Rootly limitations: when to consider alternative incident platforms
April 14, 2026 — 15 min read
Updated Apr 14, 2026
TL;DR: Rootly is a capable starter tool for small teams running simple Slack-based incidents. Its free tier gets you moving fast, but as your team grows, you'll encounter UI complexity in custom workflows, a Slack-first AI and slash command experience, and escalation policy structures that may not match complex global on-call requirements. For teams that need true Slack-native workflows, transparent pricing, and AI that automates remediation rather than providing suggestions, incident.io is a stronger long-term choice. incident.io's Pro plan runs $45/user/month ($25 base + $20 on-call add-on), all-in with no surprises at renewal.
Most Site Reliability Engineering (SRE) teams evaluating Rootly love the free tier. The Slack integration fires up quickly, incidents get created, and the UI feels approachable compared to PagerDuty's cluttered dashboard. As your team grows past a handful of on-call rotations, you need follow-the-sun schedules, deeper observability integrations, and AI that takes action on the deployment it identifies, not just surfaces it for a human to investigate.
This guide unpacks Rootly's documented limitations, compares how alternative platforms handle these workflows, and gives you the honest TCO numbers you need before signing a contract.
Rootly's role in incident management
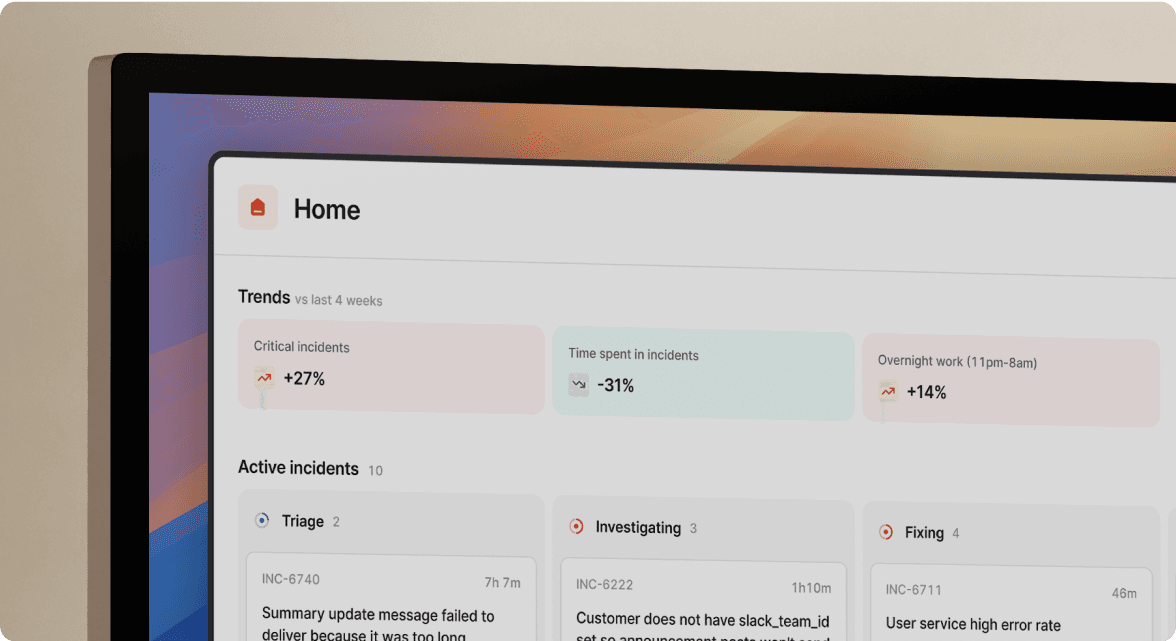
Rootly positions itself as an AI-native on-call and incident management platform built around ChatOps (managing incidents through chat platforms like Slack). Its core workflow orchestrates incident response through Slack, coordinating responders and logging activity. For teams already living in Slack, that initial experience is smooth. Rootly counts Canva and Grammarly among its customers.
Rootly's primary incident workflows
Rootly handles the basics well: incident declaration in Slack, automated channel creation, and escalation policy routing.
Rootly's specific user profile
Rootly fits teams with straightforward incident structures: a single on-call rotation, predictable alert sources, and a Slack-first culture. The challenges emerge as your incident workflows grow in complexity.
Rootly pros and cons summary
| Feature area | Strength | Limitation |
|---|---|---|
| Setup speed | Fast initial Slack integration | Complex to customize for non-standard workflows |
| AI capability | Surfaces deployment correlations and summaries | AI surfaces suggestions. Workflow engine supports automated remediation like rollbacks with custom configuration. No native fix PRs. |
| Pricing | Generous free starter plan | Scale tier reaches $420/user/year list |
| Microsoft Teams | Functional Teams integration | Slash commands and AI interactions are Slack-first |
| Integrations | Common tools covered | Fewer native integrations than some competitors |
Integration friction with existing tools
Observability blind spots in Rootly
Rootly covers the most common monitoring integrations, but depth varies. Webhooks close some of that gap, but they add engineering work that compounds at 3 AM when an incident is already in progress.
