Deploying to production in <5m with our hosted container builder
November 18, 2021 — 10 min read

Fast build times are great, which is why we aim for less than 5m between merging a PR and getting it into production.
Not only is waiting on builds a waste of developer time — and an annoying concentration breaker — the speed at which you can deploy new changes has an impact on your shipping velocity.
Put simply, you can ship faster and with more confidence when deploying a follow-up fix is a simple, quick change.
That's why when our build times began to creep toward the 10m mark, we took action to reduce it. We're now back at ~3m builds — this is how we did it.
Our CI pipeline
As background, incident.io is deployed as two logical components:
- Frontend app, compiled from TypeScript using create-react-app into a static Javascript + asset bundle
- Backend server written in Go, which serves an API along with static assets
We deploy to Heroku using their Docker buildpack, after our CircleCI pipeline builds a single Docker image that looks something like this:
# Build client assets
FROM node:16.6.1-alpine AS build-client
RUN build-client ...
# Build server assets
FROM golang:1.17.0-alpine AS build-server
RUN build-server ...
# Combine the two
FROM alpine:latest AS runtime
COPY /app/client/build ./web
COPY /app/server/bin ./bin
What's the problem?
We first noticed our pipeline had become slow when our Docker build step became inconsistent, sometimes taking ~3m, but other times up-to 10m.
While we have other pipeline steps like static analysis and testing, it doesn't matter if the build takes that long — we can only deploy once the Docker image has been built.
So why had this got slow? What changed?
To start, know that our build relied heavily on Docker layer caching. In brief, when Docker builds images it does so in layers — you begin with the layer described from your FROM directive, and produce a new layer for each subsequent directive in the Dockerfile.
Let's use an example:
FROM node:16.6.1-alpine
ADD src/client
RUN build-client ...
This Dockerfile has just three directives, a FROM, ADD and a RUN.
Building a Docker image begins with the base, which is often pulled from a remote registry. In our case, the base image is set by the FROM, and is node:16.6.1-alpine.
Base images are no different than any other, and are formed by a succession of Dockerfile directives, each of which creates a new 'layer'. When a Docker container is created from an image all these layers are merged into a single filesystem, but Docker keeps track of the individual layers that comprise an image, uniquely identifying each layer with a checksum.
Layer checksums are important, as the Docker daemon is permitted to use layer checksums to skip running commands if we think a layer already has the result. We're allowed to assume this because Docker build commands are expected to be repeatable: ie, each command is assumed to produce the same result when run in the same environment.
Going back to our example, this provides an opportunity to shortcut some work. As we pin our base image and expect it to remain consistent across many builds, if our client sourcecode (src/client) is the same as a previous build then:
- Docker will compute the same layer checksum after running the
ADD - We have an image in cache that matches this checksum, from a previous build. As
RUNcommands are expected to be repeatable, we're allowed to skip runningbuild-clientin favour of reusing the layer generated in the previous build
This all makes sense — if we've previously run build-client against the same sourcecode, it's reasonable to assume we can reuse the previous result.
Our existing build process relied heavily on this behaviour, as we expected that:
- We wouldn't rebuild the backend unless we changed the backend code
- Similarly, frontend builds should only happen when the frontend is modified
Sadly, this didn't appear to be happening.
Why no cache?
The worst builds were occuring when, despite only changing something in either front or backend, the Docker daemon thought it needed to rebuild everything.
Why might that be the case?
Docker layer cache isn't anything special — it's just files stored on a disk, compressed tarballs representing each layer. On a standard Linux installation you'll find this in /var/lib/docker, which you might notice growing with each build.
We were using CircleCI to build our Docker images, which involved creating a new container for each build step. With default configuration you'd be right to expect our /var/lib/docker cache will be empty for each run (as every CircleCI execution should use a new container with a fresh filesystem) except we'd enabled CircleCI's Docker layer caching feature explicitly to tackle this:
DLC (Docker Layer Caching) caches the individual layers of any Docker images built during your CircleCI jobs, and then reuses unchanged image layers on subsequent CircleCI runs, rather than rebuilding the entire image every time.
This seems perfect, and implies each build step will share a Docker layer cache. But as anyone who's played with networked filesystems will know, just 'sharing' a filesystem across CircleCI instances that might be running concurrent builds isn't an easy job.
