Learning flow
June 27, 2023

Once the initial fire of an incident has been extinguished, its common for responders to spend time learning about what went wrong and improving their resilience.
Perhaps they write a postmortem, schedule a debrief or create follow-up items. We’ve found from speaking to lots of our customers that the exact process differs based on the company, the team and the incident. Generally though, this process is a little ad-hoc and it’s often hard to know what needs to be done.
That’s why we built the learning flow. A fully configurable process for once an incident is over, which we help you run using either pre-baked tasks, or your own, which you can define. It helps you communicate what stage an incident is in after it’s been resolved, as well as who’s working on what and it’s available to all users from today.

So how does it work? Next time you go to close an incident, we’ll ask whether you want to run the learning flow before closure. If it’s a high severity incident, you might choose “yes” and we’ll move the incident to the first learning status, and post the tasks to be addressed during that stage.
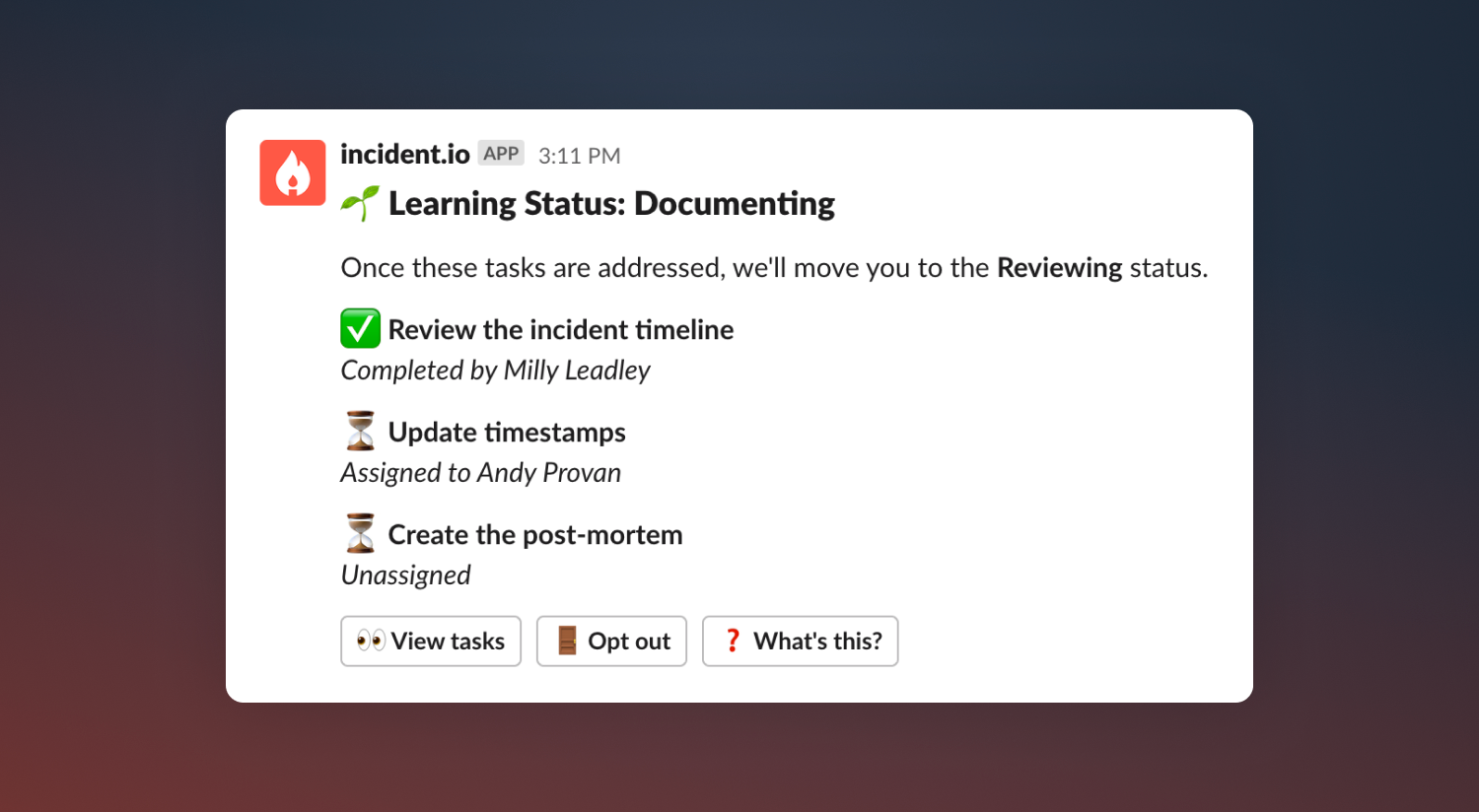
These tasks can be assigned to particular users. When you complete a task within incident.io (e.g. Create the post-mortem), we’ll automatically check off the task for you. Others tasks (e.g. Update timestamps) can be checked off manually or skipped if they’re not relevant to the incident. Once all the tasks have been addressed we’ll automatically move the incident to the next status, which could be another learning status, or it could be Closed.
