3 best PagerDuty alternatives 2025: Incident management platform comparison
November 26, 2025 — 25 min read
Updated November 26, 2025
TL;DR: We see teams switching to Slack-native platforms report 30-60% cost savings and MTTR reductions up to 80%. The coordination tax of context-switching between PagerDuty, Slack, Jira, and Confluence costs teams roughly 15 minutes per incident based on our customer data. With Opsgenie sunsetting on April 5, 2027, thousands of teams are re-evaluating their entire incident management stack. This guide compares pricing, migration complexity, and Slack-native capabilities across the top alternatives to help you choose the right platform for 2025.
Why teams are switching from PagerDuty: Coordination tax and rising costs
Engineering teams are switching to PagerDuty alternatives because tool sprawl is causing inefficient incident management response.
You know this pattern by heart: The incident happens late evening. You're awake, alert, and ready to troubleshoot. But first you spend 15 minutes hunting for the right on-call engineer in PagerDuty, manually creating a Slack channel, copying alert details, pinging service owners, creating a Zoom link, and starting a Google Doc. Your team handles 20 incidents per month. That's five hours monthly spent on logistics before anyone touches the actual problem.
PagerDuty became the industry standard when incident management meant "who do we page?" They mastered alerting in the era when engineers primarily worked via email and phone. But incident coordination has moved to Slack and Microsoft Teams. You now face a structural mismatch: alerts arrive in PagerDuty, but all the actual work happens in chat.
How context switching increases MTTR by 15+ minutes
During an incident, most SREs have seven tabs open: PagerDuty for alerting, Slack for communication, Datadog for metrics, Jira for tracking, Confluence for runbooks, Google Docs for post-mortems, and Statuspage for customer updates. Seven tools for one incident.
Every context switch costs cognitive load during the exact moment when clarity matters most. During incidents, engineers spend more time navigating tools than solving the actual problem.
The cost compounds with team size. A 50-person engineering team running PagerDuty Business at $41 per user per month pays approximately $24,600 annually, before adding required features like AIOps, status pages, and automation. Then add the hidden costs: the engineer hours spent on manual coordination, incomplete post-mortems because timeline reconstruction takes too long, and repeat incidents because learning never makes it back into runbooks.
Opsgenie sunset April 2027: Why teams are evaluating alternatives now
If you're on Opsgenie, your decision timeline just collapsed. Atlassian is pushing customers toward Jira Service Management or Compass. This creates a forced migration for thousands of teams.
This forced migration presents you with a strategic opportunity: instead of moving from one legacy alerting tool to another, you can evaluate the entire incident management category and choose a modern platform. You no longer need separate tools for alerting, coordination, status pages, and post-mortems. We unify these functions in a single Slack-native experience, eliminating the need for separate contracts.
Why real-time support response times matter for incident management
When your production is down at 3 AM, "we'll get back to you in 24-48 hours" is unacceptable. We take a different approach: shared Slack channels with our support team provide real-time help.
"It didn't happen only once when we reported some type of issue in the process to Incident.io support and in matter of hours the fix was released. That shows their commitment to customer success." - Gustavo A. incident.io user on G2
Intercom's engineering team reported in their migration case study that we shipped four features while their previous vendor took time to respond to a single support ticket.
Evaluation criteria for modern incident management platforms
Not all incident management tools solve the same problem. PagerDuty optimized for alerting. Modern alternatives optimize for resolution. Here's how to evaluate them.
Slack-native vs. web-first architecture
A Slack integration sends notifications. A Slack-native platform runs the entire incident lifecycle inside Slack: declare incidents with /inc declare, assign roles with /inc assign, escalate with /inc escalate, update severity with /inc severity, and resolve with /inc resolve. No browser required.
The architectural difference matters for adoption. Web-first tools require training because users need to learn a new interface. Slack-native incident management platforms feel intuitive because they work like Slack, which your team already knows.
Test this during your evaluation: hand a new engineer the demo credentials during their first mock incident. If they can participate without opening the vendor's dashboard, adoption will be smooth.
