Tricks to fix stubborn prompts


You’ve hit a wall. Despite your best efforts—distilling complex problems into step-by-step instructions, using one-shot prompting with examples of the desired output, and even bumping up to a larger model—the results just aren’t there.
If you’re new to the basics or prompt engineering, Cohere do a great job describing them in their Prompt Engineering guide.
I’ve been in these shoes, and over time, I’ve come across a few techniques that helped me break through the barrier to better results!
1. Only do one thing at a time
If your prompt asks for multiple outputs—like a classification and an explanation—you’re making the model’s job much harder.
// The result of a prompt which checks how likely a code change was
// to cause an incident.
{
"confidence": "high",
"reasoning": "This code change contributed to the deadlock issues because it introduced a new locking mechanism on the table."
}The issue is that classification and natural language generation (NLG) rely on different reasoning:
- Classification is about picking a category with precision.
- NLG is about crafting fluid, context-aware explanations.
When combined, these tasks can interfere with each other:
- A model picking
confidence = highmight stretch to justify it. - A nuanced explanation with uncertainty might stop the model from committing to a strong classification.
From experience: one task is great, two is alright, three or more is a mess. Smaller models especially struggle with this. If your results are inconsistent or the reasoning feels off, this could be why.
The fix? Split the work
To avoid this, split your prompt into two e.g. run the classification first and a second LLM to explain that result. This can actually work out:
- Cheaper e.g. using two mini models rather than one big model is very cost effective!
- Faster, if you’re able to run both of them in parallel.
2. Read the whole prompt
This one sounds obvious but when multiple engineers are iterating on a prompt over time, it’s easy to end up with something that no longer makes sense.
Look for contradiction
Conflicting instructions make LLMs inconsistent. Sometimes, it’s really subtle. Here’s a real-world example from a prompt I wrote to find Slack discussions relevant to an incident. For example, if an alert comes in about database CPU being high, and someone recently posted a message in #engineering about how to handle situations like this, we'd want this prompt to highlight it.
messages := []openai.ChatCompletionMessage{
{
Role: "system",
Content: `
# Task
You will be given a message that might be related to an incident.
Evaluate whether the message contains information that would be helpful for
responders to know about when investigating the incident.
...
`,
},
{
Role: "user",
Content: `This is the incident being investigated: ` + incident,
},
{
Role: "user",
Content: `This is the message that is related: ` + message,
},
}I was banging my head against the wall trying to figure out why the LLM was over-eager to identify messages as related, even though to me, it was obvious that the message wasn’t relevant.
I’d been so focussed on making the instructions in the system prompt clear that I hadn’t realised that the user prompt was influencing the LLM into thinking that the message must definitely be related.
--Before
This is the message that is related:
--After
This is the message that might be related:Unluckily for me, LLM’s give more attention to recent tokens so the later instruction was “winning” most of the time!
Structure matters
LLMs can be pretty good at sifting through unstructured data, and that might work fine for you to begin with. But with more complex examples, or when consistency and accuracy is a concern, you’ll have to get much more professional.
Use this rule of thumb: if the hierarchy of your document isn’t clear enough to read as a human, an LLM will have a similarly hard time parsing it.
This is because LLMs create positional encodings to help them understand hierarchal patterns like headers and document structure. If your structure isn’t clear, you'll impact the LLM’s ability to connect tokens in one section of the doc with another, as the attention mechanism won’t have the positional encoding needed to prioritise the connections.
Here’s an example of a badly structured prompt:
You are helping to investigate an incident.
Here is some context about the incident:
{incident-details}
Here is a list of recent code changes:
{Code-changes}
The goal is to determine which code change is most likely responsible.Where this goes wrong:
- No headers – The model can’t easily tell which section is which.
- The goal is buried – The model doesn’t know what to focus on until it’s already read everything.
- Disconnected information – The incident details and code changes aren’t clearly linked, leading to shallow keyword matching instead of real analysis.
A better approach:
You are helping to investigate an incident.
The goal is to determine which code change is most likely responsible.
## Incident Details
{incident-details}
## Code Changes
For each code change, analyze its impact in relation to the incident.
{code-changes}LLM’s are great reviewers
Reading a prompt top-to-bottom after every change is relatively infeasible for a team who frequently change complex prompts. At least, the amount of concentration required to read intentionally and catch how an LLM might misinterpret your instructions is more than you might expect.
