How we do realtime response with incident.io, Sentry & PagerDuty
October 10, 2022 — 6 min read

Like most tech companies, we use an on-call rota and various alerting tools. We do this to respond to incidents before they’re reported. Proactively identifying issues and communicating to customers helps us provide great experiences and fosters trust.
Internally, we’ve been using these alerting tools in tandem with our incident triggers feature. We’ve found that it’s made responding to the pager much smoother - it’s one less thing to do when you get paged at 2am. In this post, I’d like to share how exactly we have it set up.
Overview
As you might have read in previous posts [1, 2] we use Sentry for error reporting & PagerDuty for alerting. When an alert triggers, that integration looks like the following:
- 🆕 An error occurs in our code, and is sent to Sentry
- 📮 Sentry triggers a PagerDuty alert
- 🚨 PagerDuty pages the on-call engineer
- 🕵️ incident.io creates an incident in a triage state for the engineer
- 📎 incident.io attaches the Sentry error and the PagerDuty alert
- 🔧 The engineer confirms the incident, implements a fix and then resolves it in Slack
- ✅ incident.io closes the PagerDuty alert
How?
The core part of this flow is our incident triggers feature. Enabling this feature means that anytime a PagerDuty alert triggers, incident.io creates an incident in a triage state. Triage state is a precursor to a full incident.
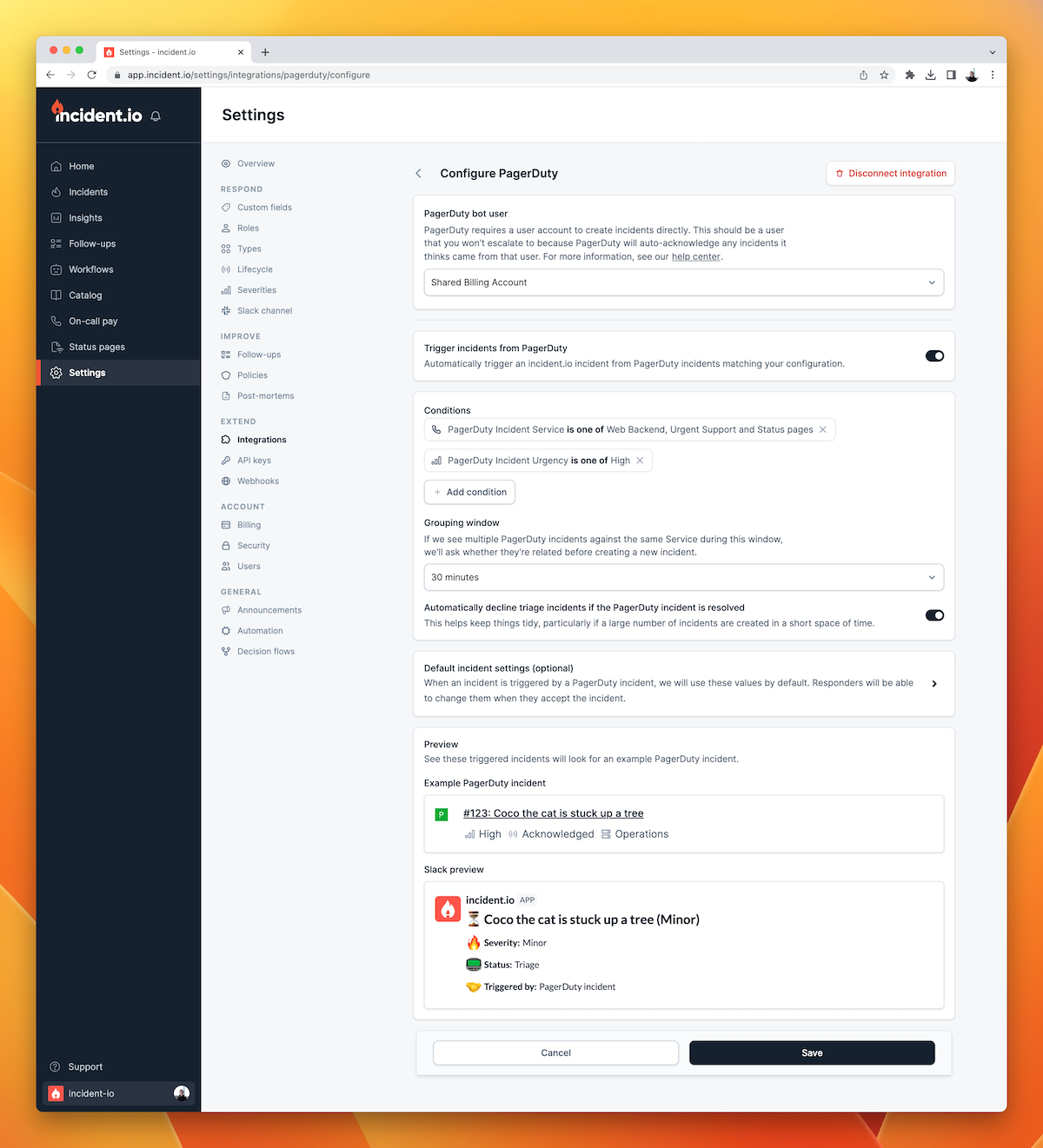
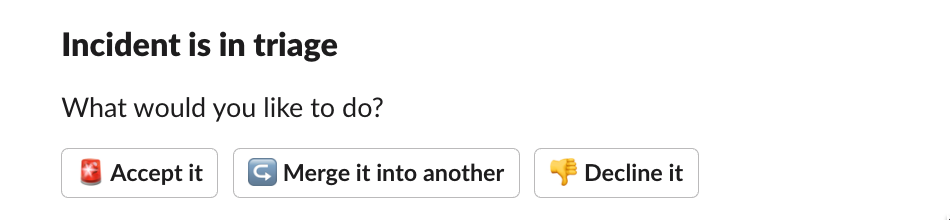
When one is created, you'll get a Slack message with the following options
- Yes this is an incident, create it
- This is part of an existing incident, merge the two together
- No this is not an incident, dismiss it
If you choose to create an incident, you'll get an incident with the PagerDuty alert attached. Additionally, we'll fetch its details from PagerDuty. If we can identify attachments on it - such as the originating Sentry error - then we'll attach them to the incident as well.
If you choose to merge the incident, we'll let you choose an existing incident to merge it into. This means the original incident will receive the new PagerDuty alert as an attachment. When you later close the incident, we'll automatically resolve both alerts in PagerDuty.
If you dismiss the incident, then we'll resolve the PagerDuty alert, we'll archive the generated Slack channel and it won’t appear in your metrics.
To read more about setting this up, see our help center article.
Why?
So we have this setup, but why have we chosen to do it this way?
It gives you one place to go, always
When a PagerDuty alert triggers, you go straight to the incident channel and you have everything you need right in front of you. You’ve got a link to the Sentry error, the Pagerduty alert, and all your usual incident commands at your fingertips. There's no manually keeping track of related alerts, or spending time creating incidents. Instead, there's more time for you to focus on communicating and fixing the issue.

