The flight plan that brought UK airspace to its knees
December 5, 2024 — 25 min read

On August 28th, 2023—right in the middle of a UK public holiday—an issue with the UK’s air traffic control systems caused chaos across the country. The culprit? An entirely valid flight plan that hit an edge case in the processing software, partly because it contained a pair of duplicate airport codes.
As a safety measure, the system and its backup shut themselves down, forcing controllers to process flight plans manually while technical teams tried to identify and fix the problem.
The result was six hours of downtime, major delays, stranded passengers, and a whole lot of stress — a textbook case study in incident response lifecycle failures at scale. While safety was never at risk, this incident provides a glimpse into the intricate and occasionally fragile world of air traffic systems.
For anyone curious about how these systems work (and why they sometimes don’t), this story is a fascinating case study. Beyond the tech, it’s also a great reminder of how messy incidents can be and why the hunt for a neat “root cause” entirely breaks in complex environments. Let’s dig in!
A primer on air traffic control
As you might expect, air traffic control is a pretty complex business. Before we look at how the incident unfolded, here’s a crash course in the key players and systems behind UK and European airspace management.
Air traffic organizations
- EUROCONTROL: I’ve no idea why it’s all capitalized, but it is. This is the agency responsible for managing the airspace around Europe.
- NATS: Capitalized because it stands for National Air Traffic Service. It’s responsible for managing UK airspace within the broader EUROCONTROL framework. You can think of it as a UK service provider to EUROCONTROL.
Together, NATS and EUROCONTROL ensure safe and efficient air traffic management across overlapping jurisdictions.
Flight plans
Every flight needs a plan, which is basically a blueprint containing essential information like the aircraft type, route, speeds, and callsign.
Airlines operating in Europe submit these plans to EUROCONTROL, which in turn distributes them to relevant air traffic control services. For flights involving the UK, NATS is the recipient of these plans so it has visibility of flights in their airspace.
Dropping a level deeper, because it’s critically important to this incident, it’s important to understand that there are different flight plan formats used by EUROCONTROL and NATS. I’m deliberately sidestepping the reason for this, but knowing it’s a thing is important!
The two flight plan formats
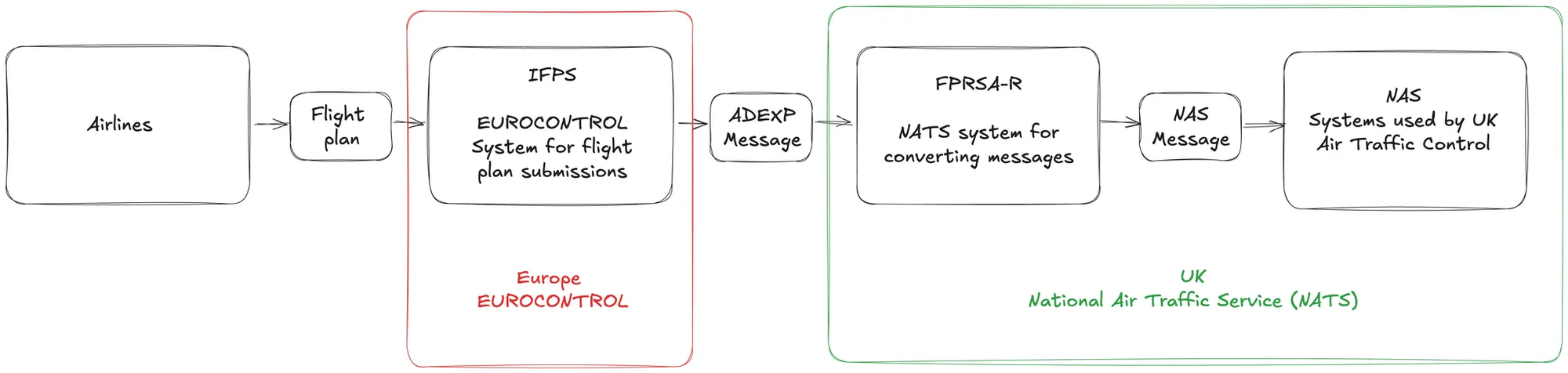
- EUROCONTROL manages flight plan data in a system they call the Integrated Flight Planning System (IFPS). The format of the flight plan message is known as the ATS Data Exchange Presentation or ADEXP.
- NATS on the other hand requires flight plans in a format known as NAS, or National Airspace System.
✉️ What does a flight plan message look like?
