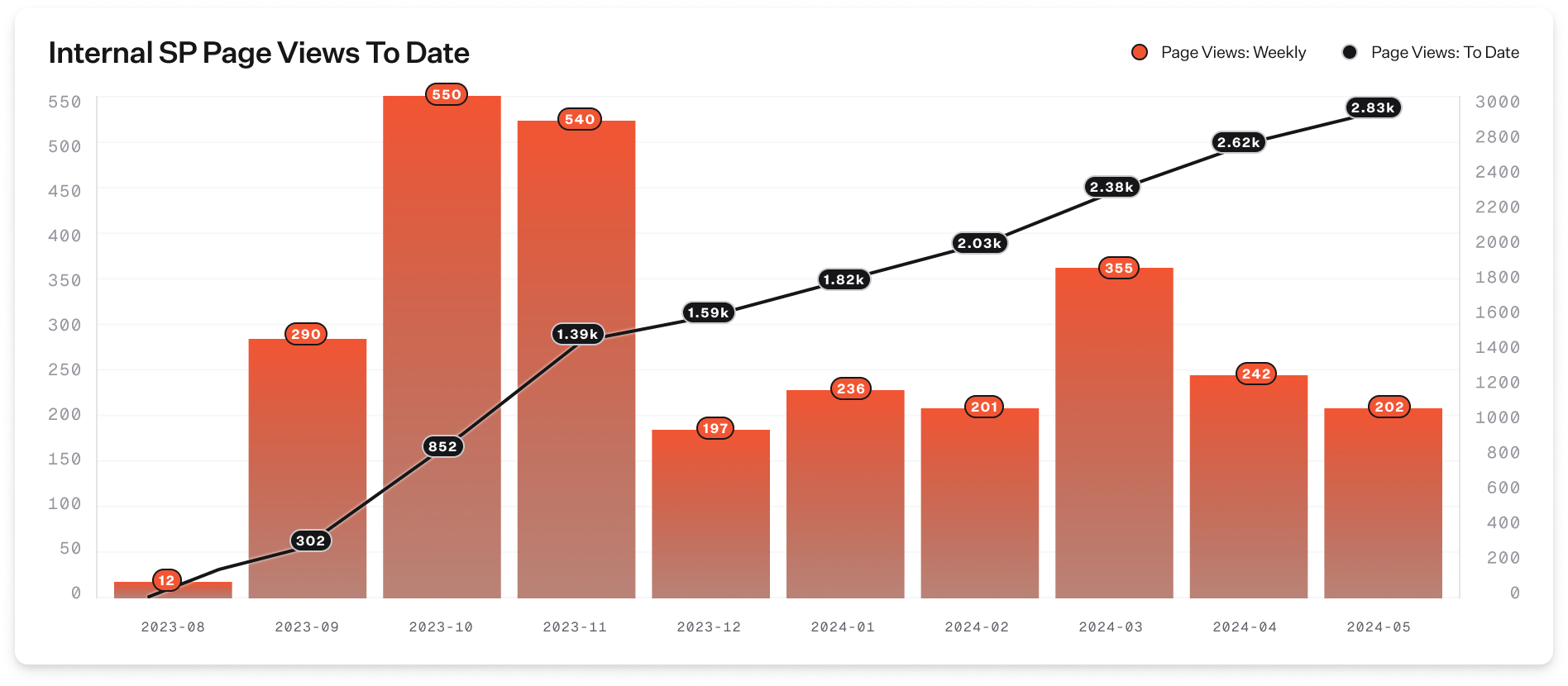
Scaling incident management processes can present massive challenges for an organization as large and complex as Netflix.
With so many different teams and unique use cases for each, having a shared process for responding to incidents not only becomes a must-have but is critical to maintaining high levels of reliability that users can rely on. And for Netflix, whose brand has become synonymous with dependability, there’s a lot at stake.
Unfortunately, Netflix's solution of Jira and Slack made it difficult to achieve one of its primary goals: creating a “paved road to incident management.” For them, adopting incident.io was motivated by a desire to reach this elusive goal, democratize access to incident management, and create consistency at scale.