Unified platform vs. point solutions
The old playbook required five vendors: PagerDuty for alerting, Slack for comms, Jira for tracking, Confluence for docs, Statuspage for customers. We built incident.io to replace all five with a single platform that bundles on-call scheduling, incident coordination, status pages, and post-mortem generation.
The bundling reduces integration maintenance overhead and eliminates data synchronization problems. When the incident closes in Slack, the status page updates automatically, the post-mortem drafts itself from the captured timeline, and follow-up tasks flow into Jira without manual data entry.
Ask vendors: what capabilities require separate products or add-on purchases? Hidden costs appear when "incident management" only covers coordination but on-call scheduling costs extra.
AI capabilities comparison: Root cause analysis vs log summarization
Every vendor now claims "AI-powered" features. Dig deeper. Most AI tools only correlate logs or summarize alerts. That's helpful but not transformative.
Our AI SRE platform takes a different approach: it identifies the specific code change that caused the incident, suggests remediation based on similar past incidents, and can even generate fix pull requests. We automate up to 80% of incident response based on internal benchmarks across customers handling P1-P3 incidents, moving beyond summarization to actual resolution assistance.
During demos, ask vendors to show AI accuracy metrics. "AI-powered" without precision and recall numbers is marketing, not engineering.
Migration complexity and data portability
Switching costs are real. PagerDuty's extensive customization options create lock-in through escalation policies, schedules, and integrations. Evaluate how each alternative handles data portability.
The best vendors provide Terraform importers, API-based data migration tools, and parallel-run support. The worst require manual recreation of all schedules and policies. Plan for a thorough migration with testing, regardless of the tool.
PagerDuty alternatives comparison: incident.io vs Rootly vs FireHydrant
Here's a detailed comparison of the three leading alternatives for teams seeking to modernize incident management in 2025.
Comparison table: Features, pricing, and fit
| Platform | Best For | Slack-Native | Starting Price |
|---|---|---|---|
| incident.io | SRE teams tired of tool sprawl who want to eliminate coordination tax | Yes (deep integration) | $25/user/month Pro + $20 on-call (Team plan is $25/user/month all-in) |
| Rootly | Teams needing escalation logic and some automation | Yes (workflow-focused) | $12,000/year for 50 users (Essentials) |
| FireHydrant | Large enterprises with complex service catalogs requiring detailed dependency mapping | Yes (runbook-driven) | $9,600/year for 20 responders (Pro) |
| PagerDuty | Enterprises requiring maximum alerting customization | Web-first (Slack notifications) | $21-$41/user/month + add-ons |
| Platform | On-Call Included | AI Capabilities | Migration Complexity |
|---|---|---|---|
| incident.io | Add-on ($20/user) on Pro plan | Automates up to 80% of response, root cause identification, PR generation | Low |
| Rootly | Add-on ($20/user Essential) | AI-powered alert grouping and prioritization | Medium |
