Game Day: Stress-testing our response systems and processes

At incident.io, we deal with small incidents all the time—we auto-create them from PagerDuty on every new error, so we get several of these a day. As a team, we’ve mastered tackling these small incidents since we practice responding to them so often.
However, like most companies, we’re less familiar with larger and more severe incidents—like the kind that affect our whole product, or a part of our infrastructure such as our database, or event handling. These incidents require a higher level of communication with customers and coordinating a larger team of responders, all while remaining calm and collected.
Prompted by our November outage "Intermittent downtime from repeated crashes", we decided to give ourselves some practice and scheduled a Game Day. During Game Day, we’d respond to some “manufactured” incidents in order to test and improve our response skills. We split the day into two parts: a tabletop exercise in the morning, and some simulations in the afternoon.
In the end, we found the day to be really valuable. We improved our processes, our abilities to respond to incidents, and even gained some new insights into our own product too.
So how did it all happen?
Game Day preparation
Before we could all jump into a room and start hashing out response tactics, we first had to come up with a plan for the day. Luckily, our Product Engineer, Lawrence, and Engineering Manager, Alicia, put together a plan for the day ahead of time.
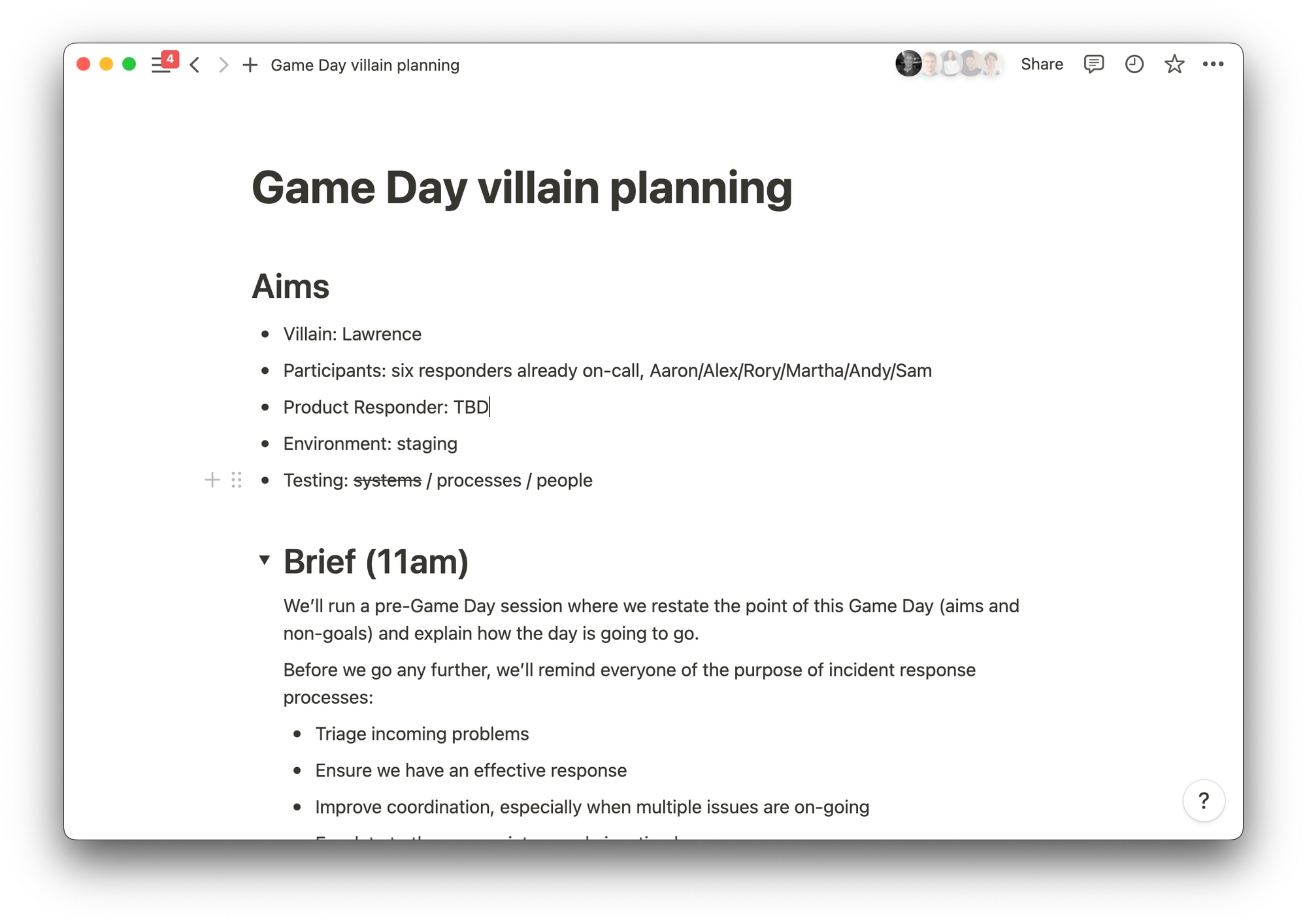
The plan called for splitting the day into two parts: the first was a tabletop exercise, where we’d get the engineering and customer success teams to sit around a table and discuss hypothetical incidents and how we might respond to them. The second part was responding to simulated incidents.
We carved out a few hours when people would go about their regular tasks but would be on-call for Game Day incidents.
Who we involved
We’d ideally have been able to involve every engineer in the Game Day. But to keep things realistic and small-scale for our first go-round, we limited it to six people. These were responders who are on our on-call rotation, but who haven’t dealt with many high-severity incidents just yet.