In case you’re curious, here’s the (nearly 100 page) specification of the ADEXP message format. There's a lot of ground to cover here.
Between the IFPS and NAS systems there's a sub-system responsible for converting ADEXP messages into NAS messages. It’s a very catchily titled system called the “Flight Plan Reception Suite Automated – Replacement” or FPRSA-R.
ℹ️ A brief history of FPRSA-R
FPRSA-R is an automated system for processing European format flight plans into UK format flight plans. As you might guess, the acronym has grown over the years. Here’s the brief history lesson:
- The Flight Plan Reception Suite (FPRS): This original and predominantly manual system used to convert flight plan messages.
- The Flight Plan Reception Suite Automated (FPRSA): The successor to FPRS, this was introduced in 2004 and used to automate parts of the translation.
- The Flight Plan Reception Suite Automated - Replacement (FPRSA-R): Introduced in 2018, this is the fully automated flight plan conversation system, which has processed tens of millions of flight plans to date.
Since a picture says a thousand words, here’s roughly how these systems all interact.
How the incident unfolded
The 28th of August, 2023 was a public holiday in England and Wales, and one of the busiest days of the year for the UK aviation system. Everything was running smoothly with air traffic control (ATC).
As is normal practice for them on such important days, NATS had implemented a change freeze to ensure no changes were introduced that might impact operations.
Hour 0: The incident begins
At 08:32, an ADEXP flight plan was received by the FPRSA-R system from EUROCONTROL's IFPS system.
Whilst the flight plan was valid and within specification, the FPRSA-R system was unable to process it and hit an exception in the code. One of the reasons for this was the inclusion of two duplicate airport codes: DVL for Deauville, France, and DVL for Devil's Lake, North Dakota, USA. But whilst duplicate codes might seem like the obvious culprit, the system was actually designed to handle such cases.
The actual issue arose from a combination of six specific factors, all of which had to align perfectly to trigger the bug. Perfect storm, anyone? 😅
When the FPRSA-R system failed to convert the flight plan, it shut itself down. The NATS report referred to this process going into “maintenance mode”, where it ceases processing any further inbound messages.
It might seem like an odd choice for such a system, but FPRSA-R was designed this way as a safety mechanism, intended to prevent sending potentially inaccurate data to air traffic controllers.
"the system cannot include logic that would delete or ignore complex problematic data because, for safety reasons, all flight plan data must be processed and understood to ensure that controllers have accurate real time information on aircraft they are tasked to control at their workstations."
As you might expect, the FPRSA-R system was designed to be fault tolerant, with an isolated backup system running as a hot standby, ready in the event of a chronic failure of the primary.
But because the backup system runs “hot”, it too had processed the bad “DVL” message, and as a result also shut itself down into maintenance mode.
ℹ️ Could the bug have been reasonably predicted and avoided?
For those of your asking “why didn’t they think about duplicate waypoints when writing the software?”, it turns out there was a lot more to the bug.
Specifically, the following six factors all had be present in the flight plan segment of the ADEXP message, in order to trigger the issue in the flight plan processing software:
- The intended flight route including duplicate waypoints.
- Those duplicate waypoints both being outside of UK airspace and on either side of UK airspace
- One of the waypoints needs to be near to the UK airspace boundary exit point, in order to be eligible for potential use by FPRSA-R search logic.
- The first duplicate waypoint needs to be present in the flight plan segment of the ADEXP flight plan message.
- The second duplicate waypoint (the one near the UK FIR exit point) needs to be absent from the flight plan segment of the ADEXP flight plan message.
- The actual UK exit point needs to be absent from the flight plan segment of the ADEXP flight plan message.
I think this statement from the report is pretty accurate: “[the testing] was reasonable based on the premise that it is impractical to test every single scenario within complex systems”.
In under 20 seconds from receipt of the bad message, both FPRSA-R systems were offline, preventing any automated processing of flight plans.
Fortunately, the system had an additional resilience measure in place: 4 hours' worth of previously filed flight plans—thousands in total—are stored in the NAS system, allowing operations to continue temporarily during such disruptions.
But since flight plans often change (sometimes while planes are mid-flight) the stored plans become outdated quickly. And when it comes to safety, having up-to-date plans is pretty important.
To address this, NATS has a mechanism for manual entry of flight plan data. While effective in emergencies, manually inputting plans is both labor-intensive and requires skilled staff to manage, which drastically reduces the number of plans they can manage.
Hour 1: Initial engineering investigations begin
The Level 1 engineers of the Service management command centre (SMCC) received alerts immediately after the automated flight plan processing stopped.