The most exciting part about this flow is that it is fully configurable. You choose which tasks are required by each of your learning statuses, and you write instructions for each.
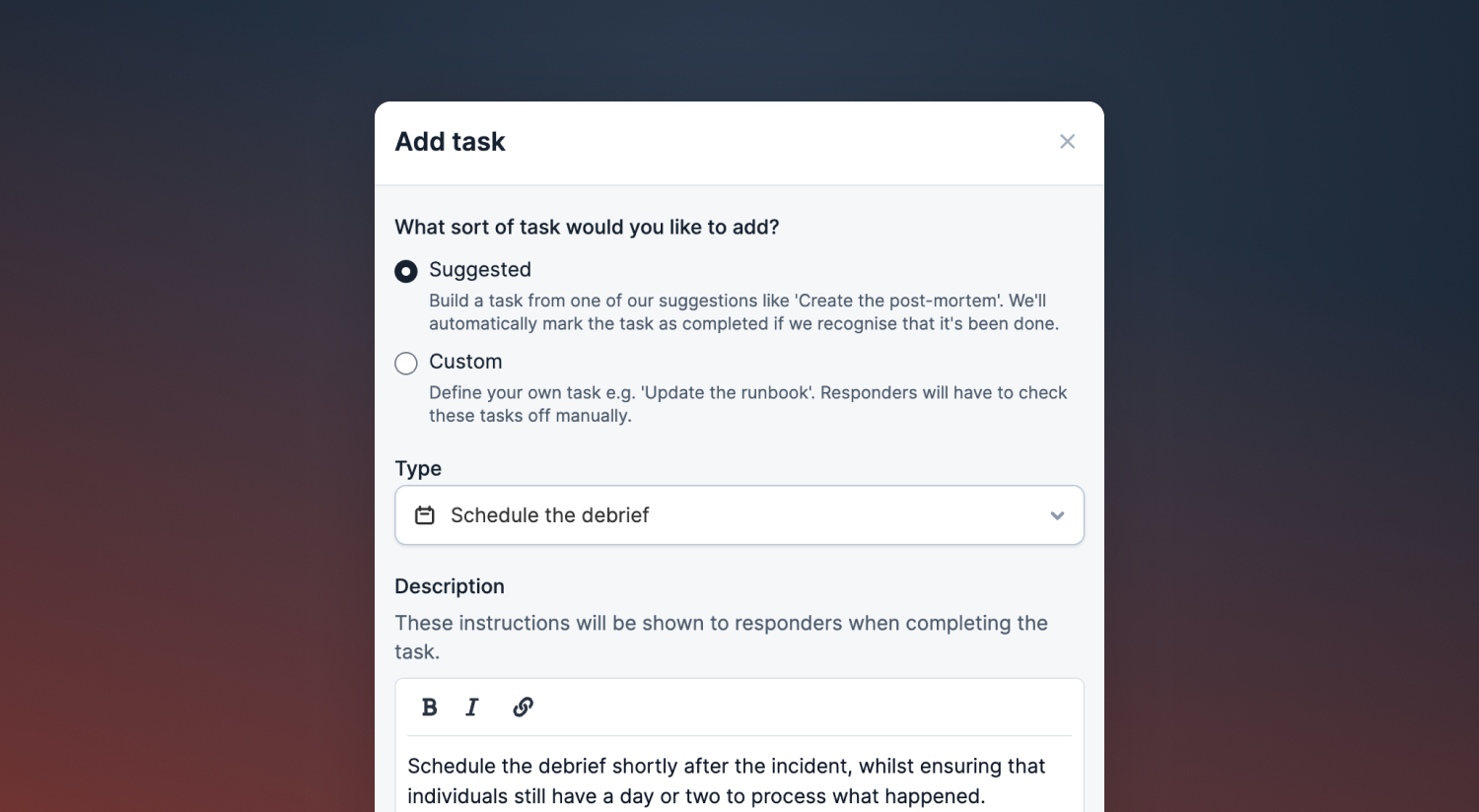
If there are certain types of incidents that should always be entered into the learning flow, such as high-severity incidents, you can set this up in your lifecycle settings. Once enabled, we will automatically push these incidents into the learning flow once they are resolved.