CircleCI document (but in smallprint you'd be forgiven to miss) how they actually provide the layer cache:
if cache disk is available (read: unattached) then:
attach it
else
create new disk
attach disk
Well, this explains things. Our builds had become slower almost as soon as we made our first engineering hires, when we started pushing more changes and triggering more builds.
If we can't have two CircleCI build steps using the same disk, we will inevitably have some jobs colliding, with one getting an empty layer cache. As we increased our build frequency our cache would get increasingly fragmented, leading to the totally—cold builds taking upward of 10m to complete.
Taking things into our own hands
Clearly we had a cache issue, but that wasn't the only problem.
Even when using a hot cache, if both backend and frontend had changed, you could expect a slow build. Using Docker buildkit meant we could build our client and backend layers concurrently, but the CircleCI instances we used (medium) would be totally saturated by both happening together, leading to ~5-7m builds.
The larger resource types helped the build time, but anything of large or greater would add minutes in provisioning. Like whac-a-mole, we'd solve our long tail of build times in exchange for 2x'ing the runtime of our average build.
Going back to the drawing board, the ideal solution would be a machine that:
- Has enough capacity for all our build needs
- Is running continously, removing any need to provision on-demand
- Stores all build layers on one large, fast disk
Well... that's not very hard, can we not do that?
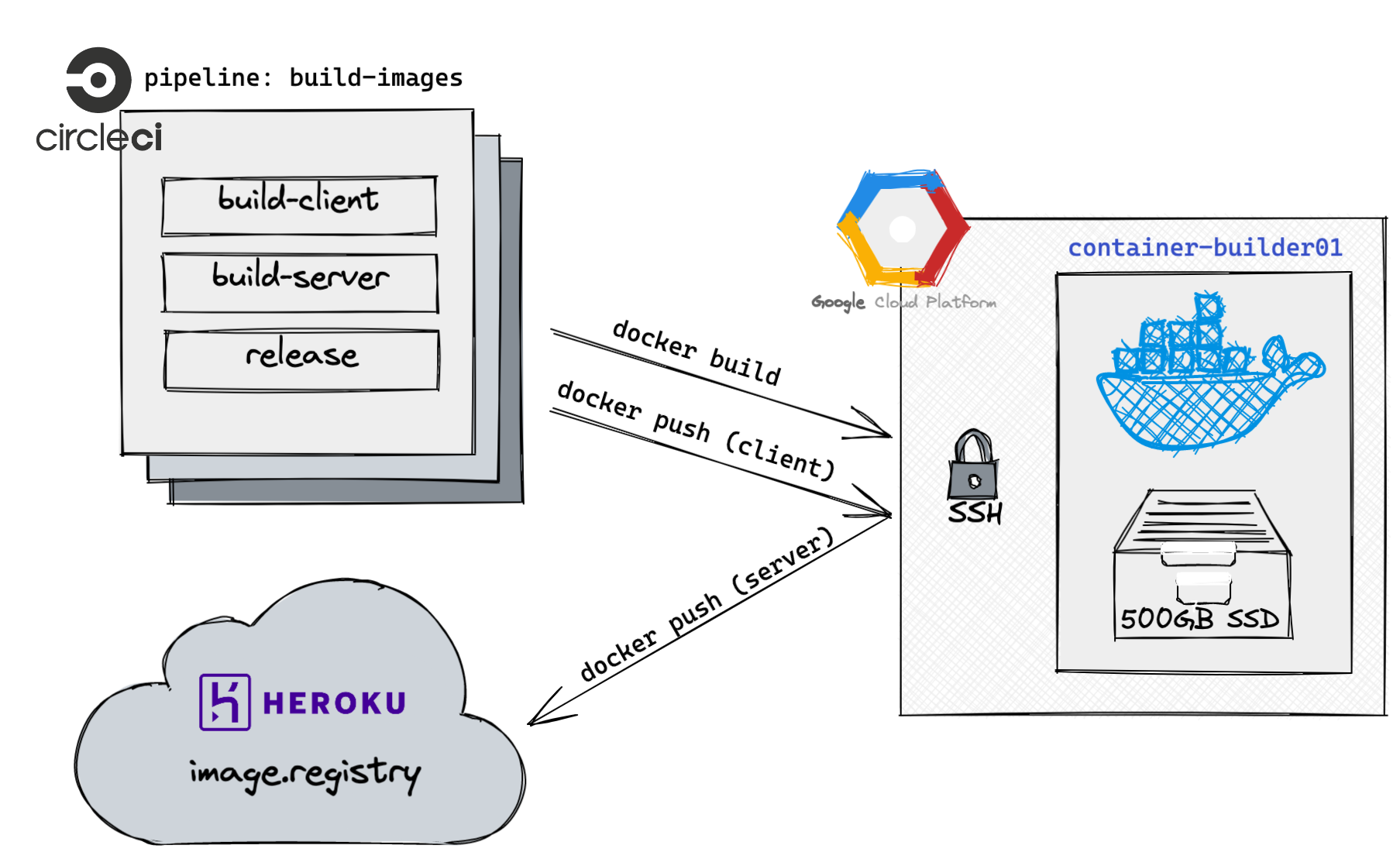
It took a couple of hours, but we provisioned a c2-standard-8 machine (CPU optimised, 8 cores, 32GB memory) in a region near CircleCI and Heroku infrastructure, then attached a 500GB SSD.