Rootly's Teams and Slack experience
While Rootly offers integrations with both Slack and Microsoft Teams, the platform's most advanced capabilities appear optimized for Slack. For organizations standardized on Teams, some workflow features may be more limited compared to what's available in the Slack integration.
Can alternatives unify your toolchain?
incident.io's Pro plan includes unlimited integrations connecting with tools like Jira, Linear, GitHub, and Confluence for exporting and syncing incident actions. For monitoring tools like Datadog, incident.io can automatically create incidents from alerts when routed through PagerDuty or OpsGenie. Once an incident is declared, incident.io creates a dedicated Slack channel and can pull in relevant context from your service catalog and recent deployments, with options to configure escalations and timeline capture to support your incident response workflow.
Opaque pricing: Unpacking Rootly's hidden fees
Rootly's true platform cost
Rootly's free starter plan is generous for small teams: unlimited incidents, post-mortems, and integrations. The cost reality changes at paid tiers, where feature availability and pricing vary considerably between plans.
Scale tier pricing jumps
Rootly's Essentials plan targets startups and growing teams. The Scale tier, designed for larger organizations, is where costs typically accelerate. According to Vendr's marketplace data, Rootly's median buyer pays $13,067 per year, with customers averaging 28% savings off list prices through negotiation. Advanced capabilities like unlimited workflow automations are gated to the Scale tier.
Pricing comparison: Rootly vs. incident.io vs. PagerDuty
| Platform | Base incident plan | Annual cost (100 users) |
|---|---|---|
| Rootly Essentials | $240/user/year | $24,000 list |
| Rootly Scale | $420/user/year | $42,000 list |
| incident.io Pro | $45/user/month | $54,000 all-in |
| PagerDuty Business | $41/user/month | $49,200 list |
Vendr data shows negotiated Rootly Scale pricing at $31,374 median for 100 users (28% savings off the $42,000 list price). Rootly's on-call pricing is not publicly listed and must be confirmed directly with their sales team.
Upfront pricing: know your TCO
incident.io's Pro plan at $45/user/month ($25 base + $20 on-call add-on) puts the full feature set on the table without negotiation. You get unlimited workflows, custom incident types, private incidents, Microsoft Teams support, AI post-mortem generation, and custom dashboards. No surprises at renewal.
AI root cause analysis: Accuracy gaps
Rootly AI's correlation logic
Rootly's AI is designed to help responders understand what's happening and decide what to do next. It scans recent pull requests and deployments to surface potential correlations with incident timing, which is useful for narrowing down where to look.
The architectural constraint is what happens after that surface. Rootly AI surfaces the suspicious deploy for a human to investigate. When you're debugging a latency spike at 3 AM, the difference between "here's a deployment that correlated with the spike, investigate it" and "here's the diff, here's a draft fix PR" is the difference between 45 minutes and 20 minutes of resolution time.
Platforms with advanced incident AI
incident.io's AI SRE can automate up to 80% of incident response. The AI SRE assistant handles investigation and automated remediation, including fix PRs, using captured incident data. Scribe transcribes Zoom and Google Meet calls directly into the incident timeline.
Operational fit for unique incident workflows
Custom on-call rotation rules
Rootly supports escalation policies for managing on-call routing. The platform's specific technical approach to policy evaluation and any hard numerical limits on escalation levels or targets per level are best confirmed directly with Rootly's team. If your organization runs complex global on-call with extensive multi-level escalation paths or numerous targets per level, verify Rootly's capabilities and any limits with their team before committing.
For teams running follow-the-sun rotations with regional ownership, multi-tier escalation from L1 to L2 to engineering manager to VP, and custom override rules, Rootly's workflow UI adds configuration overhead that compounds as rotation complexity grows.
Deep incident workflow customization
As workflow complexity grows, Rootly's opinionated structure becomes friction rather than guidance. When your team needs custom fields for deployment correlation, dynamic severity-based routing, or branching workflows tied to affected services, the UI layers multiply and configuration time increases.
Tools to overcome Rootly's limits
incident.io's Pro plan removes workflow limits entirely: unlimited workflows, unlimited custom fields, unlimited on-call schedules, and unlimited escalation paths. The AI suggested follow-ups feature helps ensure post-mortem tasks flow into Jira or Linear without manual entry. incident.io is also SOC 2 Type II certified with GDPR compliance and AES-256 encryption at rest.
Deciding on Rootly: When it fits your stack
Rootly for smaller engineering teams
If your team is small, your on-call structure is straightforward, and you're running Slack as your primary coordination layer, Rootly's free or Essentials tier covers the core workflow without budget pressure. Setup is fast, the Slack integration is functional, and for basic incident declaration and post-mortem creation, you won't hit meaningful walls.
Rootly excels in these specific use cases
- Early-stage startups: Teams that need incident structure but haven't yet developed complex multi-region escalation requirements.
