incident.io vs. PagerDuty: In-depth feature comparison & TCO analysis
March 6, 2026 — 20 min read
Updated March 06, 2026
TL;DR: PagerDuty wakes you up and hands you a web UI. We wake you up, assemble your team, capture the timeline, and auto-draft the post-mortem, all inside Slack. For a 50-person engineering team, incident.io costs $12,036 less per year than PagerDuty Business with essential add-ons. Factor in the 45-75 minutes of post-mortem reconstruction time we eliminate per incident, and the annual TCO advantage reaches over $21,000. This comparison gives you the side-by-side feature breakdown, pricing math, and an honest verdict on which platform fits your team size and workflow.
PagerDuty has been the default choice for on-call alerting since 2009. Nobody got fired for buying it. But if you're an SRE team staring at a renewal invoice that's grown because of add-on pricing, you're probably asking a sharper question: is PagerDuty solving your actual problem, or just the alerting slice of it?
The real tax during a P1 incident isn't the alert. It's the 10-15 minutes you spend manually assembling the team, the three browser tabs you're toggling between, the Google Doc that's supposed to be the post-mortem but is actually a scattered list of Slack pastes reconstructed from memory. That's the coordination tax, and PagerDuty wasn't designed to eliminate it.
We built incident.io to solve the other 90% of the incident problem: coordination, communication, and learning. This comparison gives you the side-by-side breakdown on features, pricing, workflow differences, and a real TCO calculation for a 50-person engineering team. Use it to make the internal case for a switch, or to confirm that PagerDuty still fits your needs.
The core difference: alerting vs. end-to-end incident management
Think of PagerDuty as the smoke detector and incident.io as the fire response team. One alerts you. The other organizes the response, assigns roles, captures the timeline, updates your status page, and drafts the post-mortem.
PagerDuty's architecture is web-first. When an alert fires, you acknowledge in the PagerDuty app, then manually create a dedicated Slack channel from the incident card, invite responders by hand, and navigate back to Slack to collaborate. Channel creation can be automated via Incident Workflows, but that requires Business plan access and pre-configuration. Coordination still happens after the alert, not alongside it.
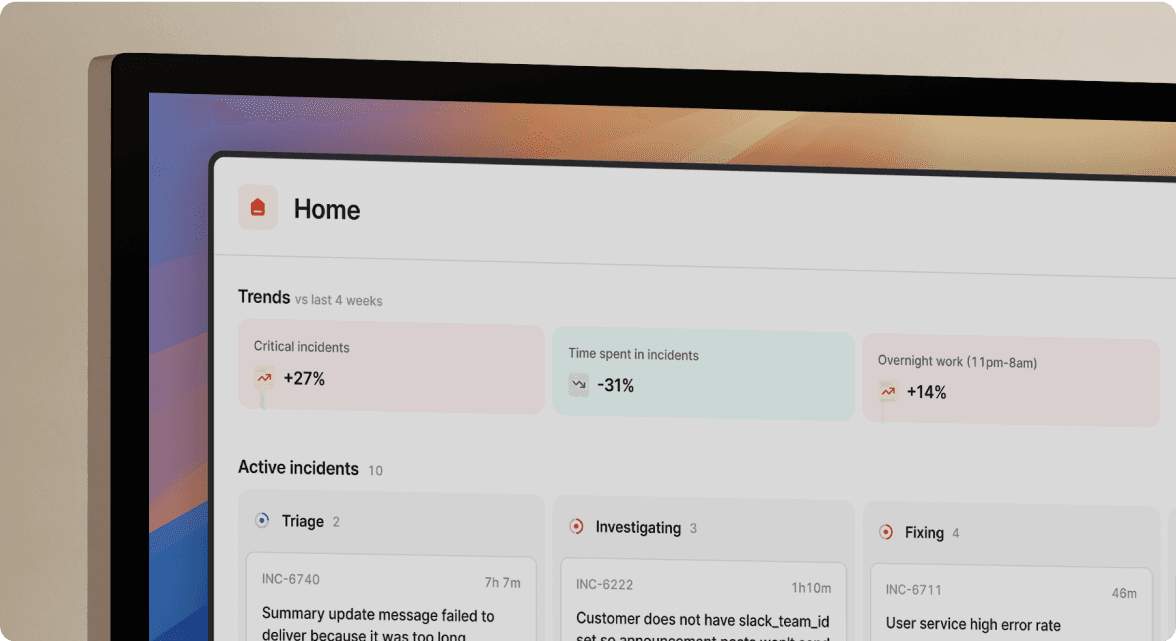
We built incident.io to be Slack-native from day one. The entire incident lifecycle lives in Slack: declare with /inc or by clicking three dots on any Slack message, and we auto-create a dedicated channel, page on-call engineers, assign roles, and start capturing the timeline, all without leaving your chat tool. One architecture requires you to manage the tooling while fighting the incident. Ours lets you manage the incident while the tooling handles itself.