But usage and adoption haven’t been limited to a single, isolated function. Since its introduction to a specific set of Netflix teams, incident.io has been organically adopted across Netflix Engineering, highlighting just how indispensable and impactful the tool has become.
And yet, that’s just the tip of the iceberg. With tens of thousands of entities stored in Catalog, covering everything from teams to hardware devices capable of running Netflix, the team has quickly become a power user.
And the results have been game-changing.
From Jira and Slack—life before incident.io
As a Staff Site Reliability Engineer at Netflix, Hank Jacobs’ CORE team has a critical responsibility: make sure Netflix works for nearly 300 million users, 24/7/365. Part of that involves providing capabilities to the rest of Netflix, including incident management.
CORE stands for Critical Operations and Reliability Engineering. We’re tasked with ensuring our members are able to do what they pay Netflix to do—stream movies and TV shows
But when Hank joined the team, he noted one issue: while Netflix’s incident management program was mature, the way they ran it was reminiscent of a time when Netflix was much smaller.
“We actually operated in a single Slack channel,” says Hank.
Early on, this sole channel was a strategic decision. The thinking was that by having the engineering team respond to any incident in a single channel, they’d be resolved faster.
“We’d seen a lot of value over the years from having thousands of engineers hanging out in that Slack channel. And when they saw something happening, they’d get involved, especially if it was within their domain and they had information to provide or mitigations to implement,” says Hank.
While Jira and Slack were working, it was clear that the UX and tacit knowledge required to run incidents well wasn't going to scale to thousands of Netflix engineers, many of whom had limited experience in this area. It became clear that they needed a solution specifically tailored to their challenges.
The paved road to incident management
As they continued to mature and experience various types of incidents, the CORE team realized that there was much more potential for different ways to deal with everyday incidents. And Slack alongside Jira—their go-to stack for kicking off incidents—wasn’t the ideal solution.
While this combination worked when Netflix was smaller, it was proving nearly impossible to scale with the complexities of their organization today.
Over the past two years or so, we realized that big outages are only the tip of the iceberg when it comes to incidents at Netflix. Sure, we’re focused on customer-impacting and large-scale incidents. However, smaller incidents happen every day.
“And as we were onboarding new folks, it became abundantly clear that the bias of tenure puts these blinders on. In reality, the ergonomics of Jira for declaring and managing an incident just weren’t there. You're bleary-eyed, looking at graphs, and focused on things that are of immediate importance. All while having to fiddle with the UX of a tool that's not meant to manage incidents. All of this just made it that much harder at the moment.”
Most critically, these challenges prevented Netflix from achieving one of its biggest goals: creating a “paved road for incident management” that made it easy for anyone to raise and run an incident consistently and safely.
To achieve this, they needed a platform that checked a few critical items off their list:
Enable them to democratize incident response. To do this, they prioritized platforms with a seamless user experience that made incidents simple to manage, even at 3 AM, and for first-time responders
With the CORE team historically responsible for nearly 90% of all declared incidents across Netflix, they wanted a platform that allowed teams across the organization to be responsible for their own incidents
And finally, they wanted a solution that allowed everyone at Netflix to “speak in a language that made sense to them.” This meant a tool that could be deeply embedded into all of its services, where all the context someone needed to run an incident was there—teams, impacted areas, and more
If they were to achieve this “paved road,” a platform that was easy to use and scale would be absolutely necessary.
Building in-house wasn’t a viable option
Like many companies, Netflix considered building instead of buying, and understandably so. With one of the most highly regarded engineering teams in the world, there’s no doubt they have the skills. But the cost of building, combined with the cost of ownership of such critical software made neither financial nor practical sense.
“When you look at the focus of my team, it's pretty broad. We're a small team, so our work is cut out for us. And when it comes to building, that is an approach. However, it takes a bunch of investment. It takes more than just two or three engineers,” says Hank.
Especially when you consider it needs to be reliable during times of crisis.
Recognizing the overall importance and criticality of this tooling, it was clear that finding a software solution was the answer.
