New: AI-native post-mortems are here! Get a data-rich draft in minutes.
The startup guide to sensible incident management
February 3, 2022 — 9 min read

If you’re working at an early stage startup and looking to get some good incident management foundations in place without investing excessive time and effort, this guide is quite literally for you.
There’s an enormous amount of content available for organizations looking to import ‘gold standard’ incident management best practices – things like the PagerDuty Response site, the Atlassian incident management best practices, and the Google SRE book. All of these are fantastic resources for larger companies, but as a newly founded startup, you’re left to figure out which bits are important and which bits you can defer until later on.
Early-days incident management is as much about what you shouldn't do as what you should, and – strictly between us – this guide is basically how we’re doing incidents at incident.io right now. Think of it as a set of sensible defaults that can be easily adopted to get you off to a great start.
Whilst this explicitly isn’t a sales pitch, it also sort-of is 😉 We’ve got a great product at incident.io that can help you get off to a great start, and that'll continue to mature with your needs as you grow. It’s not all sales though – I’ve pushed everything incident.io specific right to the end to avoid muddying the water.
Short on time? We've got you covered 👇
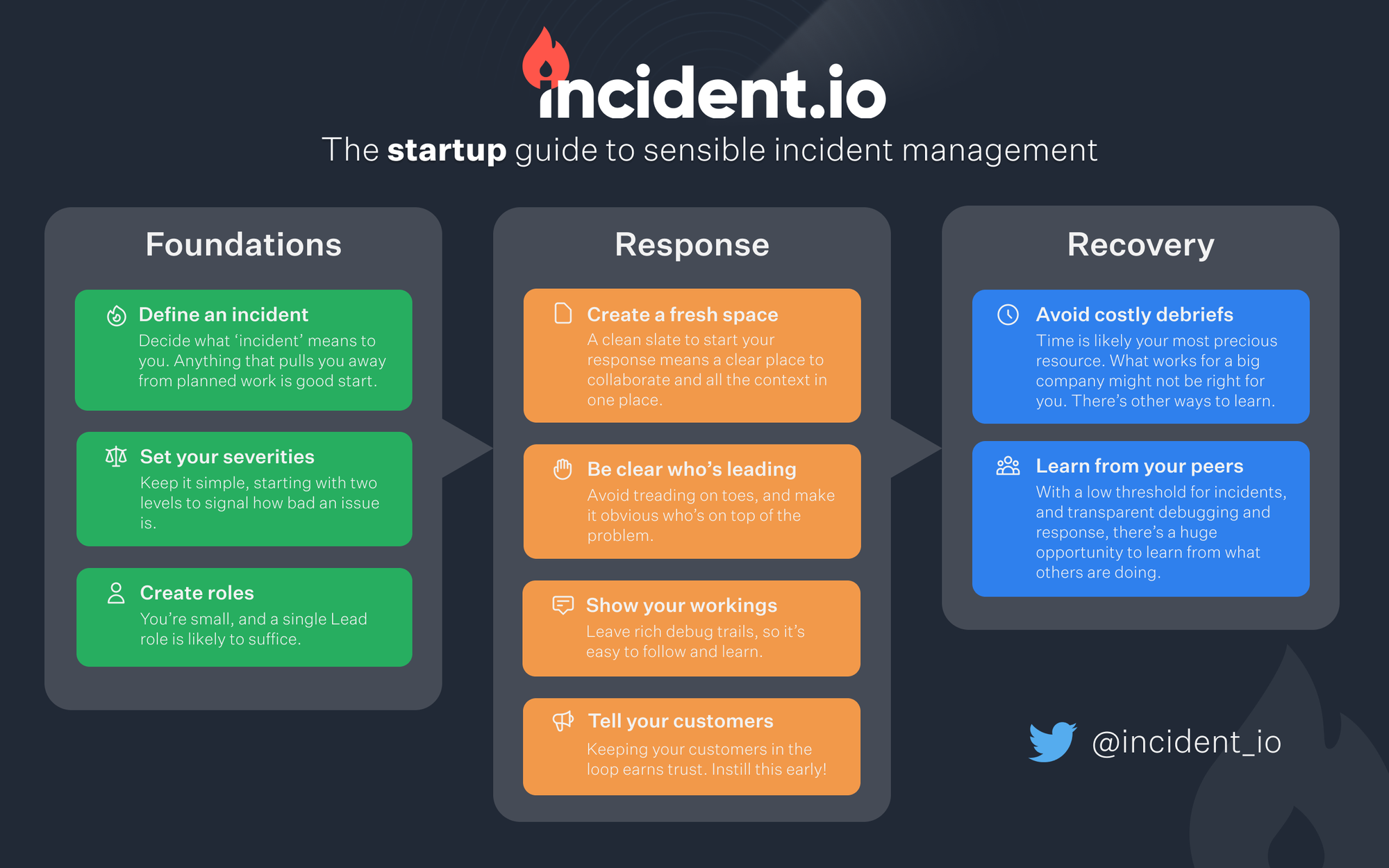
Laying the foundations
In this section we cover the basics of what you should focus on whilst setting up your incident management ‘rails’.
