Lessons learned from building our first AI product
January 17, 2024 — 15 min read

Since the advent of ChatGPT, companies have been racing to build AI features into their product. Previously, if you wanted AI features you needed to hire a team of specialists to build machine learning models in-house. But now that OpenAI’s models are an API call away, the investment required to build shiny AI has never been lower.
We were one of those companies. Here’s our journey to building our first AI feature, and some practical advice if you’ll be doing the same.
Our first AI feature
When ChatGPT launched, we started identifying all the ways that AI could create smarter product experiences for our customers.
For context, incident.io is an incident management tool which helps organizations collaborate when responding to incidents. A key part of any incident is the summary, which is the first thing newcomers read when getting up to speed. However, keeping that summary fresh proves to be a pain point for responders who are usually zoned in on mitigating the issue.
See how we're transforming the way you learn from incidents with AI
In early 2023 one of our founding engineers, Lawrence, wrote a prototype to summarize an incident using all the updates, the Slack conversation and other metadata (the exact prompt we used is in the appendix). Even with a simple prompt we could see that this approach works, it would just need some love to make it usable (which turns out to be easier said than done - more on that later).
Once we started seeing OpenAI make big improvements to their model’s performance and reliability, we decided to invest some time into understanding what a native experience would look like and building this from the ground up.
I led this project and worked closely with another engineer and data analyst to scope and build a working version in five days. I have a background in machine learning, and specifically left the industry to enjoy the more predictable progress that comes with pure software engineering. Finding myself back in the same place had some very real irony to it.
We came up with: suggested summaries. This feature means that whenever you provide an update (which is a message about “what’s happening” that gets broadcasted to the incident Slack channel), we’ll use OpenAI’s models to suggest a new summary of the incident.