ℹ️ Support Levels
Levels range from 1 to 4, with 1 typically being lower skilled engineers responsible for executing well trodden run books to tackle common issues across many systems.
Level 4 are the most technical and specialist subject matter experts (SMEs), responsible for individual systems.
The team began their investigation into the failure, and 27 minutes later they decided to follow protocol and reboot the FPRSA-R systems.
At 09:06, after failing to bring the system online, they escalated the issue to a Flight Data Processing (FPD) Level 2 engineer; someone with more detailed expertise on the specifics of the FPRSA-R system. As it was a public holiday, this engineer wasn’t on site, and consequently had to be dialed in as a “remote hands”. For the uninitiated, this essentially means they’re working entirely through the on-site L1 who’s pushing all the buttons.
At 09:23, 51 minutes into the incident the L1 team notified the on-watch air traffic controller in Swanwick, and shortly after, an SMS message was sent by a duty service manager to the major incident managers group, warning them of the potential for the escalation of a major incident.
Interestingly, from the perspective of the L1 team, this was still not yet deemed to be a major incident.
Hour 2: Reducing air traffic capacity whilst trying to fix the system remotely
The on-site Level 1 engineering team continued to work on the issue, assisted by the remote Level 2 engineer.
By 09:35, members of the NATS executive team—including the Technical Services Director, Operations Director, and CEO—were briefed on the situation. They weren’t yet running the incident, but they would be required to decide if and when to escalate to the highest level of command.
At 10:00, a meeting in the NATS operations room led to a key decision being made: the introduction of “regulations” to limit the number of planes allowed in UK airspace, or network capacity as it's known. After discussing the situation, they settled on reducing capacity to 75% of the normal demand which is usually around 800 flight plans per hour.
By 10:12, all initial attempts to resolve the technical issue had been exhausted, leaving the only option as a full hardware reboot of the FPRSA-R system. However, this posed a logistical challenge: on-site Level 1 engineers aren't authorized to perform the restart, and the Level 2 engineer couldn’t do it through a remote hands procedure. The only option was for the Level 2 engineer to travel to the site immediately.
ℹ️ Incident response command and control structure at NATS
As part of their incident response, NATS runs a Bronze, Silver and Gold command and control structure.
- Bronze typically involves those close to the system or issue dealing with the incident themselves.
- Silver layers on an additional level of tactical management
- Gold is brought into effect when “strategic direction” is required – things like the CEO needing to make a call.
Hour 3: Escalations of incident response
At 10:38, the "Bronze" response team was convened to discuss the incident, and make decisions on whether they should escalate to Level 3 specialists for the FPRSA-R system.
At 11:06, the "Silver" team also met to step up coordination efforts, and by 11:30, they called in the support of ATICCC, who are the Air Traffic Incident Communication and Coordination Cell. ATICC is essentially a specialist group who manage communications across email, video calls, text messages, and the NATS website. They're responsible for keeping airlines, airports, government agencies, regulators like the Civil Aviation Authority, and EUROCONTROL informed of ongoing developments.
Hour 4: Continuing to dig into the technical issue whilst escalating the incident severity
Several key events unfolded in parallel during this period. The Level 2 engineer was en-route to the site to perform a full system restart, but with it being a public holiday, they were heavily delayed by traffic on the roads. Meanwhile, at 11:47, the ATICCC held its first customer call, keeping stakeholders updated.
At 11:53—three hours and 21 minutes into the incident—the on-site engineers had escalated to the Level 3 SME. By this time, the Level 2 engineer had arrived on-site and spent 35 minutes attempting to reboot the FPRSA-R system. Unfortunately, none of these attempts was successful.
At 12:20, NATS activated their "Gold" team to oversee the response. Simultaneously, UK-wide air traffic regulations were tightened further, reducing airspace capacity to just 60 flights per hour—around 7% of normal levels—causing major delays and cancellations for passengers.
The technical investigation continued, with the "Bronze" team and the Level 3 engineer diving into detailed system log analysis.
Remember that 4 hour buffer of stored flight plan data when the FPRSA-R system first went down? That was fully exhausted at 12:32, meaning the safe processing of UK airspace flight plans was entirely reliant on manual input.
Hour 5: Escalating to the software manufacturer and bringing the system back online
The Level 3 engineer found a log message linked to the failed message processing. But they'd never seen this error before, and since they hadn’t been involved in the software’s development (reminder that the system was built by an outsourced vendor) they decided it was necessary to escalate further. Five hours into the incident at this point, and only just at the point where an engineer from Comsoft who worked on the system was being escalated to.
