My first 3 months at incident.io
August 2, 2024 — 6 min read

During my interview process with incident.io about six months ago, my future manager Jack mentioned that the Data team had been operating without a dedicated Data Engineer for the past two years. Instead, Jack and other product engineers had taken on this role.
Jack acknowledged that as the company grew, the data ecosystem was expanding as well, leading to an impending bottleneck due to the current data platform's inability to scale. This challenge alone was enough for me to join the company because I thrive on the freedom to tackle and solve technical problems.
In this post, I will highlight three areas I worked on during my first three months: enhancing our development platform, exploring various data ingestion tools and reducing the overall cost of our platform.
Development platform
Before diving into this topic, I'd like to mention that our data stack currently consists of Fivetran for data ingestion, BigQuery, dbt for transformation, CircleCI for CI and orchestration, and Omni for BI.
One of my first achievements was uploading dbt artifacts to Google Cloud Storage after each production run. If you're not familiar with dbt artifacts, they are JSON files generated during dbt runs, with the most important being the manifest, which represents the entire dbt project. Below is a quick representation the lifecycle.
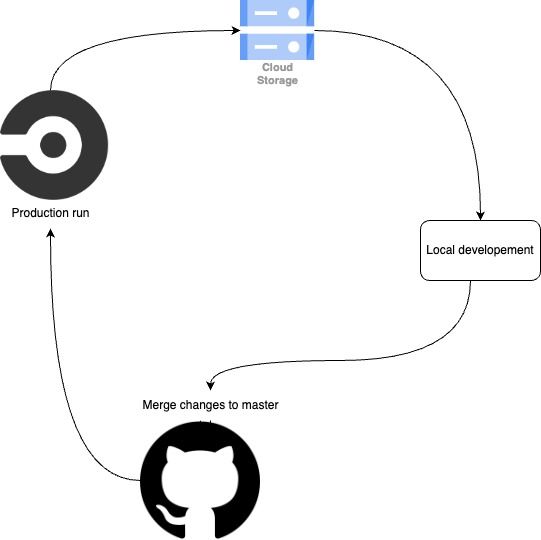
By uploading these artifacts to GCS, we can access them from anywhere, leading to two key improvements:
- dbt Development Workflow: To avoid the complicated process of rebuilding all upstream dependencies locally when making changes to a model, we now leverage dbt's native
deferfeature using the latest production manifest. This allowed us to move away from the upstream package which was complicated and messy to maintain. - dbt CI: We use dbt's
state:modifiedfeature to run only modified models and their downstream dependencies during CI, relying on the latest production manifest from GCS. Previously, we had to check out themasterbranch and compile the manifest on the fly for each job, which was slow and prone to errors if changes inmasterwere not yet deployed to production.