Part of a good game day is making the experience as realistic as possible. To do this, we had a member of our Customer Success team, Lucy, and our CTO, Pete, involved. They would act in their normal roles for these mock incidents, so we had to be considerate of how we liaised with them as the incident progressed.
Tabletop exercise
To start, we gathered a group of engineers into a room and talked through the hypothetical incidents. We made calm and rational decisions about how we’d solve the problems. It was a good chance for us as responders to align on things like when to reach out to customers, when to escalate to someone else, or which initial severity to pick.
Lawrence had prepared some screenshots of PagerDuty alerts, each containing different errors. Most of the screenshots were from real incidents we'd had before, repurposed for the scenario. Very low effort, but effective at making it feel a bit more real.
We selected someone as the on-call engineer, and they talked through the steps that they’d take to respond to the alert. In between steps, we’d stop and discuss the rationale behind that decision and bounce opinions off one another.
It was also a good chance for newer engineers to get an idea of how we respond to more complex incidents. Having everybody thinking out loud was really helpful here.
In retrospect, everything went reasonably smoothly, and we left feeling confident.
Simulated incidents
Ahead of time, Lawrence had prepared a set of breakages he could make to our staging environment that would trigger alerts that we could debug. Throughout the afternoon at random times he would enact these breakages and someone would get alerted and go into incident response mode. We treated each alert like we would a real production alert.
Later on, I’ll go into a bit more detail about how we used staging.
Incident one: adios, dynos
Before long, our nominated on-call engineer got paged. They noticed they couldn’t load our web dashboard, and declared an incident. We assessed the impact as critical, which means that we automatically escalate to all the founders of incident.io.