Within this hour, Comsoft’s Level 4 engineer identified that the problem stemmed from a "bad" flight plan message, though the exact cause of the failure remained unclear.
What they did know, however, was how to mitigate it. So between 12:51 and 12:58, they worked together to isolate the offending plan and unblock automated processing.
At 13:00, with manual data entry still the only option, air traffic regulations were tightened further, reducing capacity to just 30 flights per hour—about 4% of normal operations. By 13:26, after resolving a separate issue involving system databases during the startup process (it never rains but it pours!), the FPRSA-R system successfully processed a batch of test flight plans, marking a small but crucial step forward.
Hour 6: System operational again
With a few test flight plans successfully processed, the support teams started assurance and data integrity tests to ensure the issue had been genuinely resolved and the system was indeed stable.
By 14:27, the FPRSA-R system was back to full operation, automatically processing flight plans again. Whilst this marked the end of the technical component of the incident, the focus shifted to the operational recovery and unwinding the backlog of disrupted flights.
Wrapping up the incident
Seven hours after the incident first started, final calls happened between Silver and Bronze response teams, which were then stood down. With these folks predominantly aligned to technical recovery, this made sense.
The Gold team continued to manage comms, working with ATICCC, whilst air traffic regulations were eased and then removed. By 18:03, all regulations were removed and UK Air Traffic resumed normal operation.
For airlines and their passengers, the disruption obviously continued for some time longer, though the report doesn’t highlight this in detail.
What the NATS incident report concluded
Key findings and improvements
- The software bug could not have reasonably been predicted and prevented, citing it as being “extremely rare”.
This feels like a pragmatic and honest assessment. Very often, incident reports claim that the issue could have been avoided if only the “right things” had been done—often to reassure stakeholders. It’s refreshing to see a straightforward acknowledgment in the wake of such a significant event, rather than a shallow attempt to restore faith. - The system requirements that NATS shared with Comsoft included a “logical approach to processing flight plans” which would have dealt with the issue.
In short, it was the translation from the “logical approach” to code that introduced the bug. They also go on to say there’s no concrete recommendation here as it’s impossible to prevent every bug, and that they will try harder to do things right when building in future (I’m paraphrasing). - The command structure for incidents contributed to the slowness in response: joint decision making with various teams and hierarchies all at play meant there was “no single role accountable for oversight of the entire incident”
They don’t suggest any specifics around improvements, but made a recommendation to review alternatives and make an active choice as to whether the current model is a good fit. For what it’s worth, I think this is the ideal way to handle incident actions: don’t commit to specifics without the right information, but take an action to investigate further. - They were too slow at escalating the incident, and finding the right people to get hold of was too hard.
It doesn’t sound like there was any formalized process in place to trigger escalations, which put the responsibility on those responding to the incident. As a result they ended up escalating in series: L1 escalated to L2, and L2 escalated to L3. This is a surprisingly common problem, as those responding to issues rarely have the presence of mind to think more broadly about an incident when they’re focused on mitigation. - Their systems are really complex, with "complex architectures, regular upgrades and out of date system mappings" — the environment where incident response automation pays for itself most clearly.
I’ve worked in very large IT organizations, and I can imagine they’re only a fraction of the complexity of the NATS systems. Despite this, I think this does raise important questions around more dynamic cataloging of systems and configuration. - Only operational teams are formally trained in incident management processes.
The (many) other functions involved in responding to the incident had no formal and limited operational exposure to incidents. This included on-call engineers, subject matter experts and other individuals. All of whom likely felt entirely out of their depth working in this manner. - And a grab bag of smaller findings and contributors to the incident severity:
- Being a public holiday made this much worse: more flights were impacted and road congestion getting to sites increased the overall recovery time.
- They tried to coordinate comms on a teleconferencing system called LoopUp, and it was proving very unreliable with poor audio quality. This made communication and coordination considerably more difficult.
- There were no pre-approved comms for operational folks to use, so communications with airlines and other customers was slow and non-specific.
- The computers used by ATICCC all required updates installed before they could be used to handle comms. Despite their importance, there’s no process in place to keep these up-to-date.
Positive outcomes
It’s always nice to see positive outcomes discussed in incident reports too. Here’s a few of the things they concluded in the wake of this incident:
- At no point in the incident was the safety of passengers and crew compromised. It’s not often that we have to think about these kinds of outcomes in technology incidents, but it’s a stark reminder that behind some systems can be serious human impact.