User experience played a huge role in the decision
Staff Site Reliability Engineer Molly Struve worked alongside Hank during the evaluation process.
“Multiple options on the market had the capabilities we were looking for in an incident management tool. It all came down to the design and UX when evaluating which one was the right fit,” says Molly.
For a company as large and distributed as Netflix, adoption and consistency at scale was always going to be a challenge. So for Molly and the team, it was essential to find a product with a user experience that felt intuitive and familiar, regardless of who was using it and how often it was used.
The intuitive design of the tooling was the biggest selling point for us. What stood out about incident.io was that you hardly had to explain it. The tool, through its seamless UI, allowed you to discover the features you needed. This was critical because our largest internal market is engineers who are not experts in incident management.
But beyond the platform, the user experience and the improvements it would enable, the working relationship with the incident.io team played a significant part in the decision.
“The people played a big role. During the process, I was juggling a lot of other responsibilities in addition to driving our build-or-buy decision, and incident.io gave me the space to do that and was not pushy. There was a genuine sense that if we went with incident.io, we would be partners working together to shape this tool. That was huge. At Netflix, we come with lots of opinions. Seeing that engineers at incident.io were energized by this was pretty special.”
Wide adoption and cultural change
With the decision made, Hank, Molly, and the CORE team rolled out incident.io. They’d soon learn that this decision would not only pay dividends, but adoption would quickly grow well beyond their team.
And with wide adoption, cultural changes were seen too. Incidents of all severities became something that were talked about more openly across the organization, enabling learning and understanding at scale.
“I think a change that immediately jumps out in my mind is we talk about incidents way more across engineering. And I think that's something that was probably more localized before. And then you'd have the big one that folks heard about at the water cooler or saw on the news” says Hank.
“But by and large, outside of those, you couldn't go to a channel and say, ‘What are the incidents various teams are dealing with?’ We have that now, which is really cool.”
This tool makes me want to have incidents.
Thanks to this increased visibility, Hank, Molly, and the CORE team can pursue another goal: facilitating a culture of learning and continuous improvement.
“I can click into any incident and read up on what happened. My team, who sits at a 10,000-foot view, can say, ‘Hey, that looks very similar to this other incident from this entirely unrelated team. We could probably address it at a platform level by implementing safety guards here or a system check there.’ And so that's where the real power comes in.”
What I love about incident.io is how simple, jolly, and less intimidating it makes the response.
While usage of incident.io started in Hank’s CORE team, adoption of the platform has quickly grown across the Netflix engineering organization, and is showing no signs of slowing.
Catalog—speaking in a language that makes sense to Netflix
For Hank and the Netflix team, one feature in particular has stood out for its impact: Catalog.
Catalog allows teams to bring their organizational context such as teams, software services and business domains all under one roof. And by connecting entities together, incidents can be fully contextualized, and powerful automations can be unlocked.
For a company as complex and intertwined as Netflix, Catalog has had a significant impact, allowing them to bring information from their service catalog, details about AWS regions they’re operating in, as well as thousands of hardware devices that run Netflix.
The ability to bring in Netflix-specific context into the tool—Netflixisms, service names, those sorts of things—and have them appear in the product was, for me, a pivotal moment and something that I haven't seen any other vendor provide
Understanding how thousands of users declare and run incidents at scale is no easy feat. However, by building a hierarchical mapping from incident.io users to specific engineering teams and services with Catalog, Netflix leaders can easily see which teams and organizations are reporting and managing incidents that affect their services. And, when incidents do get declared, the right teams can quickly and automatically be looped in, reducing the amount of time they run for.
Even before onboarding, Hank realized just how much potential Catalog had. But this early excitement for Catalog wasn’t short-lived; it’s only grown since then. As a case in point, Netflix now has more entities in its Catalog than any other customer at incident.io. Tens of thousands, to be precise.
“Netflix is the biggest user of Catalog? I'm not surprised just because I've leaned in where it makes sense. And this goes back to speaking in a language that makes sense to the Netflix engineer and providing them similar terminology seen in other internal tools,” says Hank.