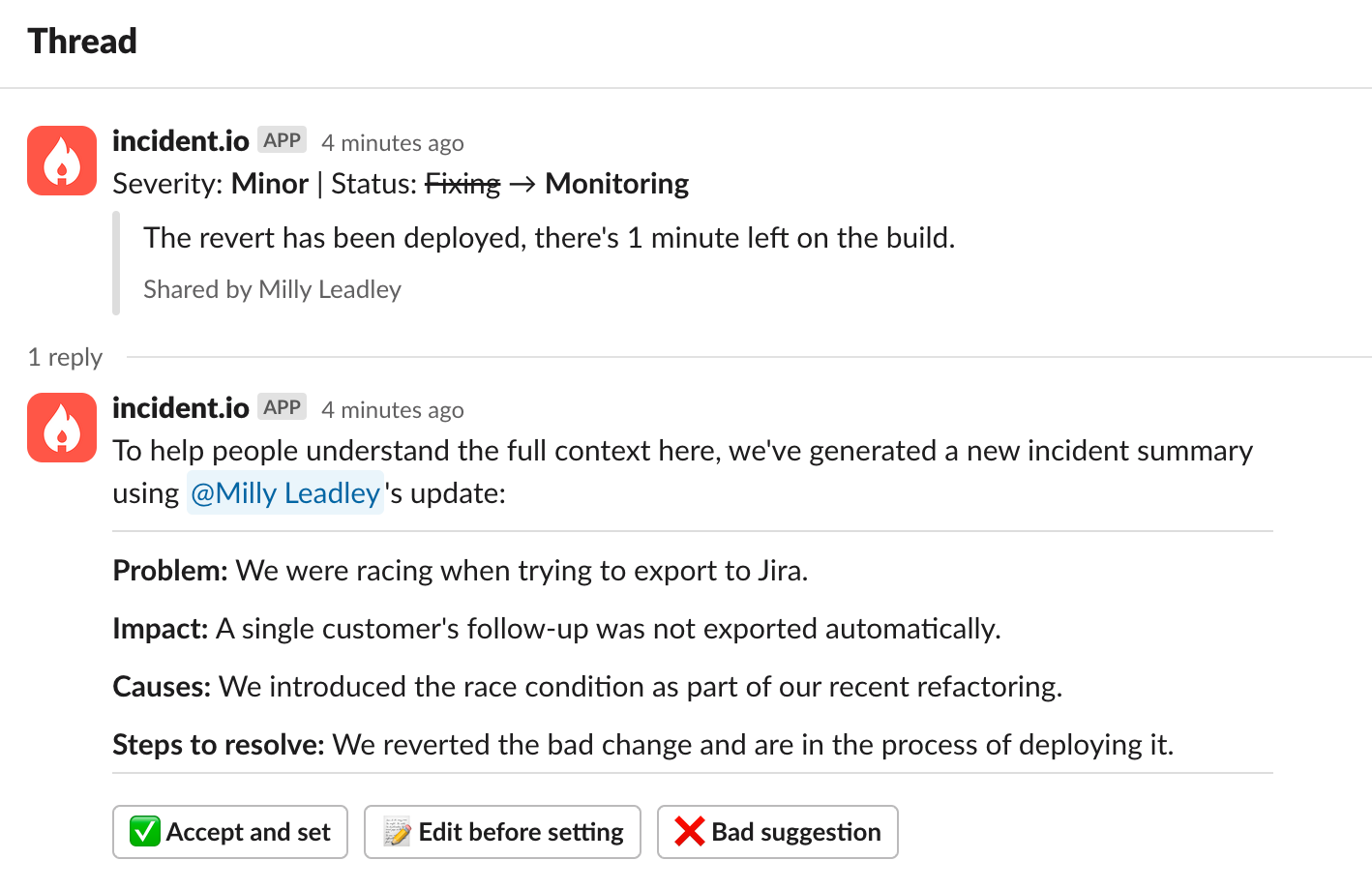
This suggestion will consider your update, the conversation in the channel, and the previous summary (if there was one). You can choose to accept it as-is or apply some tweaks first. This gives people the benefit of an up-to-date incident summary with loads of time saved. We launched it to all our customers in November, and the reaction was better than we could have hoped for.
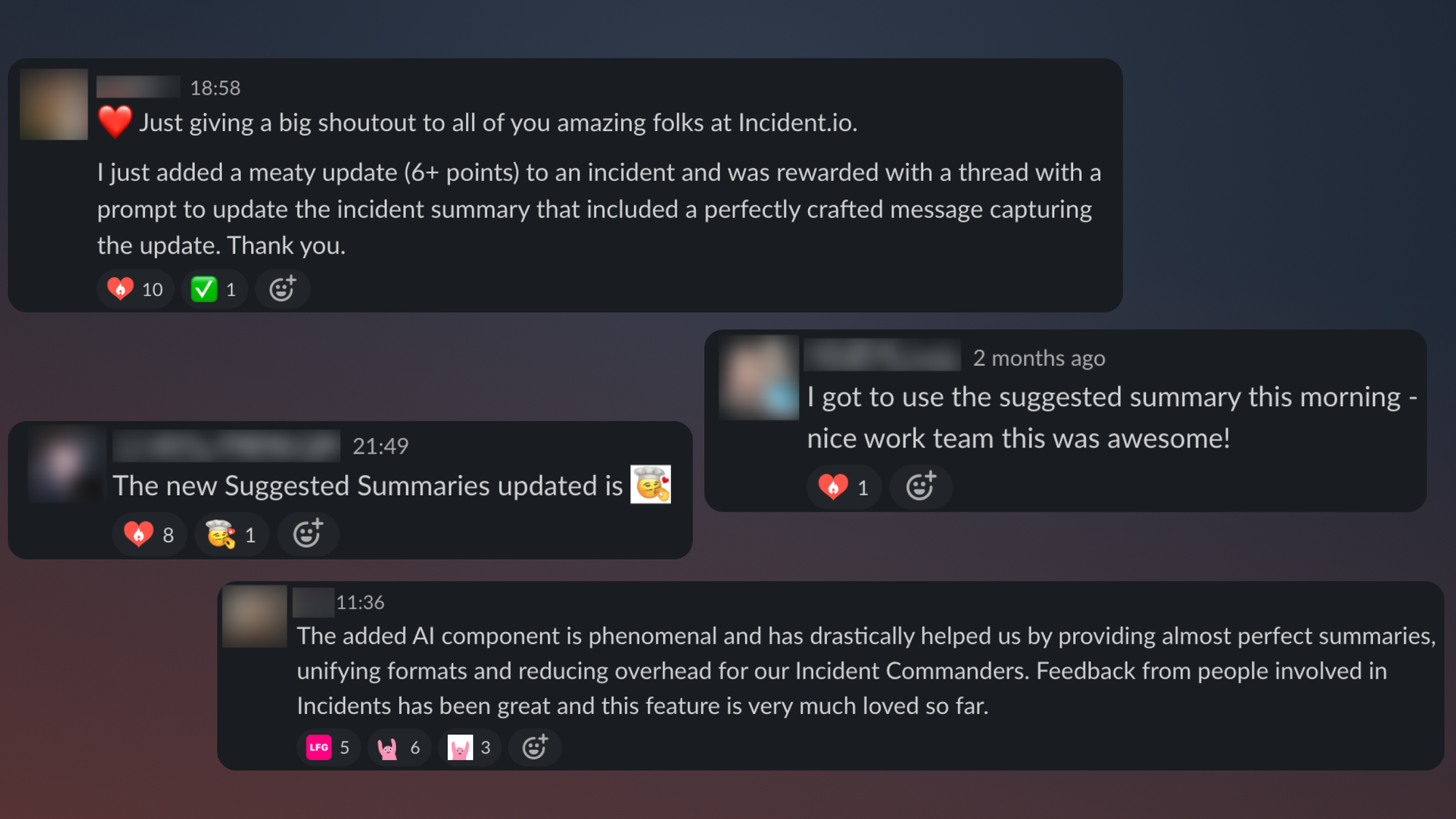
Half of all summary updates are now written by AI, and we’ve had lots of requests for similar functionality across our product.
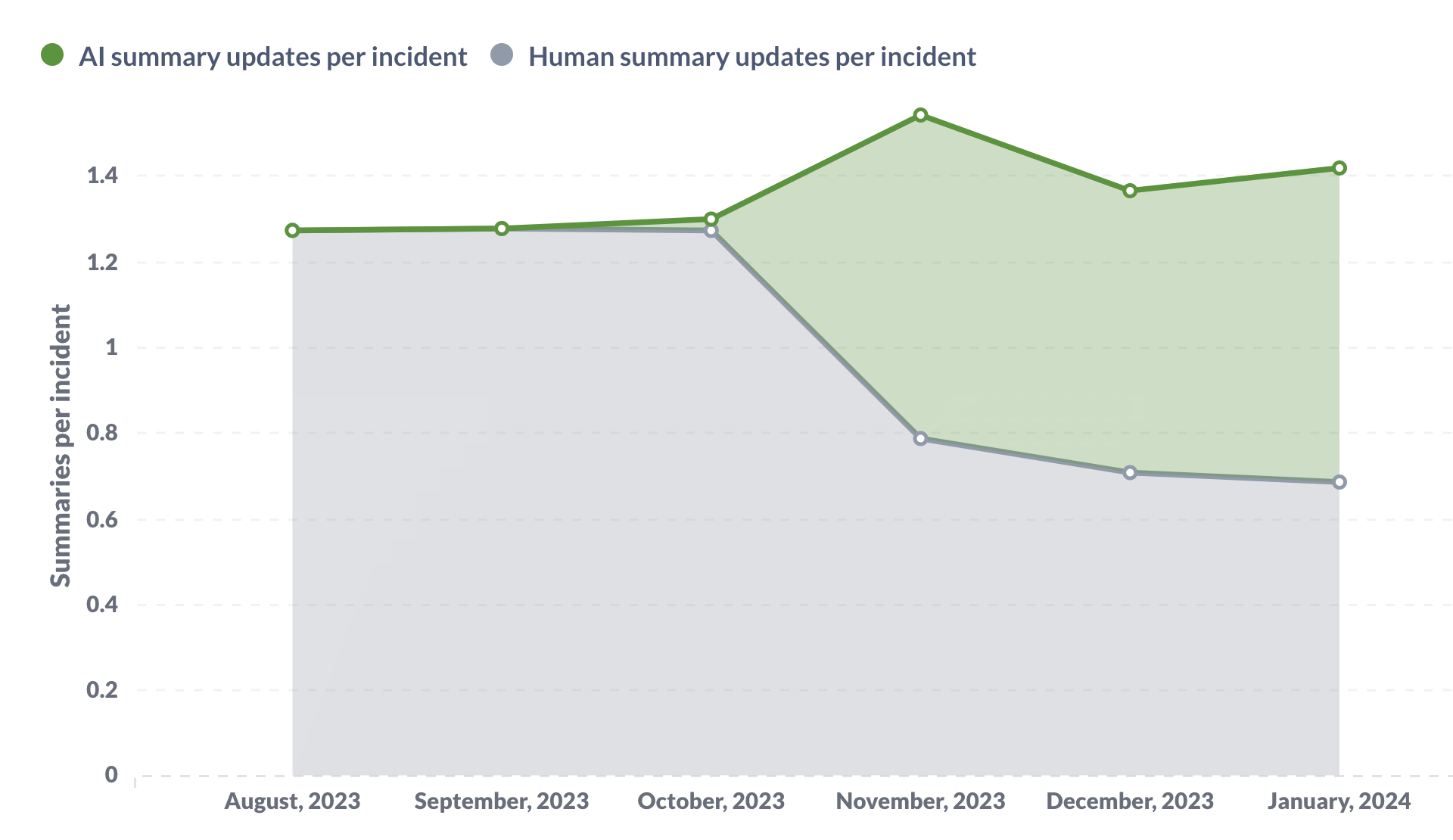
So… what did we learn?
Humans know best
When we first started scoping this project, there was some debate about whether we should either:
- (A) Propose a new summary and ask a human to accept or reject it
- (B) Automatically update the summary but give a human the option to undo this
Previously, it was rare for a summary to be updated mid-incident - it would usually be set when the incident was declared, and then modified when the incident was resolved. Therefore some of our engineers