| FireHydrant | Included in Pro | AI summaries and transcriptions in Enterprise | Medium-High |
| PagerDuty | Yes, but basic features | AIOps add-on required for ML | N/A (baseline) |
incident.io: Slack-native incident management with AI SRE
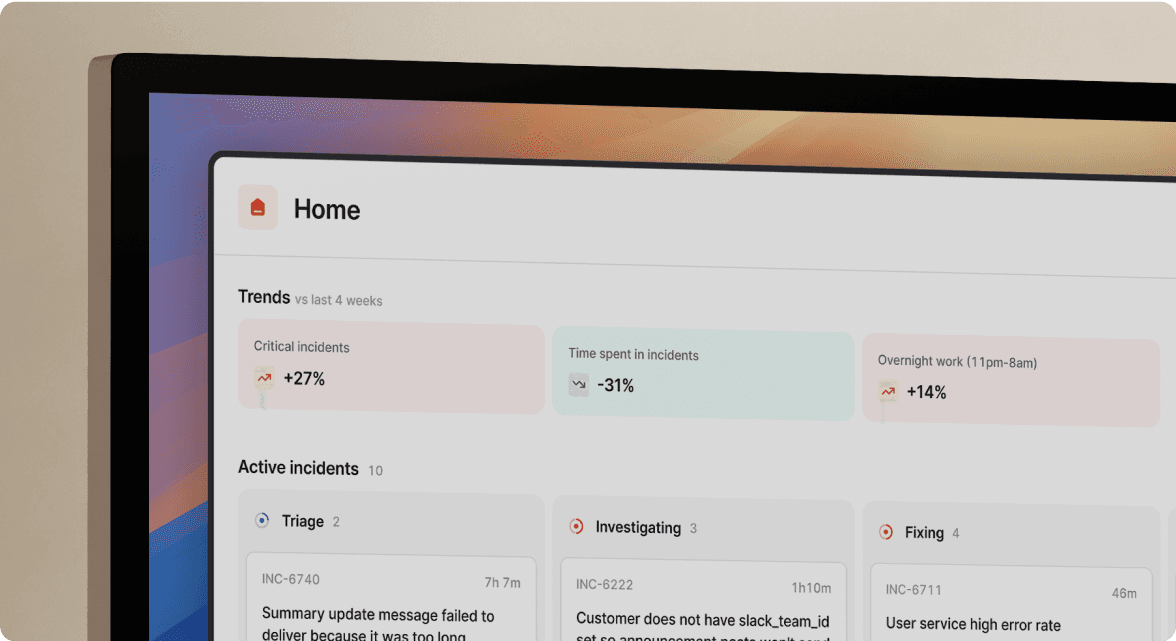
We rebuilt incident management from scratch with one core insight: if your team lives in Slack, incident management should live there too.
Key strengths:
- Complete Slack-native workflow: We run the entire incident lifecycle in Slack. Watch our full platform walkthrough showing declaration, response coordination, AI assistance, and post-mortem generation without leaving chat.
- Support velocity as competitive advantage: We provide shared Slack channels for real-time support.
"The velocity of development and integrations is second to none. Having the ability to manage an incident through raising - triage - resolution - post-mortem all from Slack is wonderful." - Terry A.
- AI SRE capabilities: Our platform's AI can resolve incidents while you sleep, identifying root causes, suggesting fixes, and opening pull requests. We automate up to 80% of incident response, based on internal benchmarks across customers handling P1-P3 incidents.
- Unified platform: We bundle on-call scheduling, incident coordination, status pages, and post-mortems in one tool. No separate contracts for each function.
Pricing reality:
For a hypothetical 50-person on-call rotation, you'll pay $27,000/year for full functionality with our $25/user/month Pro plan plus $20/user/month on-call, totaling $45/user/month. Compare that to PagerDuty Business at $24,600 base, then add $3,000 for status pages, $5,000 for AIOps, and additional fees for advanced analytics pushing total cost to $32,600 or higher.
Best for: Teams of 20-500 engineers who want to eliminate tool sprawl, value responsive support, and need AI-powered incident resolution. Intercom migrated from PagerDuty to incident.io in weeks, not months, and now resolves incidents faster with better documentation.
Rootly: Good incident management
Rootly positions itself as the workflow automation specialist, allowing teams to build complex, conditional logic for incident handling without writing code.
Key strengths:
- Workflow engine: Automation capabilities ingest alerts from any source and automatically declare incidents, assign roles, and escalate based on customizable rules.
- AI-native alert filtering: The platform uses AI to intelligently group and prioritize alerts, reducing noise before it reaches on-call engineers.
- API-first design: Rootly's API capabilities offer extensive programmatic control for teams wanting to build custom integrations.
Pricing:
- Essentials tier: $12,000/year for 50 users as of November 2025
- On-call scheduling: Additional $20/user/month on Essentials tier ($12,000/year for 50 users)
- Scale tier: Custom pricing for larger organizations
- For 100 users: ~$31,374/year based on negotiated pricing data (verify if on-call included)
Best for: Mid-to-large engineering teams (50-500 engineers).
FireHydrant: Enterprise-grade incident management
FireHydrant focuses on providing structure for complex service architectures through its service catalog and runbook automation features.
