Developer environments should be cattle, not pets
April 3, 2023 — 5 min read

Cattle, not pets is a DevOps phrase referring to servers that are disposable and automatically replaced (cattle) as opposed to indispensable and manually managed (pets).
Local development environments should be treated the same way, and your tooling should make that as easy as possible.
Here, I’ll walk through an example from one of my first projects at incident.io, where I reset my local environment a few times to keep us moving quickly.
💻 Our dev setup at incident.io
Before diving into an example, here’s a quick run-down of our dev environment setup at incident.io. Each developer creates their own Slack app to test changes against, which is set up using a script in our toolbox and connected via ngrok to their local server.

We originally wrote toolbox scripts like this to create an easy onboarding flow for new engineers that would automate as much of the process as possible.
They’re also great to reuse for resetting specific parts of your environment to their original configuration if you’ve made breaking changes or just want to make sure you’re working with a clean, production-like environment.
If your environment is difficult and time-consuming to set up, or you’ve spent months diligently filling it with test data that make for great demos, it can be easy to get attached. But rarely resetting it has a few major downsides:
- Slowing down the onboarding process for new joiners by giving them setup scripts that aren’t used regularly or well-maintained
- Slowing down existing engineers by making them reluctant to test out changes locally because it risks leaving it in an unusable state that’s difficult to recover from
🏢 An example: installing incident.io into Slack Enterprise Grid
The incident.io product started as an app installed into our customers’ Slack workspaces; as such, each account remains tightly coupled with the Slack workspace it’s installed into.
Slack Enterprise Grid is a network of multiple Slack workspace instances under the umbrella of one Slack account.
This meant that for our workspace-level app, you would need a separate incident.io account for each workspace in the grid, and you would only be to access the web dashboard for one Slack workspace at a time.
So when we decided to prepare our app for installation at the grid level, there was a lot of uncertainty around how we would uncouple our account <> workspace pairs and maintain a consistent integration with Slack across both grid and workspace-level installations.
At times like these, it’s best to get as many unknown unknowns out of the way as soon as possible, so we kicked off an enterprise installation spike alongside our usual project preparation.
🦔 Spiking fast and breaking everything
My role at this point was to install our existing app into an Enterprise Grid Sandbox, breaking whatever I needed while the project lead (Aaron) focussed on scoping out the project.
Conveniently, it was only my second project at incident.io, so I was familiar with all the setup tools and not yet attached to my dev environment.
I successfully installed the app at the grid level via a few handcrafted installation URLs. Still, doing so changed so much configuration in my development Slack app that the incident.io bot no longer had permission to announce incidents in Slack. I didn’t know how to return it to a production-like state for future engineering work.
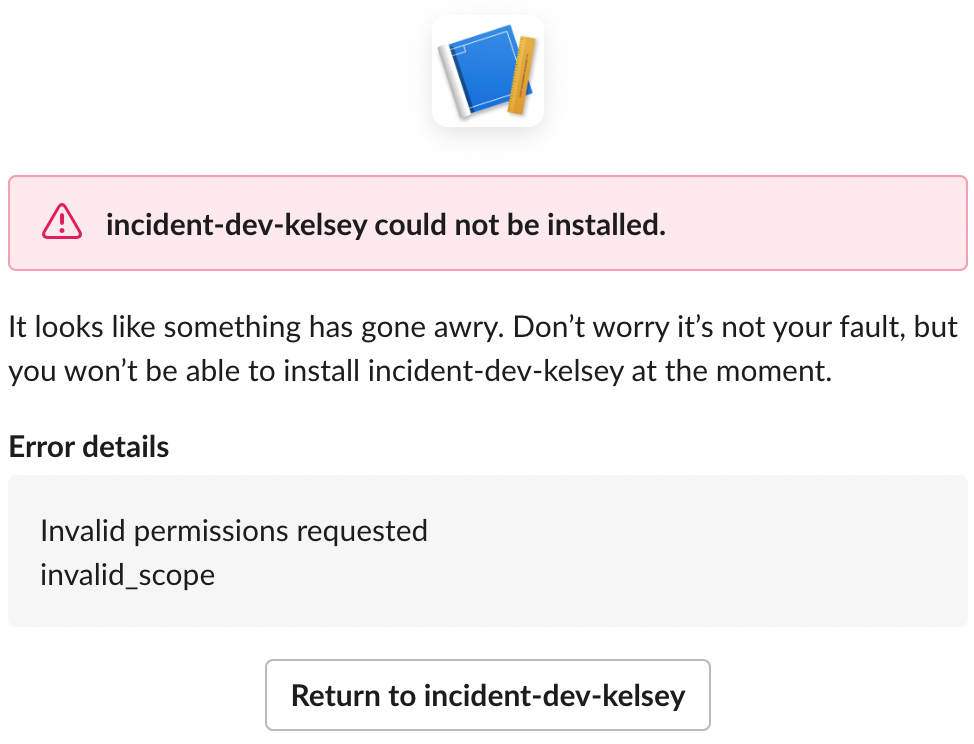
Using the script I mentioned earlier, with one command from our toolbox, I could generate a fresh app with the correct settings in a few minutes every time my configuration changes strayed too far.
During the project, I continued to uninstall and reinstall the app to test different edge cases (with Enterprise grid, there are many 😓).
That left my local database with such broken data that, at times, I couldn’t run a single Slack command or see anything past the login page in the web dashboard. It probably didn’t help that I deleted every sanity check out of the code along the way, blocking my misconfigured Slack commands, thereby freely letting the bad data in.
Once again, that was not a problem because I could drop my database as often as needed, and simply restarting my server and logging in would create a new account with the default settings.
🐮 Outcome
The spike was well worth it. We found some unexpected API behavior that required us to rethink the data model of the whole project at the perfect time while we were still scoping it out.
Even when the spike was over, during the project, I found my environment in unusual states repeatedly. But I now had the confidence to reset everything locally as often as I needed to—usually around once per week—putting my environment back to the way it was on my first day at the company, and knowing it would be done so quickly that it would not impact our delivery schedule.
It’s essential to be working with something as close to a production environment as is feasible, and treating your local development environment as replaceable cattle rather than a beloved pet is a crucial part of that, freeing you to spike significant changes or tinker directly in the database, then reset it at a regular cadence before you move on to the next thing.

Kelsey Mills
Product Engineer
See related articles

Don't add a read replica until you've read this
Our learnings from implementing a product-wide read replica migrations, including some useful patterns for routing queries to replica and primary
 Johanna Larsson
Johanna LarssonJuly 21, 2026

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