had strong opinions that we should go ahead and automatically update the summary (option B), because a fresh summary with potential inaccuracies would be better than a stale one.
However, our experience with AI features in other products is that when AI does something unhelpful, the knee-jerk reaction is to start ignoring all AI suggestions or to turn it off completely (and in fact, we did see some of this “rage against the machine” behavior when our feature was in early access and yet to prove it’s worth!).
We’d rather make AI seem like your helpful side-kick rather than force you into a bad position that you need to clean up... at least until we have enough signal that auto-setting would be more valuable. This is one of the reasons we wanted to have explicit feedback buttons on every suggestion:
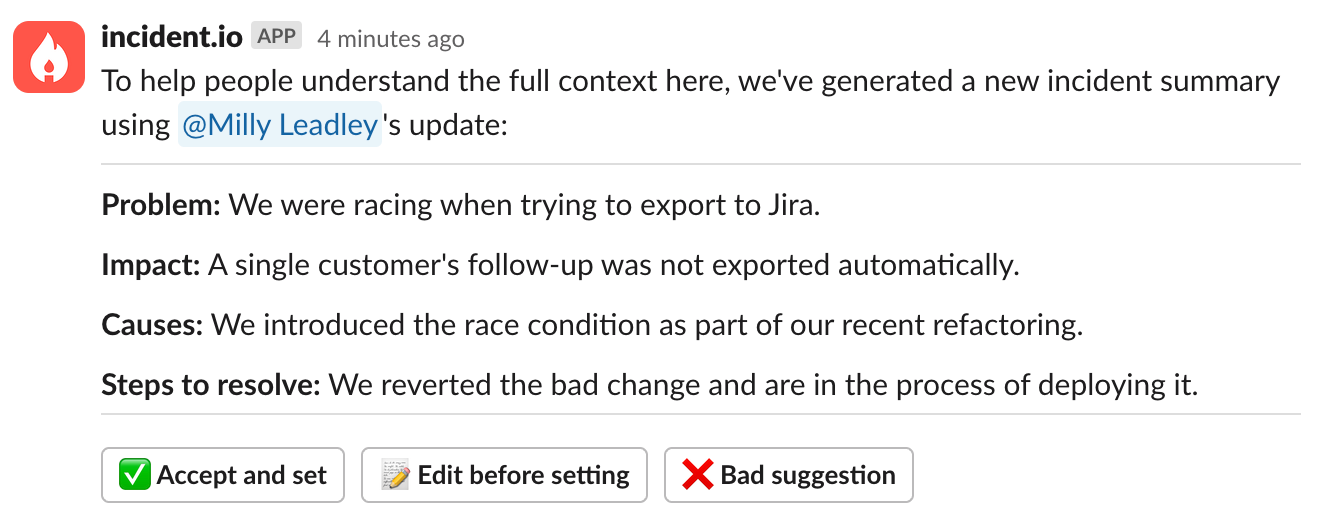
The first two buttons let the user accept/edit the suggestion, but the third button of Bad sugggestion is purely so we can track how often we were unhelpful. Not only did this mean we could track % acceptance / rejection and see ourselves improving, but it also meant we could justify changes to the flow.