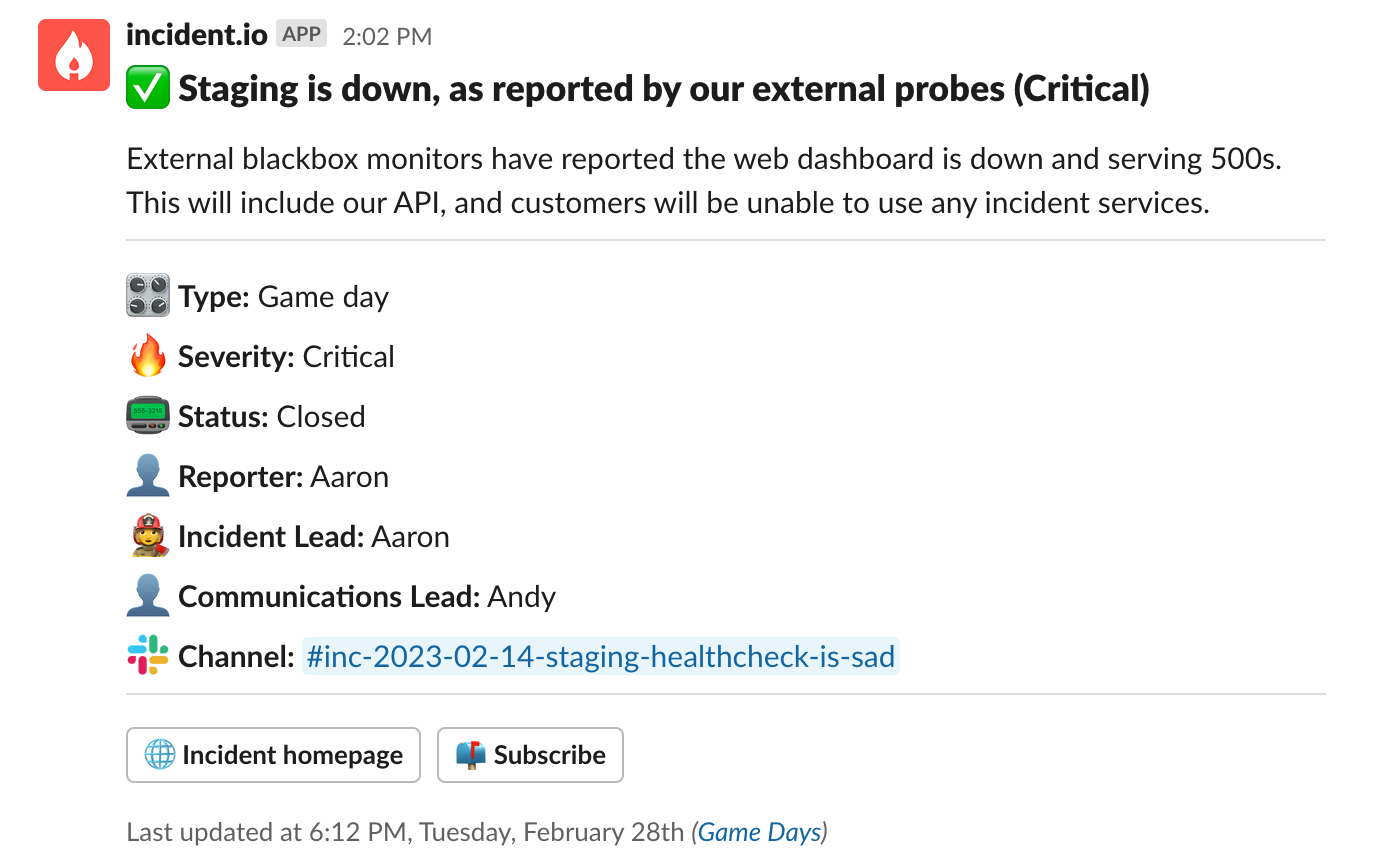
Both Pete and Chris, our CPO, join the incident, while another engineer notices that we have no running “web” Heroku dynos. That’s bad—no dynos means no dashboard or API.
To kick things off, we check that our workers, which process background tasks, are all present and correct—and they appear to be. As we do this, Pete asks if we’re back up—he’s noticed a customer saying that they can’t declare incidents.

A couple of us can’t log in to the dashboard, and we also see some errors with publishing events — a group splinters off to focus on this, and declares another incident. We appoint a comms lead, publish a status page update, and end up declaring two more incidents for these (seemingly) separate issues.
After some investigation, we find the root cause: a permissions issue within Google Cloud Platform. We fix this, but along the way communication breaks down across the multiple incidents. It’s really hard for the CTO and Customer Success to get a clear picture of what’s happening. All six engineers are responding to incidents at this point, with several of them acting across more than one.