Key strengths:
- Service catalog integration: Map services and dependencies to provide critical context during incidents, helping teams quickly understand potential blast radius.
- Runbook automation: Create automated runbooks to standardize incident response procedures across teams, ensuring consistent execution even during high-stress situations.
- Alert routing intelligence: Automatically create incidents from alerts using conditional logic, reducing manual declaration overhead.
- Process maturity focus: FireHydrant emphasizes building repeatable, documented processes that scale with organizational growth.
Pricing:
- Platform Pro: $9,600/year for up to 20 responders as of November 2025
- Enterprise: Custom pricing required for larger teams
- Note: Previous "Advanced" tier has been retired; teams over 20 users require custom Enterprise pricing
Best for: Large enterprises and organizations with complex microservice architectures requiring detailed service mapping and standardized runbook execution. Teams that value process documentation and repeatability will find FireHydrant's structure beneficial.
PagerDuty: Current limitations and pricing challenges
PagerDuty remains the legacy provider with a mature feature set and extensive integration ecosystem of over 700 pre-built connectors.
Strengths:
- Highly sophisticated alerting and escalation policies with deep customization options
- Extensive integration ecosystem covering virtually every monitoring and observability tool
- Event Intelligence uses machine learning for alert grouping and noise reduction
- Battle-tested reliability at enterprise scale
Weaknesses:
- Web-first architecture creates context-switching overhead during incidents
- Complex pricing with essential features gated behind add-ons for AIOps, advanced analytics, and automation
- Per-user, per-feature model makes budget forecasting difficult
- Recent platform changes have focused on expanding into broader operations management rather than deepening core incident response capabilities
Pricing:
- Professional: $21/user/month
- Business: $41/user/month
- Add-ons for AIOps, Status Pages, and Runbook Automation push total costs higher
- For 50 users: $24,600+/year before add-ons, potentially exceeding $35,000/year with necessary features
Best for: Large enterprises (500+ employees) with complex, established incident response processes who require maximum alerting customization and can absorb higher costs. Organizations with extensive PagerDuty investment may find migration costs outweigh benefits.
Choosing the right PagerDuty alternative for your team size and needs
Best alternative for teams with 5+ incident management tools
You manage infrastructure for a 200-person engineering organization. Your incident response stack includes PagerDuty, Slack, Jira, Confluence, Statuspage, and custom scripts nobody maintains anymore. Each tool requires its own admin overhead, security review, and training.
You've run enough post-mortems to know the pattern: coordination failures, not technical complexity, drive your MTTR up. The CEO is asking why incidents take longer to resolve now than they did when the team was half the size.
Best fit: incident.io
Why: We offer migration support with opinionated defaults that get you operational quickly. The unified platform eliminates four separate vendors. On-call scheduling, incident coordination, status pages, and post-mortems live in one tool. You'll reduce admin overhead, simplify security reviews, and give engineers a single interface to learn.
"The onboarding experience was outstanding — we have a small engineering team (~15 people) and the integration with our existing tools (Linear, Google, New Relic, Notion) was seamless and fast less than 20 days to rollout." - Bruno D.
Best PagerDuty alternative for teams migrating from Opsgenie
You're on Opsgenie and just learned about the April 2027 sunset. Atlassian wants you to move to Jira Service Management, but JSM is a heavyweight ITSM platform, not a purpose-built incident management tool. You need to migrate but don't want to settle for another compromise.
Best fit: incident.io for speed
Why: We offer migration support with opinionated defaults that get you operational in 2-4 weeks. If you've built extensive Opsgenie automation and want to preserve that complexity, Rootly's workflow engine can replicate it. Avoid FireHydrant for this scenario due to higher migration complexity for large-scale Opsgenie configurations requiring custom Enterprise setup.
PagerDuty alternatives pricing comparison: TCO analysis for 50-100 person teams
The true cost of incident management extends beyond base subscription fees. Calculate total cost of ownership by including: base platform fees, on-call add-ons, status page costs, AI/automation features, API access, and support tier upgrades.