For example, at the time of writing:
- When we suggest a summary, it gets actioned (i.e. a button is clicked) 20% of the time
- When a summary is actioned:
- 63% of the time it is accepted ✅
- 26% of the time it is edited 📝
- 11% of the time it is rejected ❌
This means we don’t yet have high enough conviction to auto-set the summary every time, because the majority of suggestions are not used, but we might want to consider changing the flow to make our suggestions more visible (rather than being hidden in a thread).
Prompt engineering is hard
Engineers build logical infrastructure. When something doesn’t work, there’s usually a logical reason behind it. But to make your results from OpenAI better, you need to improve the prompt which is the thing you ask GPT to do. This process is both a science and an art.
There are a few guides out there to help with prompt engineering (like this one from OpenAI), but the main thing we learned is that you need to get comfortable with trial and error. A lot of the techniques listed online made no difference for us, but small rephrasing made a huge difference.
So it’s case of throwing stuff at the wall and seeing what sticks. To make this process less painful you can do a few things.
(1) Invest in tooling
Once we realized that “improving the prompt” wasn’t a straightforward task, we hacked together a command line tool for running our prompt against fixture files. Each fixture file is a JSON which contains all the data for a real-life incident, and is referenced as a particular type of test case.
For example, we wanted to make sure we could generate a reasonable summary when:
- An incident is new, so there isn’t much data to go on yet
- An incident has been going for a long time, so there’s thousands of messages that GPT has to extract the useful information from
So we found some real-life examples (i.e. our personal incidents, not our customers’) for each of these scenarios, and outlined them like so:
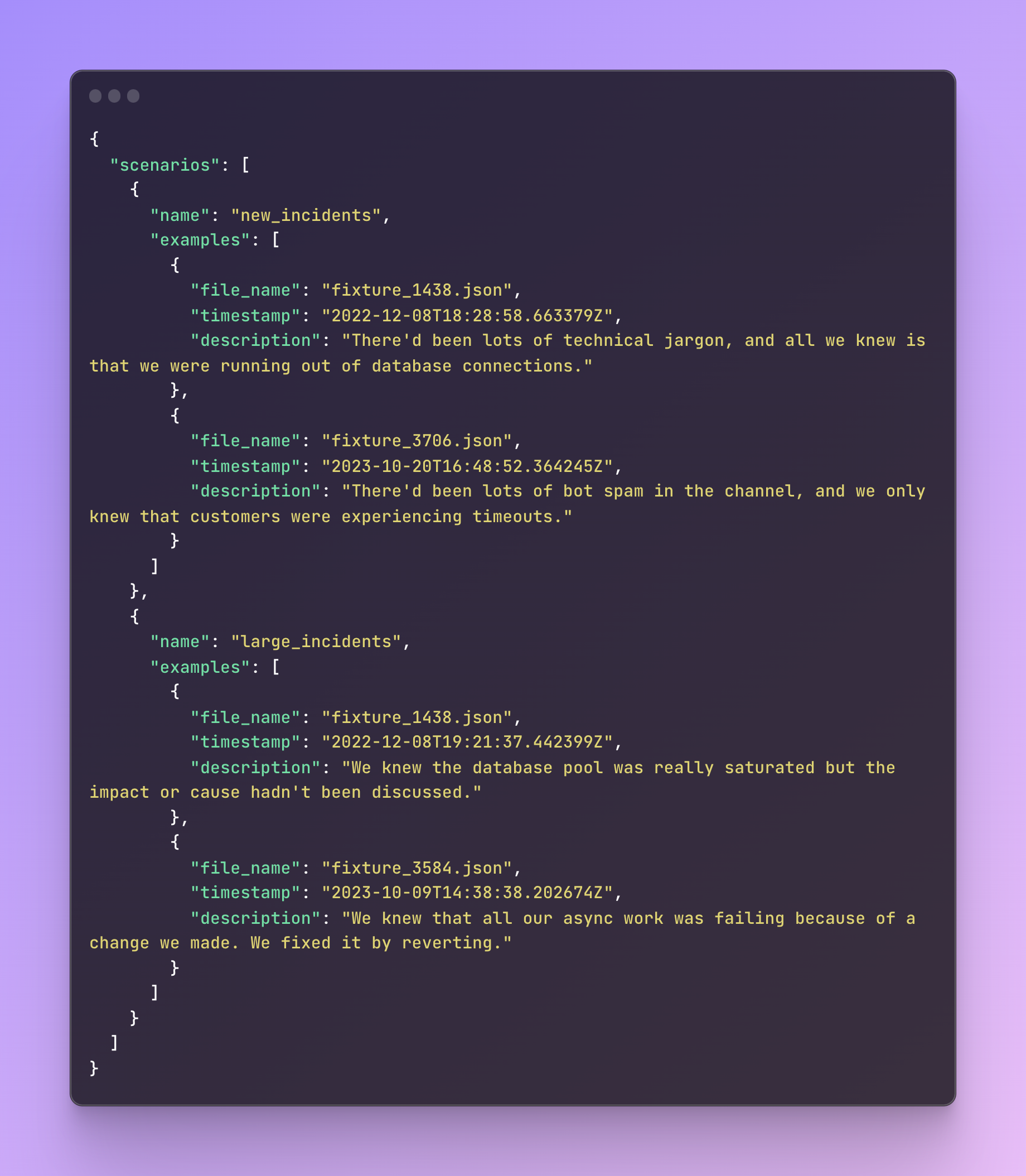
Note that the timestamp is the point in time we want to test generating a summary for that incident, which means that any data in the fixture file that came after this timestamp will be filtered out.
By having this tool, we can make GPT handle particular circumstances better by iteratively making a small change to the prompt and running it for a particular scenario, all within our development environment.
If you don’t want to build something custom, we’ve since heard that some packages exist (e.g. promptfoo, promptimize) which do a similar thing!