Once we roll out the fix and things start looking better, the chaos dies down, we move incidents to “Monitoring” and take some time to regroup and provide updates. Coffee break time.
Incident two: a tweeted secret
Our response to the second incident was worlds apart from the first. Pete has tweeted our Slack webhook signing secret — he lets us know via Slack, and we declare an incident manually.
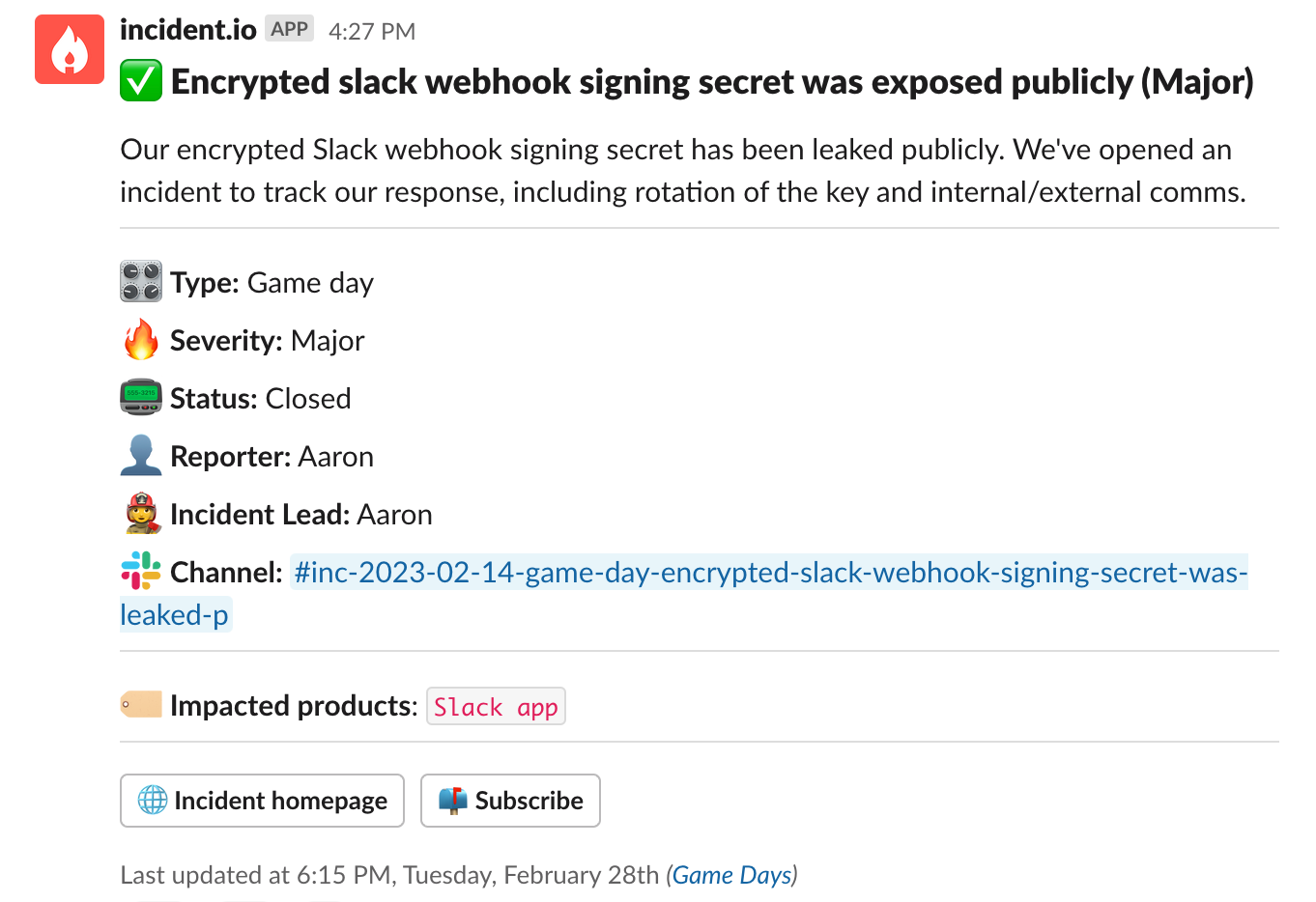
An engineer calmly explains what this secret is used for, and the incident lead calls for two teams of two engineers: one team to rotate the secret, and another to run through our logs to check for any bad actors.
