Onboarding yourself as an engineer at incident.io
July 5, 2024 — 2 min read

At incident.io we use infrastructure as code for configuring everything we can, and we feel that there’s no reason we should exclude our own product from that. As well as configuring things like Google Cloud Platform, Sentry and Spacelift via our infrastructure repo, we also configure incident.io.
Onboarding with code
On your first day as an engineer here, the first PR that you make is to our infrastructure repo. This lets you know where we configure our infrastructure, shows you how it works, and lets us make sure you have access. The change you make adds you as a user:
+ user('pip', tags=['engineer', 'production']),Then adds you to your team:
{
external_id: 'catalog',
name: 'Catalog',
description: 'Responsible for the Catalog and Workflows',
members: [
'benji',
'laura',
'lisa',
'louis',
+ 'pip',
],
...
}And sets up a Spacelift stack:
+ "dev-pip" = {
+ project = "incident-io-dev-pip"
+ autodeploy = true
+ }Setting up infra
Once that PR has been reviewed and merged, a whole bunch of stuff gets set up automatically by Terraform.
A Spacelift stack is set up for your development environment to use (for things like pub/sub).
You get access to the resources in Google Cloud Platform that you’ll need to do your job (the tags your user has determine which groups you’ll be added to), and added to the correct Google Groups for your team and role. We do that by pulling in the team data from the jsonnet config file:
locals {
# Load all group configuration from the config file ($.groups)
groups = jsondecode(data.jsonnet_file.config.rendered).groups
# Flatten memberships for an easier for_each
group_memberships = flatten([
for group in local.groups : [
for member in group.members : {
group = group.id
member = member
}
]
])
}
resource "google_cloud_identity_group_membership" "groups" {
for_each = {
for ms in local.group_memberships : "${ms.group}:${ms.member}" => ms
}
group = google_cloud_identity_group.groups[each.value.group].id
preferred_member_key {
id = each.value.member
}
roles {
name = "MEMBER"
}
}Setting up incident.io
But what about incident.io? I’m going to focus on how we sync teams in to our Catalog product, but we also support Terraform for things like on-call schedules and workflows, allowing you to configure incident.io via code.
So what additional changes do you need to make to update the catalog and add yourself to your new team? Nothing! We use our Catalog Importer tool to store the data for the Team catalog type as code, and every time that code is changed, the importer is automatically run to update the catalog in incident.io:
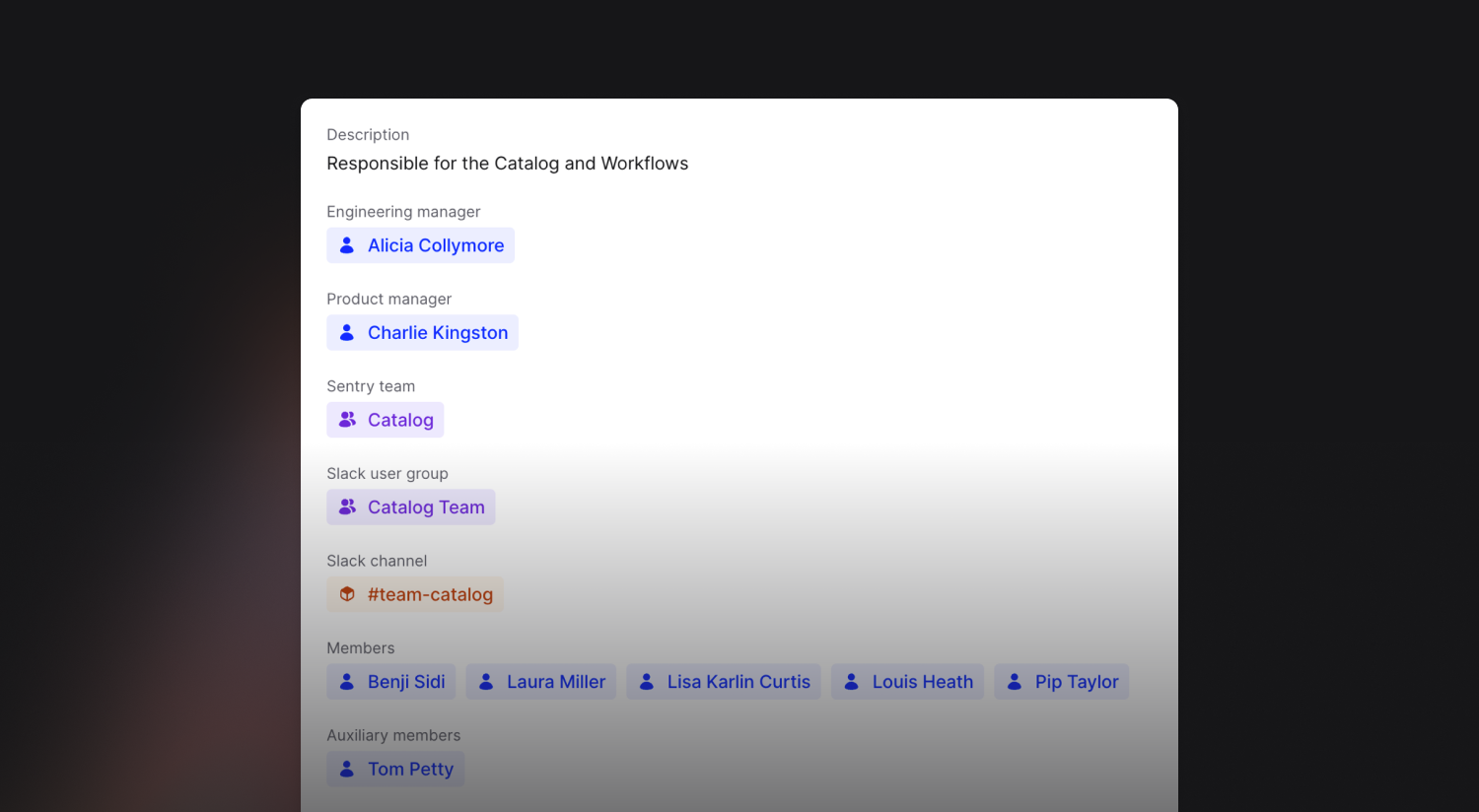
The mapping from the Jsonnet config file shown above to the Team catalog type looks like this:
{
outputs: [
{
name: 'Team',
description: 'Teams in Product Development.',
type_name: 'Custom["Team"]',
source: {
name: '$.name',
external_id: '$.external_id',
},
attributes: [
{
id: 'description',
name: 'Description',
type: 'Text',
},
{
id: 'members',
name: 'Members',
type: 'User',
array: true,
},
...
],
},
],
sources: [
{
inline: {
entries: catalog.teams,
},
},
],
}It’s best practice for us to configure our own product in the same way that we do other products. Whether it’s Google Cloud Platform, Spacelift, Sentry, or incident.io, configuration belongs in our infrastructure repo. It’s an added bonus that this makes onboarding yourself as an engineer really simple.

Pip Taylor
Product Engineer
See related articles

Don't add a read replica until you've read this
Our learnings from implementing a product-wide read replica migrations, including some useful patterns for routing queries to replica and primary
 Johanna Larsson
Johanna LarssonJuly 21, 2026

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