- UK airspace remained open throughout the incident. It wasn’t operating at full capacity, but speaks to the system resilience that manual input processes allowed a reduced rate of flights into and out of the UK.
- Many people worked over-and-above any contractual obligations, highlighting a strong culture and far-reaching sense of responsibility within the organization.
- The processes that had been defined had been followed well, though as indicated in the findings above, these procedures felt sub-optimal in the context of the overall response.
- They implemented a larger set of test scenarios for FPRSA-R in the wake of the incident, improving the resilience of the system.
Generalized takeaways we can all learn from
1. There is no root cause
Incidents like this remind us how elusive the idea of a singular “root cause” can be. Was it the bad flight plan that set things in motion? The bug in the software? A lack of comprehensive testing? Or perhaps the way the system handled—or didn’t handle—exceptions like this?
Pinning down a single cause is actively unhelpful when it comes to exploring and learning across the breadth of an incident. Instead, it’s far more useful to recognize that incidents typically result from multiple contributing factors, and taking the time to explore them thoroughly.
When we focus too narrowly on one “root cause,” we risk losing valuable opportunities to learn from the broader picture.

2. Establish escalation procedures
Clear, objective criteria for escalation can make all the difference during an incident — including proper incident routing to page the right people without delay. Whilst it might seem heavyweight and unnecessary, but this can take the burden of decision-making off responders, speeding up your overall response.
Equally important is the culture around escalation. Encouraging teams to escalate early—and de-escalate if needed—creates a safety-first mindset, ensuring that hesitation or caution doesn’t make a bad situation worse.
In the context of this incident it took more than 5 hours to escalate to an engineer close to the system, who was then able to diagnose and restore the issue within 2 hours.
If in doubt, escalate.
3. Assign a single lead for your incidents
Incidents with many moving parts often benefit from having a single-threaded lead — this is the core responsibility of a skilled incident commander.
While teams, hierarchies and individuals with specialist knowledge will exist beneath them, having one person who maintains an overarching bird’s-eye view ensures consistency, alignment across domains, and faster decision making.
Without this, decisions risk being fragmented or delayed, especially in complex systems.
4. Prepare comms plans ahead of time
Nobody wants to scramble for the right words during an incident — reviewing incident communication best practices before things go wrong is the only way to avoid it. Pre-approved communication plans, key contact lists, and templated messages can save everyone time and stress.
Not only do they make life easier for responders, but they also improve the experience for customers, keeping them informed clearly and quickly.
5. Resilience is both technical and social
This incident is a textbook example of why resilience is about more than just systems. Technically, FPRSA-R showed resilience by falling back to maintenance mode and retaining manual input capabilities.
Socially, this was a story of people stepping up—working outside normal hours, flexing established procedures, and finding creative ways to keep things moving.
Resilience isn’t just about anticipating failures; it’s about being prepared to adapt when they happen.
6. Training everyone on incidents is beneficial
Game days aren't just for operational teams — they're part of building a culture of incident response that makes everyone capable when it matters. Anyone who might find themselves involved in a real incident—be it engineers, communications specialists, or execs—needs to be part of the practice.
Nobody should walk into their first incident without prior experience of the process, and game days or table-top exercises are a great way to exercise those muscles.
Curious about how to do this well? Check out this talk from Slack at SEV0 or explore our table-top exercise guide.
7. Map your systems and suppliers
Having a single, up-to-date source of truth for your systems and suppliers is invaluable during an incident. The original NATS reports cites the myriad of documentation, missing contact details, and overall lack of system understanding as a major contributor to the severity of this incident.
Digging through outdated documents, or hunting for answers in Slack or Teams, wastes precious time. Under pressure, quick access to accurate information can be the difference between a smooth response and a prolonged crisis.
8. Incident reports help us all get better
One of the most powerful tools for learning improvement is sharing what went wrong and how you fixed it.
Kudos to NATS for publishing such a thorough report. It’s a great asset for the broader industry (and nerds like me), offering lessons we can all apply.
Normalizing the sharing incident reports is a net positive for everyone. A rising tide lifts all ships, as they say.
If you've made it this far, congratulations. Hope you enjoyed the read, and feel free to share it around!

Chris Evans
Co-Founder & Field CTO
I'm one of the co-founders, and Field CTO here at incident.io.
More from Learning from other fields


So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