Another significant improvement I made was to use a custom Docker image of our dbt repository during CI and production. Running several Python scripts in these workflows made it slow and messy to set up our entire environment for each CircleCI job (e.g., running pip install ..., dbt deps, etc.).
By leveraging Docker, we now build a new image of our repo whenever a change is merged into master and push this image to our private artifact registry in GCP. We then pull this image during our production runs. During CI, we rebuild the image on the fly to incorporate changes made in the feature branch. Since CircleCI can leverage cache, rebuilding the image during CI is actually quite fast.
Data ingestion tool exploration
As mentioned before, when I joined incident.io, all but one of our data sources were ingested using Fivetran. While Fivetran is a great tool known for its reliability, efficiency, and extensive integrations, it is also costly. One of the top priorities in my Data Engineer role was to explore potential alternatives for ingesting our production database, which is a PostgreSQL instance hosted on Cloud SQL.
I started by exploring Google Datastream. Initially, it seemed like the ideal solution for us: fully hosted and managed by Google, easy to set up with Cloud SQL, and offering near real-time data. However, our database has a very high number of upserts, which caused Datastream to run constant merge statements in our BigQuery destination project. This resulted in much higher costs than Fivetran.
This high number of upserts made most other data ingestion tools we explored, such as Stitch and Airbyte, more expensive, as their pricing models are based on the number of upserts. In contrast, Fivetran charges a fixed fee per row per month, regardless of the number of operations performed on it. Therefore, we decided to stick with Fivetran for now, as it was the most cost-effective option and required no migration work. The 15-minute latency is not a deal-breaker for us at this time.