That's why you should consider handing the reviewing to an LLM. We use LLM’s to check the “health” of our prompts regularly, and you’d be surprised at the number of blunders we create when we’re outside the realm of a linter!
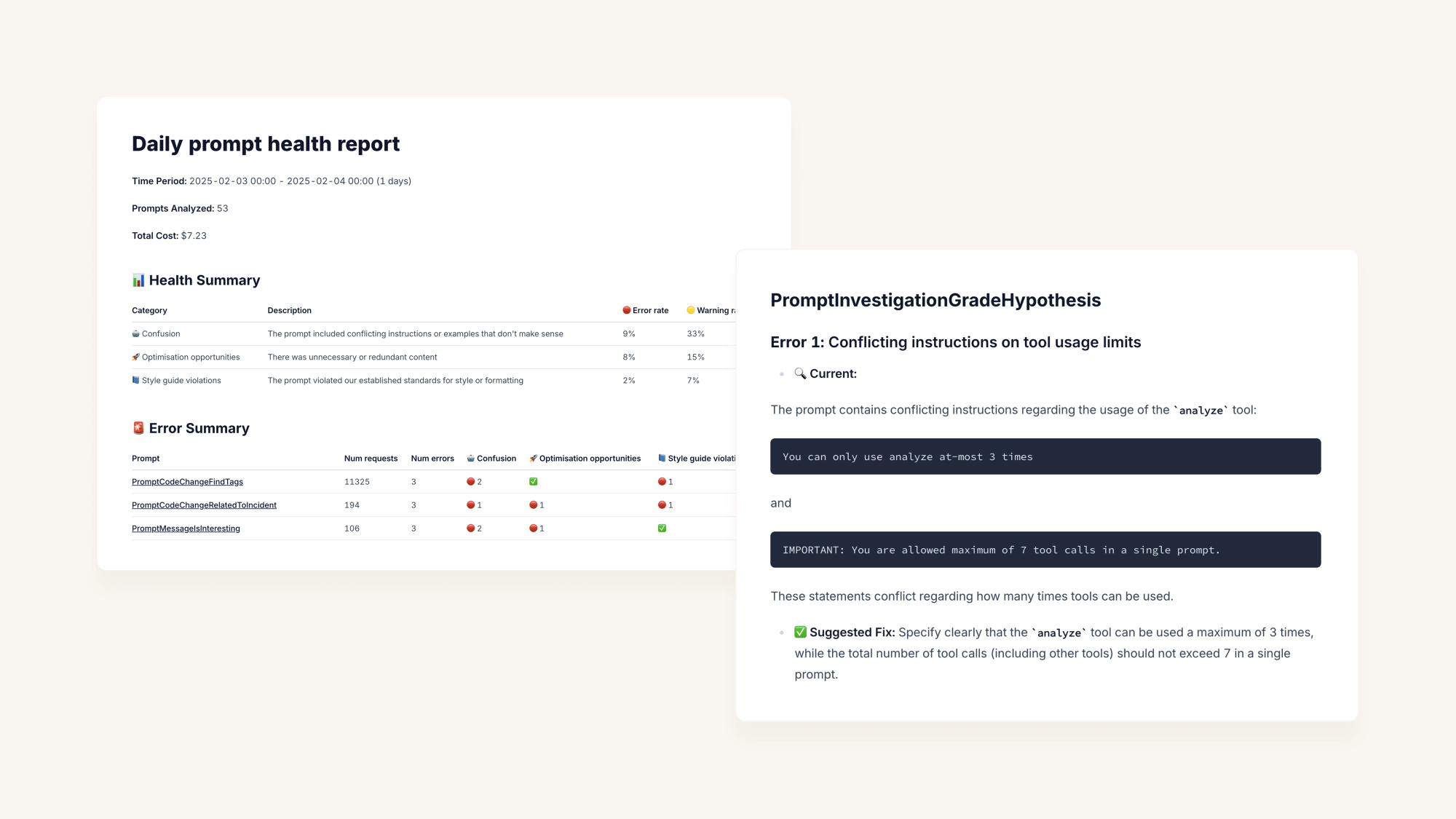
3. Assume zero knowledge
We rely on LLMs having a substantial amount of pretraining that help them solve problems, even without the context that we’ll provide in the prompt. But you can’t assume they know what you know, because your expertise might not be in their training data.
Therefore you should always look at a prompt and ask “Could I solve this with only the info provided?”. A lot of the time you’ll realise that what you might think is obvious based on your own experience, isn’t in fact obvious at all!