For reference, here's the terraform code.
Once setup, we tested building our app in all combinations of cache state. Remembering that we were seeing builds range from 3m to 10m+, these were the results:
| Builds backend | Builds frontend | Duration |
|---|---|---|
| No | No | 20s |
| Yes | No | 50s |
| No | Yes | 1m 49s |
| Yes | Yes | 1m 50s |
An average build of master looks like this now:
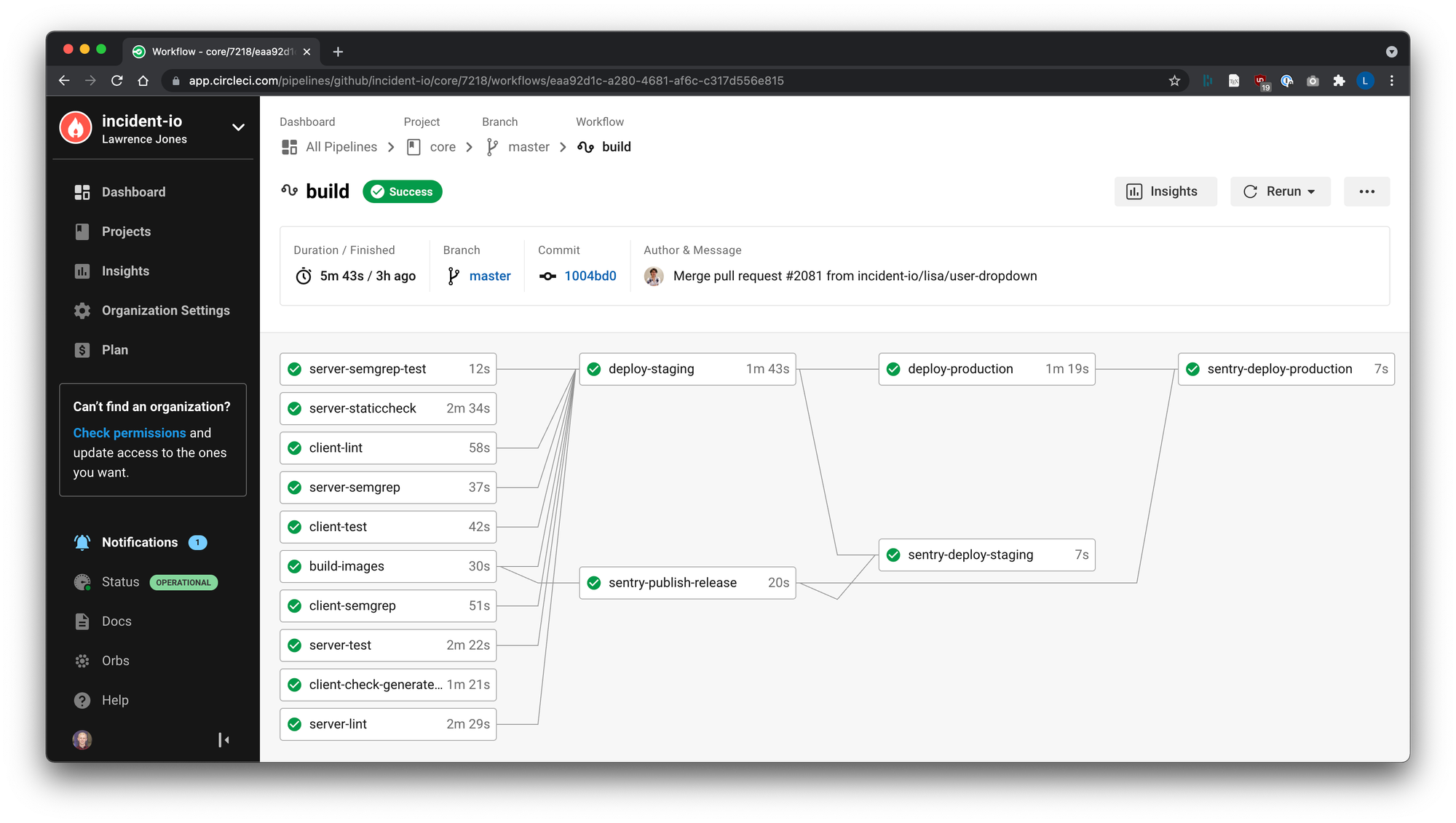
With the worst builds finishing in under 2m, well below the 3m taken by other pipeline steps, we were really happy with these results.
Connecting from CircleCI
Now we're back to super-charged builds, all that remains is hooking it up to CircleCI.
While CircleCI instances won't run in the same network as our provisioned instance, we should be able to connect remotely. Docker doesn't come with any authentication solution, but the client does support connecting to a daemon over SSH.
Provisioning our machine with a builder user, we created a keypair and uploaded the private key into CircleCI. This allowed us to create our own alternative to CircleCI's setup_remote_docker command, which asks CircleCI to provision a Docker builder and load the credentials into your pipeline step.
This isn't much different from CircleCI, it's just our machine is already there to connect to:
# .circleci/config.yml
---
version: 2.1
commands:
docker-setup-remote:
description: >
Configures access to our Docker builder
steps:
- run: |
mkdir -vp ~/.ssh/
echo -e "Host << pipeline.parameters.container_builder_host >>\n\tStrictHostKeyChecking no\n" >> ~/.ssh/config
- run:
name: Configure access to incident.io container builder
command: echo 'export DOCKER_HOST="ssh://builder@<< pipeline.parameters.container_builder_host >>"' >> $BASH_ENV