TCO breakdown: 50-user team annual costs
Table 1: Base costs and add-ons
| Platform | Base + On-Call | Add-ons Required | Total Annual |
|---|---|---|---|
| PagerDuty Business | $24,600 | $8,000 (Status, AIOps) | ~$32,600 |
| incident.io Pro | $27,000 | All features included | $27,000 |
| incident.io Team | $15,000 | All features included | $15,000 |
| Rootly Essentials | $12,000 + $12,000* | Status page extra | ~$24,000-26,000* |
*Rootly on-call scheduling costs additional $20/user/month on Essentials tier; status pages require separate vendor
Table 2: Cost comparison with feature parity
| Platform | Total Annual | What's Included | Savings vs. PagerDuty |
|---|---|---|---|
| PagerDuty Business | $32,600 | Base features only | Baseline |
| incident.io Pro | $27,000 | Status pages, AI SRE, post-mortems | $5,600/year (17%) |
| incident.io Team | $15,000 | Status pages, core features | $17,600/year (54%) |
| Rootly Essentials | $24,000* | Incident mgmt only** | $8,600/year (26%) |
Important pricing context: incident.io Team plan ($25/user/month) includes on-call scheduling, status pages, and post-mortem generation which are features that cost extra with other vendors. Rootly's lower base price excludes on-call ($20/user extra) and requires third-party status page integration.
TCO breakdown: 100-user team annual costs
Table 1: Base costs and add-ons
| Platform | Base + On-Call | Add-ons Required | Total Annual |
|---|---|---|---|
| PagerDuty Business | $49,200 | $10,000 (Status, AIOps) | ~$59,200 |
| incident.io Pro | $54,000 | All features included | $54,000 |
| incident.io Team | $30,000 | All features included | $30,000 |
| Rootly Scale | ~$31,374* | Varies by negotiation | ~$31,374-35,000* |
Table 2: Cost comparison with feature parity
| Platform | Total Annual | What's Included | Savings vs. PagerDuty |
|---|---|---|---|
| PagerDuty Business | $59,200 | Base features only | Baseline |
| incident.io Pro | $54,000 | Status pages, AI SRE, unlimited | $5,200/year (9%) |
| incident.io Team | $30,000 | Status pages, core features | $29,200/year (49%) |
| Rootly Scale | ~$31,374* | Negotiated package** | ~$27,826/year (47%) |
Key differences: incident.io pricing includes all features without add-ons. The Team plan at $25/user/month provides exceptional value for teams not needing advanced AI capabilities but Pro is a better fit for larger teams.
Hidden costs beyond subscription fees
Engineer time savings: If Slack-native coordination saves 15 minutes per incident, and you handle 20 incidents monthly, that's five hours reclaimed. At $150 loaded hourly cost per engineer, that's $9,000 annually in productivity gains.
Post-mortem efficiency: Reconstructing timelines from Slack threads and memory takes 90 minutes per major incident. Automated timeline capture and AI-drafted post-mortems reduce this to 10 minutes. For 10 major incidents yearly, that's 13 hours saved per incident commander.
Downtime cost avoidance: Every minute of reduced MTTR translates to cost avoidance. If incidents cost $1,000 per minute in lost revenue, verified MTTR improvements from 45 to 28 minutes save $17,000 per incident. The ROI calculation becomes compelling quickly.
How to migrate from PagerDuty: 8-week migration plan with zero downtime
Migrating incident management platforms carries risk. Production doesn't stop for tool migrations. Here's a proven approach for switching from PagerDuty to a modern alternative without dropping alerts.
Week 1-2: Planning and parallel setup
Planning checklist:
- Audit your current setup: Export all on-call schedules, escalation policies, and integration configurations from PagerDuty.
- Prioritize services: Identify low-risk services for initial migration. Start with your staging environment or an internal tool that pages once a week, not your payment processing service that pages twice daily.
- Establish success metrics: Define what "successful migration" means. Track MTTR, time-to-coordinate, and post-mortem completion rates before and after.