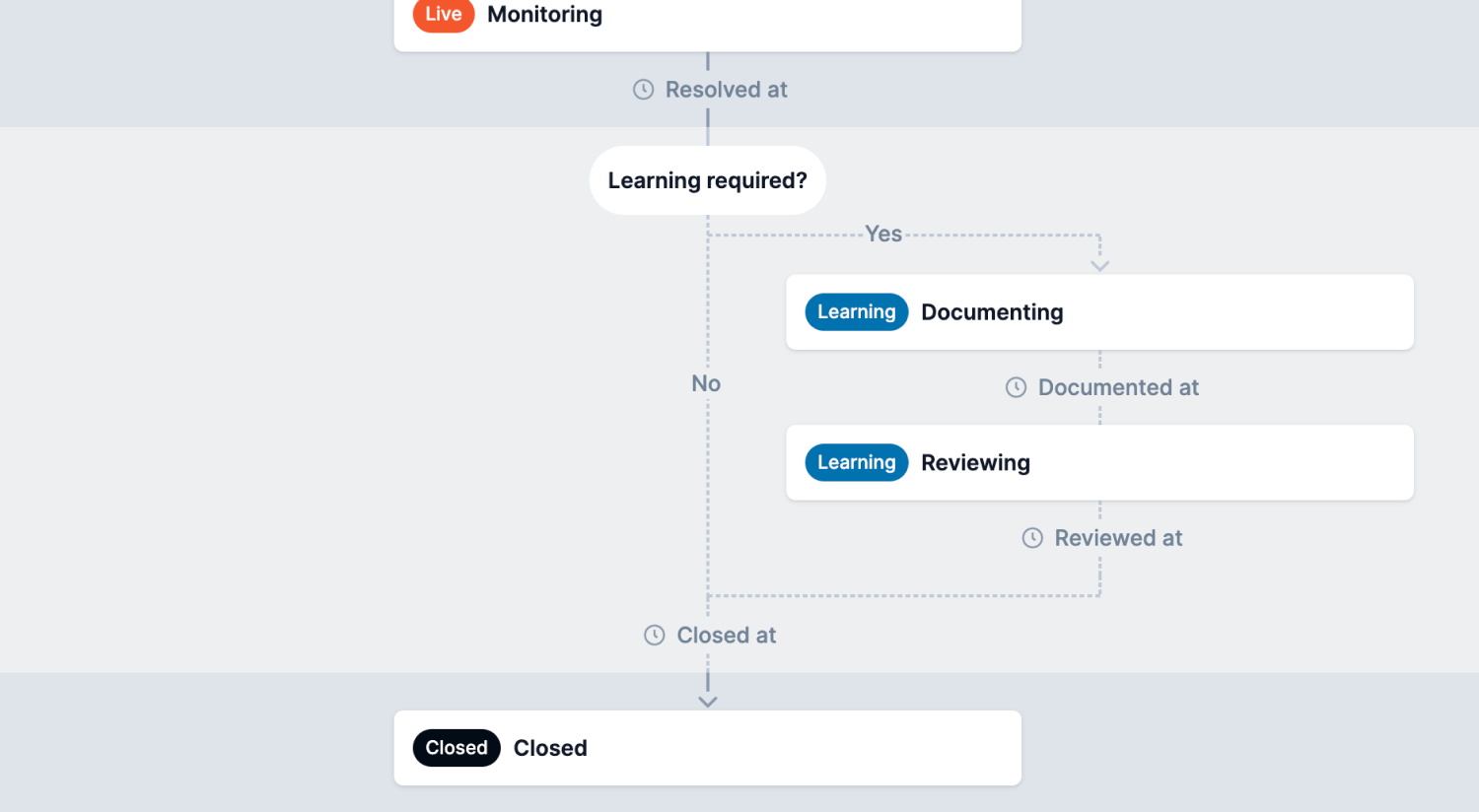
However, you can always choose to opt out of the learning flow. If you do so, we will ask for a reason, which we will attach to the incident and post to the Slack channel to ensure that your team is kept up-to-date.
