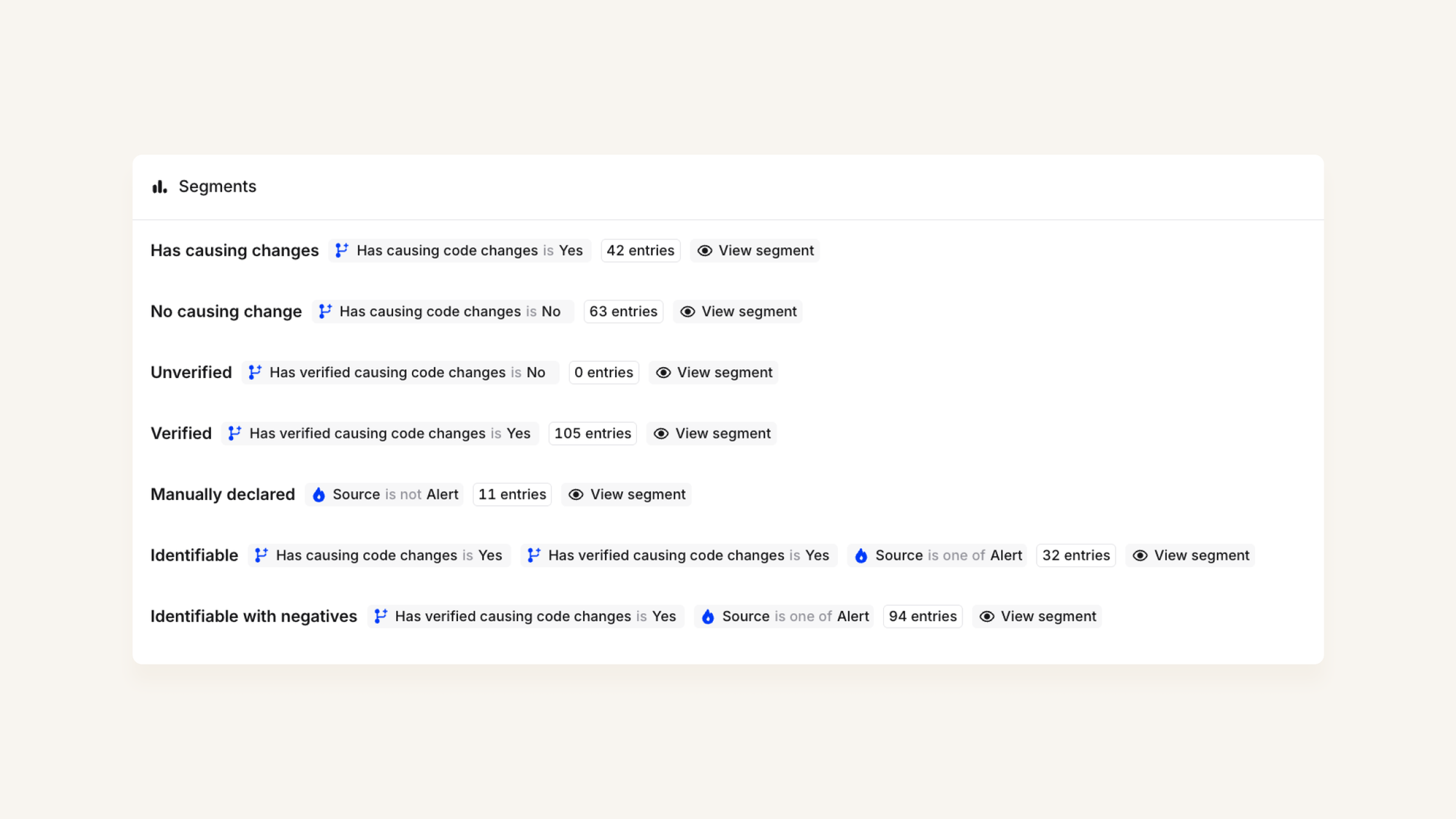
Having the data colocated also makes analysis easier: we can easily build dashboards that join product data with our AI-specific metadata (e.g. scorecards, costs and latency). That helps us do spend analysis and forecasting, as well as being able to report on aggregated scorecards over time.