Feature-by-feature comparison
Feature comparison table
When evaluating any incident management platform, the criteria that matter most are: how well the tool reduces cognitive load during active incidents, how much setup and configuration is required before it delivers value, and whether its feature set covers the full incident lifecycle, from detection and coordination through to post-mortem and learning. Cost-per-seat is rarely the whole story; the more important question is which workflows require manual effort versus automation, and where that gap compounds over time. The comparison below uses those criteria as a consistent lens across both platforms.
| Feature | incident.io Pro | PagerDuty Business |
|---|---|---|
| On-call scheduling | Yes ($20/user/month add-on) | Included |
| Slack-native incident declaration | Yes, one click or /inc | Manual channel creation required |
| Auto-created incident channels | Automatic on declaration | Requires Incident Workflow pre-config |
| Real-time timeline capture | Automatic | Manual or limited via app integrations |
| AI post-mortem drafting | Built-in, drafts in 10 seconds | Requires manual grooming |
| AI call transcription (Scribe) | Zoom, Google Meet, Teams | Not available |
| Status pages | Included | Separate add-on ($89/month+) |
| AIOps / noise reduction | Built-in | Separate add-on ($699/month) |
| PagerDuty schedule import | Yes, bulk import supported | N/A |
| Time to operational | 2-5 days | Weeks to months |
On-call scheduling and routing
PagerDuty's on-call scheduling is genuinely powerful for complex enterprise environments. You can build multi-layered escalation policies, follow-the-sun rotations, and sophisticated routing rules across hundreds of services. The trade-off is setup complexity. G2's comparison of PagerDuty vs. incident.io consistently surfaces feedback that overrides, rotations, and escalation configs feel overwhelming for new users, and the interface hasn't evolved significantly in recent years.
We designed incident.io's on-call setup with a calendar-based interface and flowchart-style escalation policies. You can click directly on the calendar to create overrides, add multiple rotation layers, and sync schedules with personal calendars via iCal. Our PagerDuty schedule importer lets you pull existing escalation policies and schedules directly, which eliminates the rebuild-from-scratch problem that makes migration feel risky. PagerDuty wins on raw routing complexity for edge-case enterprise scenarios, but that complexity comes at a usability cost most modern SRE teams don't want to pay.
"It takes all the pain out of incident management and lets you focus on working the incident itself." - Verified user on G2
Incident coordination and response
Coordination architecture
This is where the platforms diverge most sharply. The PagerDuty Slack integration works via the /pd trigger command or Slack workflows, but viewing full incident details, editing timelines, and accessing analytics all require navigating to the PagerDuty web app. Coordination stays fragmented across PagerDuty's web UI, Slack, and whatever documentation tool your team uses.
With incident.io, you declare an incident from any Slack message. We auto-create #inc-[number]-[name], page on-call, pull in service owners from the Catalog, and start timeline capture immediately. Commands like /inc assign @sarah, /inc escalate @database-team, and /inc severity high feel like natural Slack messages. No app-switching. No "who's on-call this week?" lookup in a Google Sheet at 11 PM.
Assembly time: the measurable difference
The time-to-assemble difference is measurable. Manual team assembly across PagerDuty and Slack typically takes 10-15 minutes per incident. With incident.io's automated channel creation and on-call paging, that drops to under 3 minutes. A typical incident pulls in 4-5 responders, each losing roughly 10 minutes to manual assembly, 45 engineer-minutes per incident that incident.io eliminates. At 18 incidents per month with a $150 loaded hourly engineer cost, assembly time savings alone total $2,025 monthly, and that's before you count what we eliminate on the post-mortem side.
"It empowers anybody to raise an incident, and helps us quickly coordinate any response across technical, operational and support teams." - Matt B. on G2
Post-mortems and learning
The post-mortem archaeology problem
Post-mortem archaeology is one of the most commonly cited SRE pain points: spending 60-90 minutes after a resolved incident reconstructing a timeline from Slack scroll-back, PagerDuty alert history, Datadog event annotations, and half-remembered conversations. The standard PagerDuty post-mortem workflow is a manual process where the owner goes through Slack history to identify key actions and links each timeline item to a data source. It works, but it's archaeologically slow.