- Set up parallel environment: Configure the new platform alongside PagerDuty. Our on-call setup video shows how to create schedules, configure integrations, and test workflows.
Week 3-4: Parallel run with single service
Parallel run strategy:
- Dual routing: Configure alerts to fire to both PagerDuty and the new platform for one service. This creates redundancy during validation.
- Shadow on-call: Run a "shadow" on-call schedule in the new platform that mirrors PagerDuty. When incidents occur, use the new platform for coordination while PagerDuty handles paging.
- Gather feedback: After 10 incidents through the new platform, survey responders. What works? What's confusing? What's missing?
- Iterate on workflows: Workflow customization allows you to adapt the platform to your team's specific needs during this learning period.
Week 5-6: Expand to additional services
Rollout approach:
- Team-by-team migration: Migrate one team's services at a time. This limits blast radius and allows you to build internal champions.
- Cut over alerting: Once confidence builds, redirect monitoring tool webhooks from PagerDuty to the new platform. Start with non-production environments.
- Training sessions: 30-minute demos are sufficient for Slack-native tools. Show
/inccommands, demonstrate auto-created channels, and walk through a mock incident.
Week 7-8: Full cutover and decommission
Cutover checklist:
- Redirect all alerts: Update webhook configurations in Datadog, Prometheus, New Relic, and other monitoring tools to point to the new platform.
- Deactivate PagerDuty schedules: Turn off on-call schedules in PagerDuty to prevent duplicate pages.
- Monitor closely: Watch for missed alerts or configuration errors during the first week post-cutover.
- Archive historical data: Export incident history from PagerDuty for compliance and learning purposes before canceling the subscription.
Migration complexity factors
Your migration timeline depends on several factors:
Complexity drivers:
- Team size and number of on-call rotations
- Number of monitoring tool integrations needing webhook reconfiguration
- Custom PagerDuty extensions or scripts that need rebuilding
- Complexity of escalation policies and service dependencies
Reducing complexity:
- Start with incident.io for opinionated defaults that accelerate deployment
- Use provided migration documentation and API tools
- Run parallel systems for 2-4 weeks minimum to build confidence
- Migrate one team at a time rather than big-bang cutover
Next steps: Getting started with PagerDuty alternatives
Incident management has fundamentally shifted since PagerDuty's architecture was designed. PagerDuty's alerting-first approach made sense when engineers coordinated via email and phone. In 2025 and 2026, coordination happens in Slack and Microsoft Teams. Modern alternatives like incident.io, Rootly, and FireHydrant built their platforms for this reality from day one.
The financial case is clear: teams save 30-60% on total cost of ownership by avoiding PagerDuty's expensive add-on model. The operational case is equally compelling: Slack-native workflows reduce coordination overhead by 15 minutes per incident, cutting MTTR and reclaiming engineer time for proactive reliability work.
With Opsgenie sunsetting in 2027, thousands of teams face a forced migration. This creates a strategic opportunity to rethink your entire incident management approach rather than simply swapping one legacy tool for another.
Getting started with your PagerDuty alternative
If you want to see the Slack-native difference firsthand: Schedule a demo with the incident.io team. Declare with /inc declare, coordinate with auto-created channels, and watch the AI draft your post-mortem from the captured timeline.
Key terms glossary
Slack-native: A platform built entirely within Slack where you declare, coordinate, and close incidents using /inc commands and channels—not a web dashboard that simply sends notifications to Slack.
Coordination tax: The time and cognitive overhead spent managing the incident process rather than solving the technical problem. This averages 15 minutes per incident based on our customer data.
MTTR (Mean Time To Resolution): The average time from incident declaration to resolution, measured from when the incident is detected until services return to normal operation.
Event intelligence: Machine learning capabilities that automatically group related alerts, suppress noise, and provide context to reduce alert fatigue.
Total Cost of Ownership (TCO): The complete cost of an incident management platform including base subscription, on-call add-ons, status pages, AI features, API access, and support tier costs.
FAQs

Tom Wentworth
Chief Marketing Officer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

