Migrating JSONB columns in Go
July 11, 2024 — 3 min read

At incident.io we embrace database migrations. Learning to run them quickly and safely is key to maintaining pace as our product grows.
We have previously shared our runbook for handling migrations safely, but today we are diving into a particular topic - migrating JSONB columns.
Note that we use Postgres, but this approach is applicable to all SQL databases.
What happens when a type stored as JSON changes shape?
Following our playbook, we will want to migrate all existing data into the new format, but how do we safely and comfortably handle two formats simultaneously in the interim period?
Case study: OR Conditions
Across our application we support the concept of conditions - “If A and B, do X”.
Recently we rolled out support for OR logic. For example, "If (A and B) or (C and D), do X".
Internally we refer to each group of OR’d conditions as a condition group.
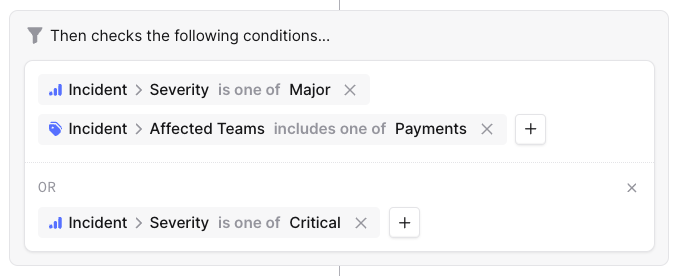
In the old world, we stored our conditions as a JSON array of objects - each object representing a condition. With condition groups, we needed to store an array of arrays of objects.
Here’s our original domain type, representing the schema.conditions is a JSONB Postgres column, which is marshaled into a slice of Go structs.
type EngineConfig struct {
ID string `json:"id" gorm:"type:text;primaryKey"`
Conditions Conditions `json:"conditions" gorm:"type:jsonb"`
}
type Conditions []Condition
type Condition struct {
Operation string `json:"operation"`
...
}And here’s our new domain type, storing condition groups instead:
type EngineConfig struct {
ID string `json:"id" gorm:"type:text;primaryKey"`
ConditionGroups ConditionGroups `json:"conditions" gorm:"column:conditions;type:jsonb"`
}
type ConditionGroups []ConditionGroup
type ConditionGroup struct {
Conditions []Condition `json:"conditions"`
}Backwards Compatibility
How do we read data in the old format []Condition into the new []ConditionGroup?
The answer lies in interfaces sql.Scanner and driver.Valuer.
type Scanner interface {
// Scan assigns a value from a database driver.
Scan (src any) error
}
type Valuer interface {
// Value returns a driver Value.
Value() (Value, error)
}When implemented on a column’s type, Scan and Value are used to read and write data from and to the database respectively.
We are therefore able to provide custom marshaling logic to safely cater for data of either format.
func (g *ConditionGroups) Scan(val any) error {
bytes, ok := val.([]byte)
if !ok {
return errors.New("could not parse condition groups as []byte")
}
if err := json.Unmarshal(bytes, g); err == nil {
// Both types will succeed unmarshalling.
// Check we didn't parse an empty array of the old type.
if len(*g) > 0 && (*g)[0].Conditions != nil {
// Data is of the new condition_groups format
return nil
}
}
conditions := []Condition{}
if err := json.Unmarshal(bytes, &conditions); err != nil {
return errors.New("could not unmarshal bytes into []Condition")
}
if len(conditions) == 0 {
// If we have no conditions, we have no condition groups.
*g = EngineConditionGroups{}
return nil
}
// Wrap the old-style conditions in a single condition group.
*g = EngineConditionGroups{
EngineConditionGroup{
Conditions: conditions,
},
}
return nil
}
func (g EngineConditionGroups) Value() (driver.Value, error) {
return json.Marshal(g)
}With our custom scanner in place, we can write data in the new format whilst also being able to read both old and new data.
This unblocks work on the rest of the codebase, allowing the change to be propagated up through the backend and into the frontend, in parallel with the remaining migration efforts.
The Backfill
The next step in the runbook is to backfill all of the old data in an async process, unifying the state of the data.
The scanner comes in clutch again here - we can simply read the data and immediately write it again. Performing this in the batch with an ON CONFLICT DO UPDATE clause speeds things up significantly.
Note we also added a temporary indexed column conditions_migrated to facilitate the backfill.
func backfillConditions(ctx context.Context, db *gorm.DB) error {
maxExpectedRows := 300000
batchSize := 1000
maxIts := maxExpectedRows / batchSize
for i := 0; i < maxIts; i++ {
// Fetch the next unmigrated batch
existing, err := domain.NewQuerier[domain.EngineConfig](db).
Filter(domain.EngineConfigBuilder(
domain.EngineConfigBuilder.ConditionsMigrated(false),
)).
Limit(batchSize).
Find(ctx)
if err != nil {
return err
}
if len(existing) == 0 {
// We're done!
break
}
// Prepare an updated model for each
payloads := []domain.Escalation{}
for _, e := range existing {
payloads = append(payloads, domain.EngineConfigBuilder(
domain.EngineConfigBuilder.ID(e.ID),
domain.EngineConfigBuilder.OrganisationID(e.OrganisationID),
domain.EngineConfigBuilder.Conditions(e.Conditions),
domain.EngineConfigBuilder.ConditionsMigrated(true),
).Build())
}
// Upsert new data
res := db.
Clauses(clause.OnConflict{
Columns: []clause.Column{{Name: "id"}},
DoUpdates: clause.AssignmentColumns([]string{
"conditions",
"conditions_migrated",
}),
}).
Create(ctx, payloads)
if res.Error != nil {
return res.Error
}
}
fmt.Println("Finished!")
return nil
}Once backfilled, the data is in a consistent state. Rip out the custom scanner and move on!

Louis Heath
Product Engineer
See related articles


So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