Filtering out noise
When an error occurs and Sentry triggers a PagerDuty alert, we notify an engineer. We also use PagerDuty’s Slack integration to receive updates about those alerts inside Slack. Those updates can get pretty noisy, especially if you have a large outage and everything is stuck in failure loops.
With the incident triggers feature, you get a configurable debounce window per service. So if the same service fails twice within 30 minutes, you’ll only get one incident (and the option to attach non-initial alerts to the incident). This means you can focus on your targeted incident channel and ignore the noise coming from PagerDuty.
Receiving these updates in Slack is useful as it lets people know an alert has occurred and then resolved.
There are however some drawbacks to these PagerDuty alerts. Instead of relying on those messages, we encourage people to follow issues via our incidents channel. Here’s why:
- Sometimes, an alert isn't an incident. By triaging these alerts through an on-call engineer, we can avoid people worrying over non-issues.
- We can streamline communication. By encouraging communication about an incident into an incident channel, it's easier to see what's going on. Having a separate channel for managing an incident vs being alerted about it, means that communication about your incident doesn't get lost in the noise of subsequent alerts.
- We avoid being spammed with repeated failures. The incident triggers feature won't create additional incidents for the same service in a short window. This means if you're getting flooded with errors, your incident channel won't fill up with duplicates.
Eating our own dog food
We’re always looking at how we can improve our product. Part of doing that is using it ourselves and understanding it deeply. Having used the triggers feature extensively, we think it’s a great way to run your incident response process. And, by using it on a day-to-day basis, we’re able to keep on top of points of friction and build improvements into our product roadmap.
I hope you've found this post useful. If you're interested in trying out incident.io, you can sign up for a demo. If you're already a user, and you want to use incident triggers, check out our help center article or reach out via Intercom.

Rory Bain
Product Engineer
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