Automated timeline capture
We solve this by capturing the timeline during the incident, not after it. Scribe, our AI transcription feature, automatically joins and transcribes incident calls on Zoom, Google Meet, and Microsoft Teams in real-time. Our AI suggested summaries feature generates a post-mortem draft within 10 seconds of incident resolution, complete with timeline, key decisions, contributing factors, and suggested follow-up actions. Total editing time drops to 15 minutes instead of 60-90, saving 45-75 minutes per post-mortem. As documented in our comparison of automated post-mortem generation across platforms, for a team handling 18 incidents per month with four requiring detailed post-mortems, that's at least 180-300 fewer minutes of engineering time each month spent writing rather than fixing.
"The ability to automate routine actions, such as postmortem reports generation... significantly reduce the time spent on manual, repetitive tasks, reusing the incident communication channel on Slack as a basis for the postmortems summary." - Vadym C. on G2
AI and automation capabilities
PagerDuty's AI offering lives under the AIOps product, which focuses primarily on noise reduction using machine learning to group alerts and reduce alert volume. It's licensed per accepted event and priced separately from the base plan. Its capabilities center on alert grouping and intelligent event routing. Drafting post-mortems and transcribing incident calls aren't in scope.
We built the AI SRE assistant directly into the Pro plan, and it covers a broader surface area. Beyond Scribe transcription and post-mortem drafting, our AI assistant surfaces relevant past incidents and suggests root causes based on pattern-matching. The platform can automate up to 80% of incident response workflow.
The key distinction: PagerDuty's AI reduces alert noise before the incident. Our AI reduces cognitive load and manual work during and after the incident. Both matter, but most SRE teams find the during-and-after problem harder to solve independently.
"incident.io consolidates workflows that were spread across multiple tools into one centralized hub within Slack... The automation is great for handling repetitive tasks, which many engineers are eager to cut down on." - Alex N. on G2
Pricing and total cost of ownership
Evaluating the true cost of any incident management platform requires looking beyond the per-seat headline price. The two primary pricing models in this space are bundled (a single plan that includes most capabilities) and modular (a lower base price with core features licensed separately as add-ons). Both models have legitimate trade-offs: modular pricing can suit teams that only need a narrow feature set, while bundled pricing provides cost predictability as requirements grow. When calculating total cost of ownership, the components worth examining include the base license, any separately billed add-ons for features like AI noise reduction or workflow automation, professional services or onboarding fees, and the internal engineering time required to build and maintain integrations. Add-on risk, the tendency for modular platforms to increase costs sharply as a team matures and activates more capabilities, is one of the most commonly overlooked factors in initial vendor comparisons.
The base price trap
PagerDuty's Business plan is priced at $41 per user per month. That sounds comparable to incident.io until you add the features modern SRE teams actually need. Noise reduction capabilities are licensed separately per accepted event, on top of the base plan. Adding the components a typical 50-person team requires:
50-user PagerDuty Business team annual cost, based on published pricing:
| Cost component | Annual total |
|---|---|
| Base plan (50 users x $41/month x 12) | $24,600 |
| AIOps add-on ($699/month) | $8,388 |
| PagerDuty Advance AI ($415/month) | $4,980 |
| Status Page add-on ($89/month) | $1,068 |
| Total | $39,036 |
What's included in incident.io Pro
Our Pro plan bundles status pages, workflows, post-mortems, and AI capabilities into the base price. On-call management is an add-on at $20/user/month. We designed this pricing model to be transparent: no per-event fees, no separate AIOps tier to unlock, no status page surprises at renewal. The Pro plan includes the features your engineers actually use on a 3 AM incident, because billing complexity is the last thing you need mid-outage.
50-user incident.io Pro team annual cost:
| Cost component | Annual total |
|---|---|
| Pro plan (50 users x $25/month x 12) | $15,000 |
| On-call add-on (50 users x $20/month x 12) | $12,000 |
| Status pages, AI, workflows | Included |
| Total | $27,000 |
Hard cost savings: $12,036 per year for a 50-person team, a 31% reduction before you account for engineer time.
Adding engineer time to the TCO
Hard licensing costs are only part of the equation. Factor in post-mortem reconstruction time against our automated post-mortem generation:
- PagerDuty workflow: 60-90 minutes per post-mortem, 4 per month = up to 6 hours/month
- incident.io workflow: 15 minutes per post-mortem, 4 per month = 1 hour/month
- Time saved: up to 5 hours/month = up to 60 hours/year
- At $150 loaded engineer cost: up to $9,000/year in reclaimed time
Combined TCO advantage for a 50-person team: over $21,000/year ($12,036 in licensing plus up to $9,000 in engineering time reclaimed).