jobs:
build-images:
executor:
name: golang
steps:
- checkout
# This configures the DOCKER_HOST envvar, which affects
# subsequent docker commands.
- docker-setup-remote
- docker build . && docker push ...
Round up!
Fast builds are a huge quality-of-life improvement, and we're happy to invest in making them a reality.
Honestly, the impact of such a fast CI pipeline is noticeable daily.
This solution won't be perfect for everyone, but I expect it has more mileage than most will realise — GoCardless was still using a single container builder instance when I left, with 200 developers.
If this homegrown solution gets us to 20 developers, I'll consider it a success. And in terms of monetary investment, paying ~£350/month for the machine is a no-brainer if it helps our dev team move faster.
As some quick-links, I've uploaded the terraform used to produce the container-builder image to a Gist for this post. It creates a vanilla GCP instance with a sensible SSH configuration.
You can checkout the that inspired this post, which includes a screenshot of the PR introducing the builder here:
One of the best things about joining a start-up? You can set the bar for a lot of the tech stack.
— Lawrence Jones (@lawrjones) September 17, 2021
We've (@incident_io) found a real sweet spot for observability tooling which we'll share soon, but Friday afternoons are for optimising build pipelines 🎉🚀 pic.twitter.com/g3sZn0kb5I

Lawrence Jones
Product Engineer
See related articles

Don't add a read replica until you've read this
Our learnings from implementing a product-wide read replica migrations, including some useful patterns for routing queries to replica and primary
 Johanna Larsson
Johanna LarssonJuly 21, 2026

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