Platform cost
As our company rapidly expands, our platform costs increase proportionately. To understand these costs, I conducted an in-depth analysis using various data sources to pinpoint their origins. Three key areas emerged:
- Fivetran: the cost of the tool itself
- Fivetran’s BigQuery: the underlying BigQuery costs associated with managing Fivetran data
- dbt: the costs of running dbt in production and continuous integration
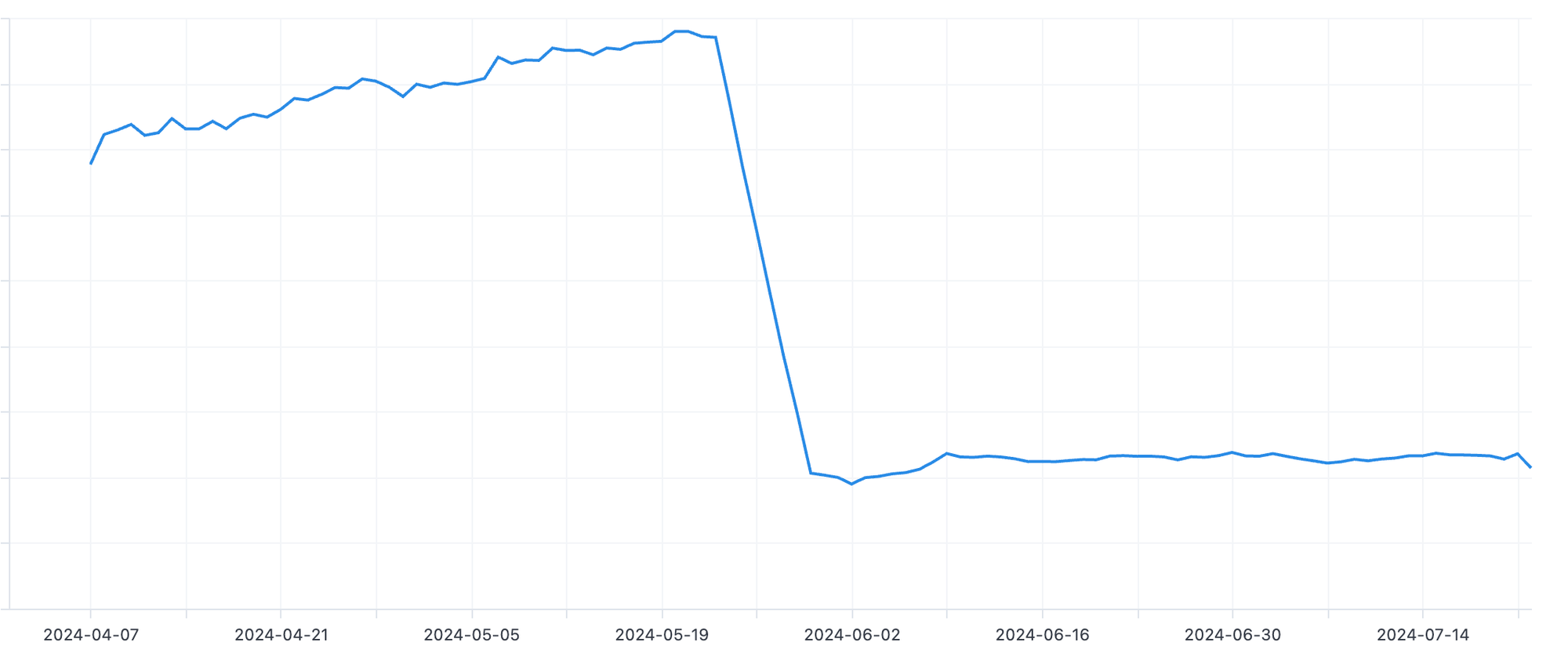
While there was limited opportunity to reduce Fivetran costs from a technical standpoint, I successfully decreased our Fivetran BigQuery costs by nearly 75%. This was achieved by clustering all destination tables by primary key, which reduced the amount of data scanned. The impact of this cost reduction is illustrated below.
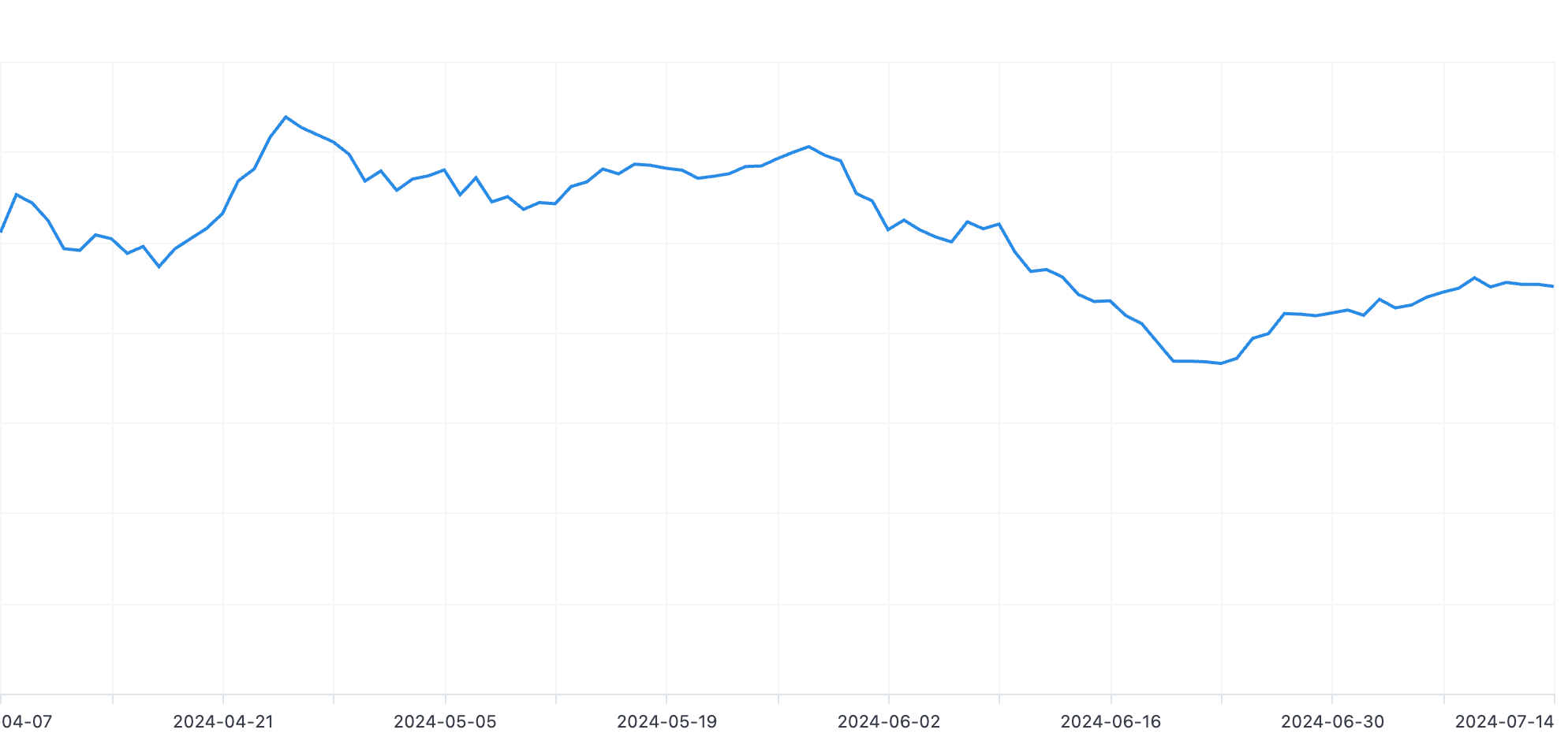
For dbt, switching heavy data scanning models to incremental ones and enforcing partitioning on large tables reduced our costs by approximately 20%, as shown below.
Conclusion
While I consider the two projects mentioned above to be my most significant contributions to the team and the company, I also continuously made smaller improvements to our data incident management workflow.
My experience at incident.io has been both challenging and rewarding. Working in a small, driven company allows me to tackle complex, interesting problems with a great deal of freedom in finding solutions. I have to admit: this is the kind of environment where I excel the most.

Lambert Le Manh
Senior Data Engineer
See related articles

Behind the Flame: Jack Broughton
Meet Jack Broughton, Business Development Representative here at incident.io. 🔥
 Megan Batterbury
Megan BatterburyJuly 16, 2026

Behind the Flame: Ellie Cherrill
Meet Ellie Cherrill, Product Engineer here at incident.io. 🔥
Megan BatterburyJuly 2, 2026

Behind the Flame: Sean Bennett
Meet Sean Bennett, Commercial Account Executive here at incident.io. 🔥
Megan BatterburyJune 18, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