It’s helped unlock better automation. We've done cool things where an alert fires, and we automatically create an incident with the appropriate field set using Catalog that maps to our systems. And through that, we can integrate with internal systems that flag developer-impacting incidents
The icing on top? Catalog Importer which allows organizations to sync data from any source into Catalog.
“We run the Catalog Importer to sync all our services into incident.io. That provides a field that is always up to date with the services within the Netflix ecosystem. So as teams create incidents, they can attribute the incident to one or more services either contributing impact or related in some way,” says Hank.
That allows teams to better understand how their services are involved in incidents, and it's all kept up to date by the Catalog Importer. So, as engineering teams spin up new services, they automatically show up in incident.io.
Internal status pages
The interface between teams
Status pages are a key part of the incident.io platform. Normally used to communicate service-impacting issues with external customers (like we do here), Netflix recognized the power of incident.io internal Status Pages to help with team-to-team communication.
With a few clicks, teams are able to select their responsible domain areas, services and functionalities from their Catalog and create a tailored view of their domain.
“Engineering teams have better communications with their stakeholders during an incident,” says Hank.
“They can provide a Status Page so their stakeholders can monitor themselves. They can subscribe through their own announcement rules, you name it. You can tap into incidents that are of interest to you. So you don't need a fire hose. You can filter to what's meaningful to your slice of Netflix.”
Netflix has 25 internal Status Pages—and growing. These give service-owning teams increased visibility and opportunities for collaboration.
“Our data platform team manages almost all things data, from storing, manipulating, and querying data; so their offering is pretty wide-ranging, and they have a lot of stakeholders across the company,” says Hank.
They've recently adopted incident.io and switched to it from a bespoke, hand-rolled Slackbot. In doing so, they unlock Status Pages, which they can break down by product offering. But they’ve also done cool things like hooked it in our internal banner system, so when they file an incident, it shows up in the UI of these data offerings.
Adoption and customization at scale
Being boxed into a static incident management platform was not going to work long-term for an organization as large and complex as Netflix. With incident.io, the Netflix team has the power to create a bespoke incident response experience while retaining consistency across the organization. What does this look like in practice? Shared language and concepts.
“This would be a shared tool across many teams within engineering,” says Hank. “So we had to come up with a strategy not to have islands of incident management.”
One of the ways they’ve been able to avoid this? Common incident metadata that allows for consistent attribution of impacted areas and domains.
“My team's focus is on availability and reliability. So, we wanted something that provided a holistic view into availability impacting incidents across engineering. We came up with this concept of impacted areas and domains.”
Creating custom fields powered by Catalog allowed a domino effect once incidents were declared. If a responder specified a certain impacted area, a whole host of fields would appear underneath to create better clarity and specificity, enabling the right teams and processes to follow.
The needs of Netflix streaming are very different from the needs of some of our internal systems. They're equally important, but they have very different characteristics, especially when it comes to availability and reliability. And this paradigm has allowed us to separate that, but still have that holistic view of Netflix.
A partnership with a shared purpose
Early in their evaluation journey, Hank and the Netflix team stressed the importance of not only finding a mature platform but also a company that was committed to growing with them.
In incident.io, they’ve found exactly that.
I'm talking with various folks at incident.io within a shared channel pretty much daily. And it's a very symbiotic relationship where I'll flag bugs and help identify sharp edges of the product
“I'll say, ‘Wouldn't it be nice if it did X, Y, and Z,’ and then I'll wake up the next day, and in some cases, it'll be implemented in the product. That's just amazing. And it's not just for Netflix's benefit. I think that's what I appreciate the most.”
But it’s not just the quick response times and attentiveness that have stood out. It’s the fact that the product team at incident.io has experience and opinions on what good incident management looks like. This has lent itself well to the partnership Netflix was seeking all along.
In incident.io, they don’t simply have a vendor who accommodates their requests quickly but a partner who is willing to share ideas, collaborate, and build a better incident management process together.
“It's this kind of brain trust. The expertise that incident.io provides, the product focus, understanding our perspective, but also bringing your own,” says Hank.