Integration ecosystem and setup time
Integration compatibility
Both platforms integrate with the standard enterprise monitoring and observability stack: Datadog, PagerDuty (as a passthrough), Grafana, Prometheus, AWS CloudWatch, and most ticketing systems including Jira and ServiceNow. When evaluating integration ecosystems, the relevant questions are: does the platform support your existing alert sources without requiring schema changes, does it maintain compatibility through vendor updates, and does it offer a documented API for custom integrations your team might need to build? Either platform will cover the majority of common tool combinations out of the box, so integration breadth alone is rarely the deciding factor. The more meaningful distinction is the operational effort required to activate, configure, and maintain those integrations over time.
Migration path and time to operational
We designed incident.io to be operational in 2-5 days. The Intercom migration case study shows what that looks like in practice: automating the transfer of alerts and configurations made the switch fast, with incident.io running alongside PagerDuty briefly to validate reliability before full cutover. The migration path for most teams looks like this:
- Connect your PagerDuty integration to incident.io as an alert source using the existing connector.
- Bulk import schedules and escalation policies directly from PagerDuty without rebuilding from scratch.
- Run parallel for 2-4 weeks to validate routing logic before cutting over.
- Deactivate the redundant setup once you've validated reliability.
The easier migrations update in our changelog added bulk import support for teams with many schedules, replacing what was previously a manual one-by-one process. Intercom's engineering team summarized their outcome on our customer page: "Our engineers immediately preferred incident.io over PagerDuty, and adoption across the broader company quickly followed."
"It's super easy to implement, and as a result, has become a tool that we use several times a day as a team." - Tony R. on G2
For a broader look at how incident.io stacks up across the field, this three-way comparison of PagerDuty, incident.io, and FireHydrant covers the decision criteria clearly.
The verdict: which tool is right for your team?
This isn't about declaring a universal winner. PagerDuty is the incumbent for a reason. The decision comes down to what problem you're actually trying to solve.
We built incident.io for teams where the coordination tax costs more time than the alerting problem. PagerDuty solves alerting exceptionally well. We solve alerting and build the coordination layer that PagerDuty leaves to you, and that's a deliberate product choice, not a gap.
Choose PagerDuty if:
- You run a large enterprise (2,000+ engineers) with complex, non-standard routing requirements across legacy on-prem and cloud infrastructure.
- Your primary need is alerting and noise reduction, and you're comfortable managing coordination in separate tools.
- You have existing Enterprise contracts with deep ServiceNow or ITSM integrations that would be expensive to rearchitect.
- You need maximum flexibility in alert routing logic and the configuration overhead is acceptable.
Choose incident.io if:
- You're running a modern tech company with 50-1,000 engineers on cloud-native infrastructure using Slack as your communication backbone.
- Your biggest pain points are the coordination tax (assembling teams, context switching across tools) and post-mortem archaeology (manual timeline reconstruction).
- You want MTTR reduction backed by real numbers. Favor cut MTTR by 37% after adopting incident.io, and our AI capabilities can automate up to 80% of incident response workflow.
- You want transparent pricing without AIOps add-ons or status page tiers appearing at renewal.
The honest positioning: if coordination overhead is where your team loses time during and after incidents, the math favors incident.io by a wide margin. You can validate that by scheduling a demo and running your first incident through incident.io to compare assembly time and post-mortem effort directly. Two incidents is usually enough to know.
"Without incident.io our incident response culture would be caustic, and our process would be chaos." - Matt B. on G2
If you're not ready to commit to a full trial yet, the lowest-friction next step is to schedule a demo and run a single real incident through incident.io side-by-side with your current stack. When you're ready to run a live pilot, schedule a demo to see the workflow running with your own incident data.
If you're building the internal business case for a switch, book a demo. We'll walk through the TCO calculator with your incident volume, team size, and current PagerDuty spend plugged in.
Key terms glossary
Coordination tax: Time lost during an incident on logistics (assembling the team, switching tools, finding context) rather than actual troubleshooting. Typically 10-15 minutes per incident with fragmented tooling.
MTTR (Mean Time To Resolution): Average time from alert firing to incident declared resolved. The primary reliability metric used to benchmark incident management efficiency.
On-call rotation: The schedule determining which engineer is responsible for acknowledging and responding to alerts during a given time window.
Post-mortem: A structured document written after an incident capturing timeline, root cause, contributing factors, and follow-up actions. The standard term in SRE practice for structured incident learning.
Slack-native: A product architecture where the full workflow (declaration, coordination, resolution, documentation) runs inside Slack rather than requiring navigation to a separate web application.
AIOps: Alert Intelligence Operations features that use machine learning to reduce alert noise, group related alerts, and route incidents intelligently. Sold as a separate add-on in PagerDuty's pricing model and built into incident.io's Pro plan.
Timeline capture: Automatic recording of key incident events (alert received, engineer joined, escalation triggered, fix applied) as they happen, forming the basis for post-mortem generation without manual reconstruction.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