For example:
- Instead of saying
Only consider merged code changes, sayOnly consider code changes where status = closed - If knowing the current time is crucial for decision making, include this timestamp as an input
My pro tip: Drop your prompt into an LLM and ask it to flag any hidden assumptions. You’ll catch gaps you didn’t even realize were there.
4. Identify what’s important
If your prompt is quite complex, an LLM will be have to be thinking about a lot of things at once. If some aspects are more important to you than others, you should be saying so!
## Most important rules
* When summarising an incident, only include information mentioned by responders
* Never speculate about the cause of an incidentThis is my oldest trick in the book and it works surprisingly well, but it should be used with caution. Hard-coding the model to focus on particular aspects can cause it to overfit; you can see a real-life example of this when we used vibe coding to engineer a prompt.
5. Try a different LLM model
You might only support one model provider at the moment, but if you’re in a “right prompt, wrong model” scenario then you really ought to know about it!
It’s very low-effort to paste a prompt into the UI for a different model, and if you see better results then it’s good evidence for putting the work in to support it programatically. Also, in my experience, the effort to support another provider is can be less than trying to improve a really stubborn prompt.
Model providers have different strategies for building models, but even models within the same provider can behave very differently.
That's because:
- Training data. If a model has been trained on lots of data related to the problem, you’ll have much better results.
- Attention mechanisms. If a model has a more sophisticated or optimized attention mechanism, it can better "understand" and prioritize different sections of the input.
- Fine-tuning. This means that a model may perform exceptionally well on prompts related to the domain it was fine-tuned on (e.g., legal texts, medical information), but may struggle with general prompts.
Try not to be swayed by benchmarks and instead lean into evals that test your prompts with real data to empirically prove a model is better-or-worse for your use case.
After debugging stubborn prompt evals for hours, someone suggested I try Sonnet instead of 4o. It made that eval suite go from 50% failures to 100% passing, but in other situations the switch made no difference or things got worse!
6. Pre-process your data
When working with structured data, always ask yourself: How can I make this easier for the LLM?
For example:
- Bring related data closer together – LLMs focus on nearby content, so if you need the model to reason about two things, ensure they’re close in the prompt.
- Do the math yourself – LLMs struggle with calculations, so handle any complex math beforehand to lighten the load.
I learned this the hard way—here’s an early version of a prompt that didn’t do any preprocessing:
You are helping to investigate an incident.
The goal is to determine which code change is most likely responsible.
## Incident Details
name: Deadlock on alerts table
created_at: 2025-03-24T15:00:00Z
## Code Changes
For each code change, analyze its impact in relation to the incident.
- name: Add a lock to alerts table
merged_at: 2025-03-24T14:00:00Z
- name: Start archiving old alerts
merged_at: 2025-03-24T11:00:00ZI noticed that the LLM wasn’t prioritising code changes which were merged just before the incident started. And when I asked the LLM for a reasoning to help debug, I noticed that it was calculating the duration incorrectly! Switching merged_at to time_since_merged: 1 hour instantly improved performance.
Putting it all together
When a prompt isn’t working:
- Start by reading the prompt top to bottom, looking for messiness or points of confusion.
- Reframe your instructions so that they assume zero knowledge.
- Check if you could help the LLM out by pre-processing the input data.
- If you’re still having problems, sanity check if you’d have any success with another provider, or if adding a short section about importance would help.
- If all of that fails, you’ll need to make some big changes i.e. split the prompt into multiple.
The key takeaway? Be methodical and be patient!
More articles

Weaving AI into the fabric of incident.io
How incident.io became an AI-native company — building reliable AI for reliability itself, and transforming how teams manage and resolve incidents.
 Pete Hamilton
Pete Hamilton
The timeline to fully automated incident response
AI is rapidly transforming incident response, automating manual tasks, and helping engineers tackle incidents faster and more effectively. We're building the future of incident management, starting with tools like Scribe for real-time summaries and Investigations to pinpoint root causes instantly. Here's a deep dive into our vision.
 Ed Dean
Ed Dean
Avoiding the ironies of automation
Incidents happen when the normal playbook fails—so why would we let AI run them solo? Inspired by Bainbridge’s Ironies of automation, this post unpacks how AI can go wrong in high-stakes situations, and shares the principles guiding our approach to building tools that make humans sharper, not sidelined.
 Chris Evans
Chris Evans
Join our team – we’re hiring!
Join the ambitious team helping companies move fast when they break things.
See open roles