(2) Identify what makes a good response
This might not be relevant if you’re using a GPT model which doesn’t return free text, but one thing we struggled with was getting GPT to extract the key facts that people coming to the incident would care about, rather than just a couple of paragraphs about “what’s happened so far”.
We spent some time going through past incidents to identify what a good summary should contain and identified 4 parts. We then used the OpenAI’s JSON mode feature to force GPT to provide its response in JSON, and referenced this in our prompt:
You must return the summary in JSON format, with the following keys:
- problem (required): High level sentence explaining the problem that has caused the incident
- impact (optional): How this problem has affected customers
- causes (optional): What triggered or caused the incident
- steps_to_resolve (optional): Description of the actions that have been taken so far to resolve the incidentBy enforcing this structure, we were confident that our summaries would contain the key information in a digestible order without having to spend more time coercing GPT to do this as part of the prompt.
(3) Sequence the project thoughtfully
When we run a project at incident.io we usually write a spec of what we’re going to build, estimate how long it’ll take, build it, ship it, move onto the next project. But projects which involve AI features need to be handled differently.
Firstly, you have to factor in additional time for prompt engineering. Because of its iterative nature, we found that this isn’t very parallelizable, so it’s best having 1 person heads down on this.
Secondly, you have to accept that daily goals won’t always be met. For example, we had a ticket to Stop the model from suggesting it's own "next steps", because the model would occasionally come up with it’s own idea about what should be done next to resolve the incident. This could have taken 30 minutes to solve, but it turned out to take a day. It’s much harder to estimate workload when you’re using trial and error.
Additionally, there’ll be edge cases you won’t have thought of when you ship, so you should expect to have to circle back for more prompt engineering once your feature has been played with by a few customers. What worked well for us was: launching our feature to 10% of customers, working on something else for a week or so, then pulling out themes from the feedback at all once.