The other two engineers involved in the Game Day hang back, knowing that we suffered a bit from having “too many cooks” during our first incident. This turns out to come in useful because we see alerts about the API being slow. Those two engineers branch off and enlist the help of another engineer who’s no longer needed in the first incident. Together, they find a long-running database transaction that’s locking the entire incidents table. They terminate this, and everything springs back to life again.
What we learned
Communication was the trickiest part of the day, with the coordination of humans and roles coming a close second. As soon as we had more than one incident running, it became unclear who was “heads up” running the incident, and who was “heads down” triaging and fixing issues.
We learned that it’s more helpful to help when you’re asked to help, as opposed to having everyone jump in at once. Having some spare capacity paid off when a second incident rolled in. When multiple incidents were running, having a “huddle” between the incident leads and the comms lead helped us to provide clear written updates both internally (via incident.io) and externally (via our status page).
Having incident leads stay out of the deeper technical details of incident response meant that they could do a much better job of coordinating that response.
During the day, we also did some fairly intense dogfooding of our own product, and we left with a raft of ideas about how we might better support communication across multiple incidents.
Our advice for running your own Game Day
We’d love to run game days as a part of our regular cadence of onboarding, and we’ll definitely be running more of these in the future.
Running your first one will require a bit of preparation, but re-running subsequent days should feel quick and easy. Your team will come out of it feeling more confident, better prepared, and with a deeper appreciation of any weak spots.
Here are some tips to get the most out of your day:
- Have a range of “levers” you can pull. We had a (private!) list of a dozen or so things that we could interfere with, where each action had clear instructions for enabling it and, more importantly, disabling it.
- Go beyond engineering. Having customer service step in as actors made it really realistic, and meant sure we tested our communication. This was a tricky part, and we’re glad we didn’t cut a corner here.
- Make your simulated incidents plausible. You want them to feel real, so don’t make them too far fetched. At the same time, be clear with the wording you use so that it’s obviously fake to any observers: we used fake customer names.
- Have an escape hatch. Make sure everyone knows how you’ll announce the suspension of a game day: if a real incident happens, you want everyone to switch over into “real” incident response mode.
- Run more than one incident. Regroup between the two, and tidy up any loose ends before you continue. Hopefully, you’ll notice a huge difference between the response to your two incidents.
- Have a retrospective. A day or two after, run a retrospective to discuss what went well, and what didn’t. Did you spot a gap in people’s knowledge? Was there something that went especially well? Feed this back into your next iteration.
It’s also worth a quick note about where you run your game day. We ran it in our staging infrastructure, which is a very close match to production, and had real alerts coming from Sentry and PagerDuty. Try to run your game day as realistically as is reasonably possible — you want your responders to be in a realistic environment, and the tools you use make up a big part of that.
We used our real incident.io account, but set up a brand new “Game Day” incident type that we excluded from our announcement rules and workflows, and published status page updates to a test status page.
Do you run Game Days?
It doesn’t take much investment to run a great game day. Each of us spread knowledge around the team, and each of us came out of it with a greater appreciation for the complexities of responding to larger incidents.
How do you run game days? Are they something you do regularly? Which parts do you find tricky? If you don’t run game days, hopefully, this post helps you get the ball rolling on yours.
If you already are, we’d love to hear more about how you’re running them. Watch this space as we’ll be writing more in the future about our Game Days as we continue to iterate on them. Find us on Twitter: @incident_io.

See related articles

Don't add a read replica until you've read this
Our learnings from implementing a product-wide read replica migrations, including some useful patterns for routing queries to replica and primary
 Johanna Larsson
Johanna Larsson
We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete Hamilton
Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherSo good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