You can now easily switch between multiple organizations in the dashboard
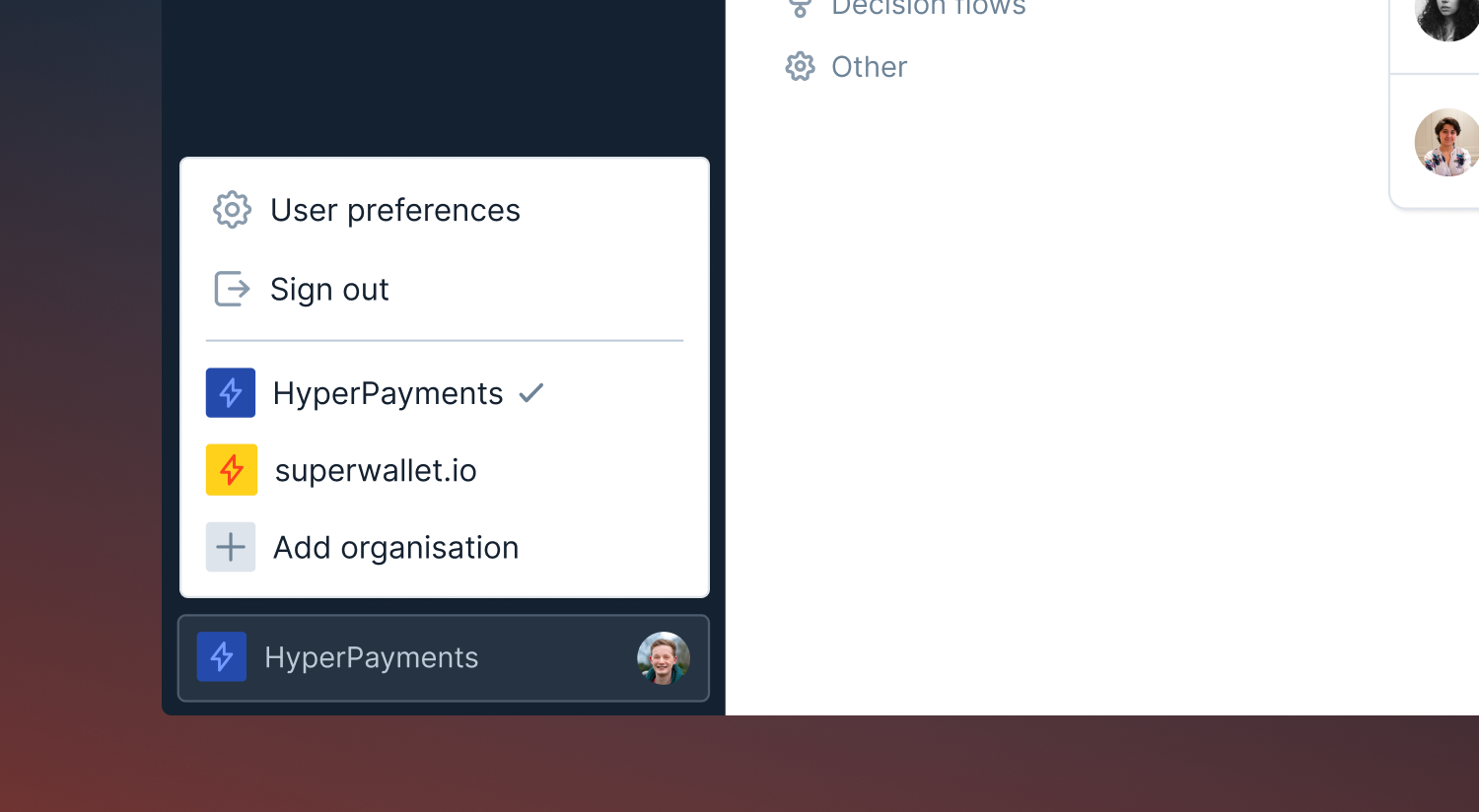
There are a few reasons you might have access to multiple incident.io organizations: you could be an admin using a sandbox account, a member of a conglomerate with several smaller organizations, or a contractor working for more than one organization. If you switch between them regularly, having to log out and then back in each time can quickly get frustrating! This week, we’ve added some new options to the sidebar menu that make switching organization painless.
You’ll find a new + Add organization option in the avatar sidebar menu, below Sign out and Preferences - use this to authenticate with an additional organization without signing out of your current one.
Once you’ve added a second organization, you’ll also find all your current sessions in the same menu - you can simply click them to switch from one to the other. You can also have different dashboards open in different tabs if you would like!
🚀 What else we’ve shipped
New
- If another Slack app attaches images to a message that someone posts, we’ll now add those images to the timeline ✨
- You can now use the description of an OpsGenie alert as a variable when setting the summary of incidents triggered by OpsGenie
Improvements
- The descriptions for actions and follow-ups will now be truncated in Slack messages, to keep the channel tidy
- If you only have one incident type, we won’t ask you to choose one when you’re declaring an incident
- We now include the final update message (if you provide one) when posting the
Incident closedSlack message - We’ve improved the spacing around any
→in the incident timeline - Our status page RSS feeds now make a clearer distinction between incidents and planned maintenance
- Bullet-point formatting in pinned Slack messages will be kept when exporting a post-mortem
Bug fixes
- We’ll now show workspace level labels in the Linear export defaults, raher than showing team specific ones that you might not be able to use for all issues.
- We’ve fixed searching labels in the dropdown when exporting follow-ups to Jira
- We’ve fixed the formatting of SMS verification codes which contain leading zeros
- When declaring an incident from our dashboard, we won’t ask for a severity if you’re declaring a triage incident (as you might not know it yet)
- When deleting followups, it would sometimes stick around on the page, now it vanishes immediately
- Our Custom Field Options API was incorrectly returning the first page of results regardless of any
afterparameter specified
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