Data Security & Management
As an incident company, our customers trust us with their most sensitive data. The importance of never breaking that trust impacts everything we do.
AI products like Investigations depend on having deep access to customer systems. The agent analyzes source code to pinpoint what broke, reaches into Grafana to interpret telemetry data, and connects dots across disparate systems. This level of access is what makes our AI tools genuinely useful during critical incidents but it's also something we take incredibly seriously.
So when we asked ourselves, "where would we be comfortable storing all this sensitive customer data that we feed into LLMs?" our answer was simple: nowhere. We already have additional legal agreements with our AI sub-processors for zero-data-retention and we've put a lot of time into thinking hard about the security model of our existing infrastructure.
Building our tooling internally gave us:
- Total control over data handling, with nothing leaving our infrastructure (other than the LLM call itself)
- Reduced attack surface - fewer systems means fewer potential vulnerabilities
- The ability to leverage our existing auditing and security protections
- Fine-grained permission controls we'd already built for our product
We can also treat different data types with appropriate sensitivity levels. For example, scorecard analytics might have broader internal access than actual incident content with customer data. We simply plugged into our existing security model rather than creating parallel systems with new risks.
In the end, this wasn't just about technical advantages - it was about maintaining the core trust that our entire business depends on.
Try before you buy
It’s very possible that we’ll want to expose some of the internal tooling we’ve built into customer-facing UIs to develop trust in our AI products. You can imagine a screen that shows how often our investigations agent is finding the correct causing code change for recent incidents.
Chris (our CPO) has written about the difficulty of evaluating AI products: things that look very exciting on the surface don’t always perform well when faced with your specific data or context.
Using our LLM-backed evaluation suite, we can analyze the performance of our investigations system on customer accounts, without ever giving our own staff access to any of the data underneath.
This privacy-preserving approach allows us to surface specific performance indicators to customers (like correctly identifying causing code changes) while aggregating results across accounts for our own monitoring.
Being able to demonstrate how our product would have behaved on previous incidents, and allowing customers to confirm what the ‘correct’ answer was in a given scenario, could become an important part of onboarding new customers onto new products.
Key Takeaways
In general, we’d still always rather buy something great than build something that isn’t our core product. But in this case, building our own AI tooling turned out to be a great call. Here's what we've learned:
- Building tooling clarifies requirements - We didn't know what we needed until we started building it. Rather than guessing at requirements from a vendor's feature list, we discovered them organically as we progressed.
- Short feedback loops accelerate learning - Workbench let us go from idea to production in hours, giving us more "shots on goal" and faster iterations.
- The tight integration with our product is a game-changer - Having our AI tooling built on the same foundation as the rest of incident.io reduced friction and let us iterate at the pace we needed.
Building Workbench was definitely the right choice for us. If you're just starting your AI journey and have an existing and complex product, the build approach might be worth considering.
That said, I don't think we've built the next AI tooling startup here - what we've created is very incident.io specific, and that's exactly why it was worth building in the first place.
More articles

Weaving AI into the fabric of incident.io
How incident.io became an AI-native company — building reliable AI for reliability itself, and transforming how teams manage and resolve incidents.
 Pete Hamilton
Pete Hamilton
The timeline to fully automated incident response
AI is rapidly transforming incident response, automating manual tasks, and helping engineers tackle incidents faster and more effectively. We're building the future of incident management, starting with tools like Scribe for real-time summaries and Investigations to pinpoint root causes instantly. Here's a deep dive into our vision.
 Ed Dean
Ed Dean
Avoiding the ironies of automation
Incidents happen when the normal playbook fails—so why would we let AI run them solo? Inspired by Bainbridge’s Ironies of automation, this post unpacks how AI can go wrong in high-stakes situations, and shares the principles guiding our approach to building tools that make humans sharper, not sidelined.
 Chris Evans
Chris Evans
Join our team – we’re hiring!
Join the ambitious team helping companies move fast when they break things.
See open roles