Running projects for AI features
January 23, 2024 — 6 min read

We have been busy cooking up some AI powered features these last few months and are excited to launch them this week!
This blog post aims to highlight the differences we’ve felt when running projects for AI heavy features relative to our usual ways of working.
Experimental approach
Going into these projects, we were often unsure whether LLMs like OpenAI’s GPTs were capable of what we wanted it to do. For example, would a feature like suggested follow-ups be able to spot what constitutes a follow-up? Would it be overeager to suggest one? Does it produce good results consistently?
By starting projects like these with an experimental approach, we focus on proving that we are able to produce great results consistently for customers to gain value. This also gives us clear points where we can ask ourselves whether we should continue, rethink the approach, or "park it" and focus on something with a better ROI.
We will cover a few ways to implement this approach in the next section. For a concrete example, head over to see lessons learnt when building suggested summaries.
Proof of concept
Starting with a proof of concept, we want to get as quickly to a world where we understand what GPT is capable of and how it could be incorporated with the bigger picture of the feature (i.e. how users will interact with it).
With speed being crucial, quick iteration cycles will quickly pay for themselves. For example, we built a command to test prompt changes quickly using a historical dataset and see if that improves the output.
See how we're transforming the way you learn from incidents with AI
Although we may have an idea of what the feature would look like at this stage, we often intentionally do not build a UI until later. We want to make sure we fully focus on understanding what is possible with LLMs.
Start the dogfooding early
Once we are confident that the approach will yield acceptable results, we want to build an early MVP that we can start using for ourselves in production.
This version is intentionally unpolished, but will be something that we can extrapolate to understand what the final version will feel like. An example of this is when we were building an AI Assistant to help understand historical incident data. This helped us answer some questions, as well as uncover some unknown unknowns:
- What the acceptable latency for responses should be
- The types of questions that the Assistant handles well out of the box
- That we need to find an appropriate place for the Assistant to live within our dashboard, which customers expect
By getting it into production for the rest of the company (a.k.a. dogfooding), we make an incremental step of seeing what people expect from the feature. We also gain more valuable feedback, which will help guide you towards a better solution before you spend a lot of time building everything else.
🛑 Stop refining the prompts
The key part of iterating on AI-heavy features that are powered by an LLM is refining the system and user prompts that are passed into it. We have a separate technical guide here on prompt engineering but wanted to touch on an easy mistake to make that would cost you a lot of time: not knowing when to stop refining the prompts.
Don’t let an imperfect prompt stop you from releasing to a wider (but still small) audience because this will stop you from getting a lot of valuable feedback early. Feedback will also most likely lead to changes in your prompt, so spending lots of time to perfect it may not be a worthwhile endeavour.
Here’s a few indicators where it's probably time to stop refining the prompt:
- Customers would find the feature useful even in an imperfect state
- When you’ve hit the point of diminishing returns, i.e. the additional time spent working on returns a minimal improvement
If your prompt only yields good results in certain scenarios, consider skipping your feature when you know it’ll perform poorly. This might be easier than refining the prompt to handle all scenarios. An example of this was our feature that surfaces related incidents during a live incident, and we explicitly excluded incidents with minimal information (such as declined incidents) to avoid showing false positives.
Customer Feedback
Once it's in the wild, it is important to understand how your feature is working. Establishing a feedback loop for an AI-heavy feature is an easy and high signal way of knowing how customers are using the tool and how you could improve it. Here’s some of the ways we have built this feedback loop.
- Customer calls with design partners — we use these to show customers early versions of the feature to get feedback early. Having access to customers' unfiltered feedback removes a huge barrier especially when it's something that's harder to describe like how the feature feels.
- #ai-pulse Slack channel — each time one of our AI features is interacted with, we post a message in a Slack channel that the team has access to.
- Analytics dashboards — allows the team to see at a glance how the feature is performing. This includes things like:
- Response times from OpenAI
- Acceptance/Rejection rates of suggestions by customers
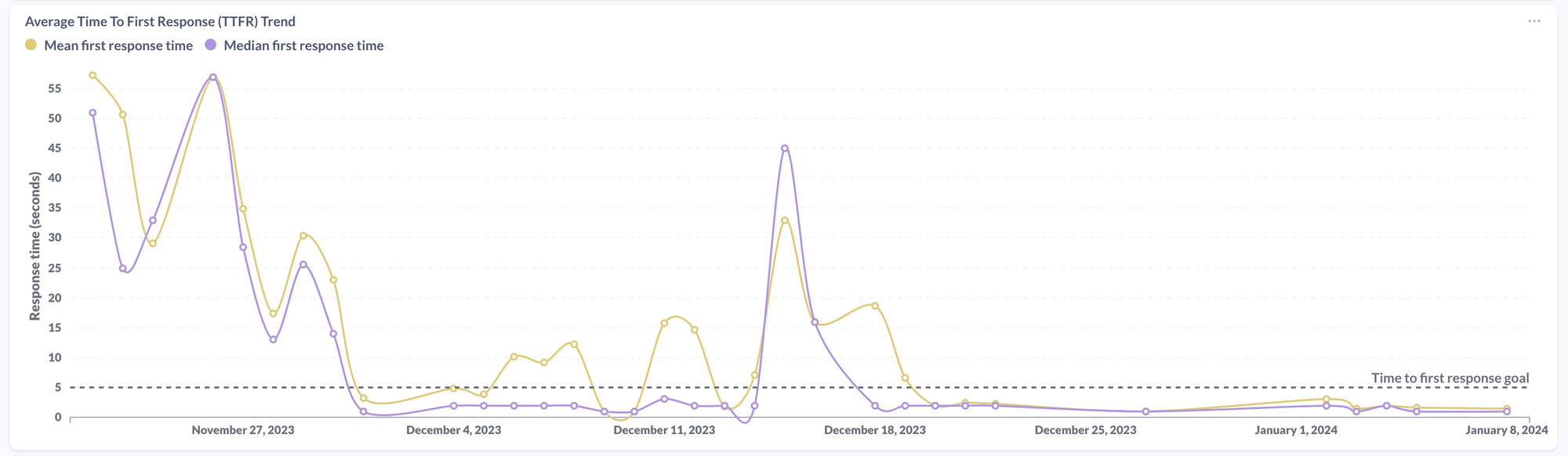
Leave some time to let feedback come through, which you can distill into actionable changes that you can make to improve the feature. Rinse and repeat and watch your graphs go up (or down)!
Summary
Overall, there are few key differences to note when running projects that involve AI heavy features.
- Adopt an experimental approach at the start to understand the limitations and adapt 🧪
- Start dogfooding as early as you can and find out the use cases that work well 🐶
- Be aware of the trap of over-refining your prompt ⏰
- Introduce a feedback loop to see how it is used in the real world 🔁
- Distill the feedback and use that to improve the feature 📈

Aaron Sheah
Product Engineer
See related articles

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025

My first three months at incident.io
Hear from Edd - one of our recent joiners in the On-Call team - how have they found their first three months and what's it been like working here.
 Edd Sowden
Edd SowdenSeptember 1, 2025