- Low incident volume: Organizations where manual post-mortem effort is manageable and the free tier's workflow constraints don't create friction.
Platforms addressing Rootly's weaknesses
incident.io: Auto-capture timelines in Slack
We built our architecture to put the entire incident lifecycle inside Slack, not in a web UI that sends Slack notifications. When a Datadog alert fires, incident.io creates a dedicated channel, pages the on-call engineer, pulls service catalog context, and starts recording the timeline automatically. Responders use /inc escalate, /inc assign, and /inc resolve without opening a browser tab.
Teams using incident.io reduce Mean Time To Resolution (MTTR) by up to 80%. Favor reduced MTTR by 37% after implementing our workflow, largely by eliminating manual coordination overhead.
Verified G2 users echo this pattern:
"When we required capabilities beyond their initial scope, they didn't turn us away. Instead, they collaborated with their engineering team to develop the necessary solutions." (Michael A. on G2)
PagerDuty for enterprise compliance integrations
PagerDuty remains the established incumbent for teams that need maximum alerting customization and have the budget and engineering time to configure it. Its alert routing offers deep customization with conditional logic and sophisticated escalation policies, and its enterprise security posture is mature. The trade-off is cost (Business plan at $41/user/month, Enterprise plan on custom pricing) and a complex UI. For teams whose primary requirement is alerting depth over coordination, PagerDuty is the right choice. If you're migrating from PagerDuty, migration tools in our docs make the transition systematic.
FireHydrant: Accelerate incident resolution
FireHydrant is a peer competitor to incident.io: modern, Slack-focused, and capable. incident.io differentiates on AI capabilities (automated fix PRs versus log correlation and summaries).
Opsgenie: Mandatory migration by 2027
Opsgenie is not a viable long-term choice. Atlassian announced that Opsgenie shuts down April 2027. Any team evaluating Opsgenie today faces a mandatory migration in under two years. If you're currently on Opsgenie, we've built a dedicated Opsgenie migration path covering schedule migration, integration reconnection, and a parallel-run strategy.
Ready to reduce MTTR without adding headcount?
If your team has outgrown Rootly's workflow limits or needs AI that automates remediation rather than surfacing suggestions, incident.io is built for that. See how teams reduce MTTR by up to 80%. Schedule a demo and we'll walk through your on-call structure and integration needs.
Key terms glossary
ChatOps: Managing infrastructure operations and incident response through chat platforms like Slack or Microsoft Teams, using slash commands and bot integrations instead of separate web dashboards.
Escalation policy: A set of rules that determines who gets paged when an alert fires, and how the notification escalates through multiple tiers (primary on-call to secondary to manager) if the incident is not acknowledged within defined time windows.
Follow-the-sun rotation: An on-call schedule where responsibility shifts across time zones so teams in different regions handle incidents during their local business hours, providing 24/7 coverage without overnight shifts.
Incident commander: The person responsible for coordinating an incident response, making decisions about escalation and communication, and ensuring the timeline is captured. Also called incident lead.
MTTR (Mean Time To Resolution): The average time it takes to fully resolve a production incident from alert to resolution.
On-call rotation: The schedule determining which engineers are responsible for responding to alerts during specific shifts. Typically structured in layers with primary, secondary, and manager escalation paths.
Post-mortem: A blameless review document created after an incident to capture timelines, root causes, contributing factors, and preventative action items for the team.
Root cause analysis (RCA): The process of identifying the underlying technical or process failure that caused an incident, typically documented in the post-mortem to prevent recurrence.
Runbook: A documented set of procedures for responding to specific types of incidents or performing routine operational tasks. Often linked from service catalog entries or incident types.
Service catalog: A centralized inventory of applications, microservices, and infrastructure components, typically including ownership, dependencies, runbooks, and on-call contacts.
Severity: The classification of an incident's business impact, typically ranging from P0/SEV1 (complete outage, all hands) to P3/SEV4 (minor degradation, can wait for business hours).
Slack-native: An application architecture where the entire workflow lives inside Slack channels and slash commands, rather than requiring users to switch to a web dashboard or separate UI.
SOC 2 Type II: A security compliance certification that verifies an organization's controls for data security, availability, and confidentiality have been tested over a minimum six-month period.
SRE (Site Reliability Engineering): The discipline of applying software engineering practices to infrastructure and operations problems, focusing on automation, monitoring, incident response, and reliability improvement.
TCO (Total Cost of Ownership): The complete cost of a platform over time, including base licensing, add-on fees, implementation effort, training, and ongoing maintenance, used to compare vendor pricing beyond published list rates.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026

Engineering teams in 2027
A forward look at where engineering teams are heading with AI, based on conversations with design partners who are visibly six-to-twelve months ahead of the average. Tailored code agents, MCP gateways, agentic products that talk to each other — most of the picture is already there in pockets, and the rest of the industry is closing the gap fast.
 Lawrence Jones
Lawrence JonesMay 19, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