The tricky part is that the rest of the org wasn’t used to a project working like this. To manage expectations we had to be super clear in our communication to the rest of the company.
(4) Hire a specialist
…if you can. Prompt engineers are unsurprisingly becoming one of the most in-demand professions, so if you find a good one, please let us know!
Consider the requirements well in advance

If you plan on using a third party like OpenAI, you’ll need to start getting friendly with your legal team. This is because customers approve a list of sub-processors (third parties who can process their data) when they buy your product. In order to extend that list, your customers need to be notified.
We chose to email our account holders and give them a 30-day notice period in which they could object. Some of our customers had very reasonable questions such as:
- How would our data be stored within OpenAI?
- Would our data be used for model training?
- Which data will be sent?
- Will data be encrypted?
- What is the exact benefit of doing this?
You could save yourself some time by having answers ready to these questions upfront.
In the end only a couple of customers objected, partly because our answers to their questions were not alarming. OpenAI does not store data for training, and on top of that we’d negotiated a super-strict zero-data retention agreement which meant they couldn’t even store our logs (more on that here).
Aside from legal requirements you’ll also want to consider data requirements. Do you have easy access to all the data you want GPT to evaluate? For us, we had a question mark next to Slack messages. We usually enrich these on the fly by calling the Slack API (to avoid concerns about storing customer data), and we were worried that enriching hundreds of messages in a channel would take too long. This turned out to be fine because there’s a helpful endpoint for enriching the whole conversation. But if you need to start storing new pieces of data for your use case, you’ll have to consider how you store that data and whether or not you need to notify your customers.
It won’t be the last AI feature
The likelihood is that a sprinkling of AI could add magical moments across your product, no matter how small. One thing we did in this project to improve our bang for buck was to spend time building the foundations for subsequent AI features, which means we could rinse and repeat with little effort.
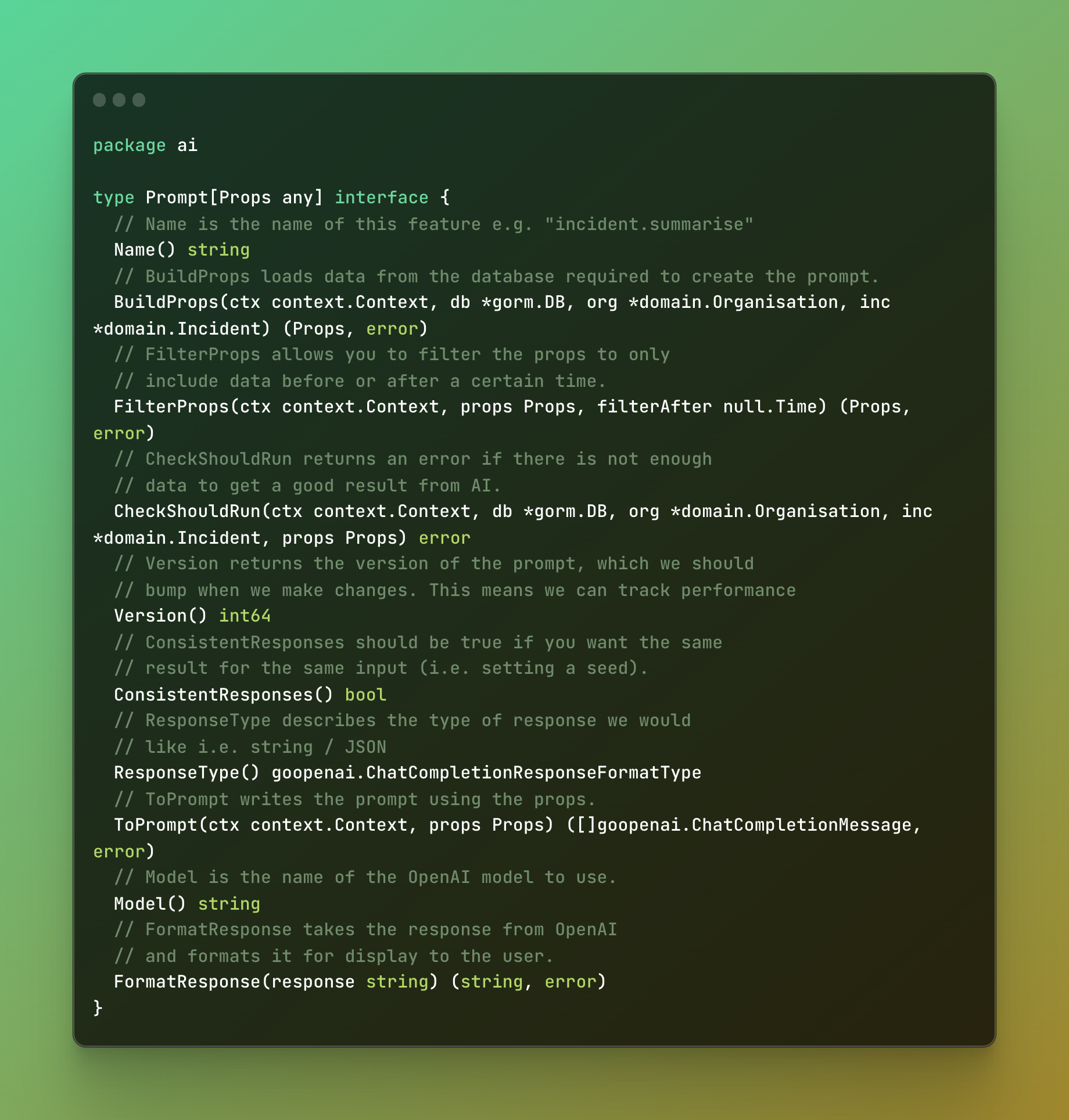
We created a dedicated directory to hold all our AI features, with an interface that each prompt must fulfill:
We then created a single entry point RunPrompt for running a prompt which:
- Checks if the customer wants this feature at all (e.g. is OpenAI a subprocessor)
- Loads the required incident data
- Decides whether or not there’s enough data to get a good result from AI
- Builds the prompt and calls OpenAI
- Stores the response and other metadata
This means that when building a new AI feature you just need to fill out the interface and call RunPrompt. The caller does not need to concern itself with any of the admin aspects of using OpenAI.
Having all of this standardized meant that when it came to building our next AI feature (suggested follow-ups) we could test it out without having to implement any front end code! We just fulfilled the interface and ran the prompt against incidents via our aforementioned command line tool. This was the easiest way to get conviction that ChatGPT was actually able to suggest useful follow-ups based on the incident data, and that the idea was worth pursuing.
If you'd like to see all the AI features we've since built, check out this post.
Summary
If you’re thinking of building AI into your product, here’s some advice I wish we’d had before embarking on our mission:
- AI should give power to humans, not the other way round 🤖
- Feedback buttons are critical ✅
- Tools can make prompt engineering much easier 🔧
- Identify what a good response should look like 🔍
- Carve out uninterrupted periods of time for prompt engineering 👨💻
- Solicit feedback from a small % of your customer base 📩
- Let the rest of your company know if the timelines look different ⏱️
- Loop in legal early 👮♂️
- Work out if you have easy access to all the data you need 🚀
- Once you’ve built the first one, subsequent AI features should be easy! ✨
This summary was human-generated.
Appendix
Prompt in the prototype
var summariseIncidentPrompt = template.Must(template.New("summariseIncidentPrompt").Funcs(sprig.TxtFuncMap()).Parse(`
Summarise the following incident, aiming for a non-technical audience:
The incident name is: {{ .Incident.Name }}
{{ if .Incident.Summary.Valid }}
The summary of the incident is currently: {{ .Incident.Summary }}
{{ else }}
Currently there is no summary provided for the incident.
{{ end }}
What follows are incident updates that have been provided, in the order they were given:
{{ range .Updates }}
At {{ .CreatedAt }} the update was: {{ .Message.String }}
{{ end }}
`))
Milly Leadley
Product Engineer
See related articles

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025

My first three months at incident.io
Hear from Edd - one of our recent joiners in the On-Call team - how have they found their first three months and what's it been like working here.
 Edd Sowden
Edd SowdenSeptember 1, 2025