Define your threshold for an incident
Everyone has a different perception of where normal work ends and an incident begins. Being a young startup, there’s unlikely to be someone banging the drum for ITIL definitions, so the good news is you can literally pick your stance.
At incident.io we treat any interruption to normal work as an incident. That might mean a single Sentry error that needs investigation, some behaviour we can’t explain, or a report from a customer. Our motivations for doing so are:
- to make ownership clear: “I can see Lawrence is looking at that bug, I’ll leave him to it”
- to aid knowledge sharing: “I see Sophie looked into an issue last night which was related to the thing I was working on. I’ll scan through what happened”
- to ruthlessly prioritise: we use incidents to systematically triage issues quickly to determine whether a fix needs to be picked up immediately or deferred until later
We’re not logging these incidents with the intention of running lengthy post-mortems or extracting rich insights. Those things are valuable in a bigger org, but as a small organization it’s all about transparency and speed of recovery.
Set some simple severities
Many folks spend time sweating over their severities. Our advice here is simple: have a high severity and a lower one, and get on with building your company.
At incident.io we report the vast majority of incidents as Minor, and if there’s significant customer impact, mark it as Major. We do this to separate incidents that are being declared for visibility from those causing active pain or that would benefit from folks getting involved in.
To add some nuance to this: when you’re small, severities matter very little. Later in life you might use them as trigger points for escalations, for reporting up to execs, or to trigger policy like requiring a post-mortem to be carried out. None of this is necessary, and you’ll likely spend more time than you’ll save by trying to do anything more sophisticated.
Your goal here is to get the thing fixed, and make it easy to coarsely signal how bad the problem is. Anything else is excessive for a startup and can be safely ignored.
Don’t worry about roles
We’re often asked about which roles are important to define. Our response? Just one. Make it clear who’s responsible for seeing the incident through to completion, call them the lead, and move on.
The role of the lead in small scale incidents is primarily to own the issue through to resolution. That means debugging, communicating with customers, and logging any follow-up actions that might arise. Of course, all of these can be delegated as required, but starting out with anything more complicated is overkill.
In a startup, top-down command and control just isn’t super necessary. You’re not likely to have 30 people on a call who need to be directed, so the role exists primarily to know who to go to for information or where to offer support.
Decide where incidents will be logged
With everything else in place you need to decide where you’ll keep a record of your incidents. Having this record is helpful for internally seeing what’s going on, but it’s also likely to be important as you grow.
If you’re building a SaaS product, the chances are you’ll be looking at security certifications some day – something like SOC 2 or IS27001. Both of these will require you to keep a record of incidents. Likewise, if you’re raising future funding rounds, you may also be asked for this information as part of due diligence checks. It pays to be prepared!
Whilst using incident.io solves this problem (micro sales pitch over), a Notion DB or Google Sheet with a link to a Slack channel work just fine too.
Running an incident
With your rails in place, what should you do when that alert fires, or a customer says they can’t use your product? Here’s the low-down...
Create a fresh space to coordinate
First and foremost, create a space to coordinate your response from. Whether it’s a new Slack channel or a fresh Google Doc, having a clean slate to start from is important. By starting afresh you’re capturing all of the context in one place, which’ll make it easier to re-trace your steps, easier to get other folks up-to-speed, and easier to report once the dust has settled.
Be clear whose incident it is
With your new incident channel or doc in hand, the first thing on your list is to let everyone know you’re on the case. This’ll avoid situations where two people ended treading on each others toes, and provide a point of contact for anyone looking to help or ask questions.
Optimise for knowledge sharing
Tacit knowledge – which is stuff people just know – runs rife when you’re building at speed, and incidents can help keep your team on the same page.
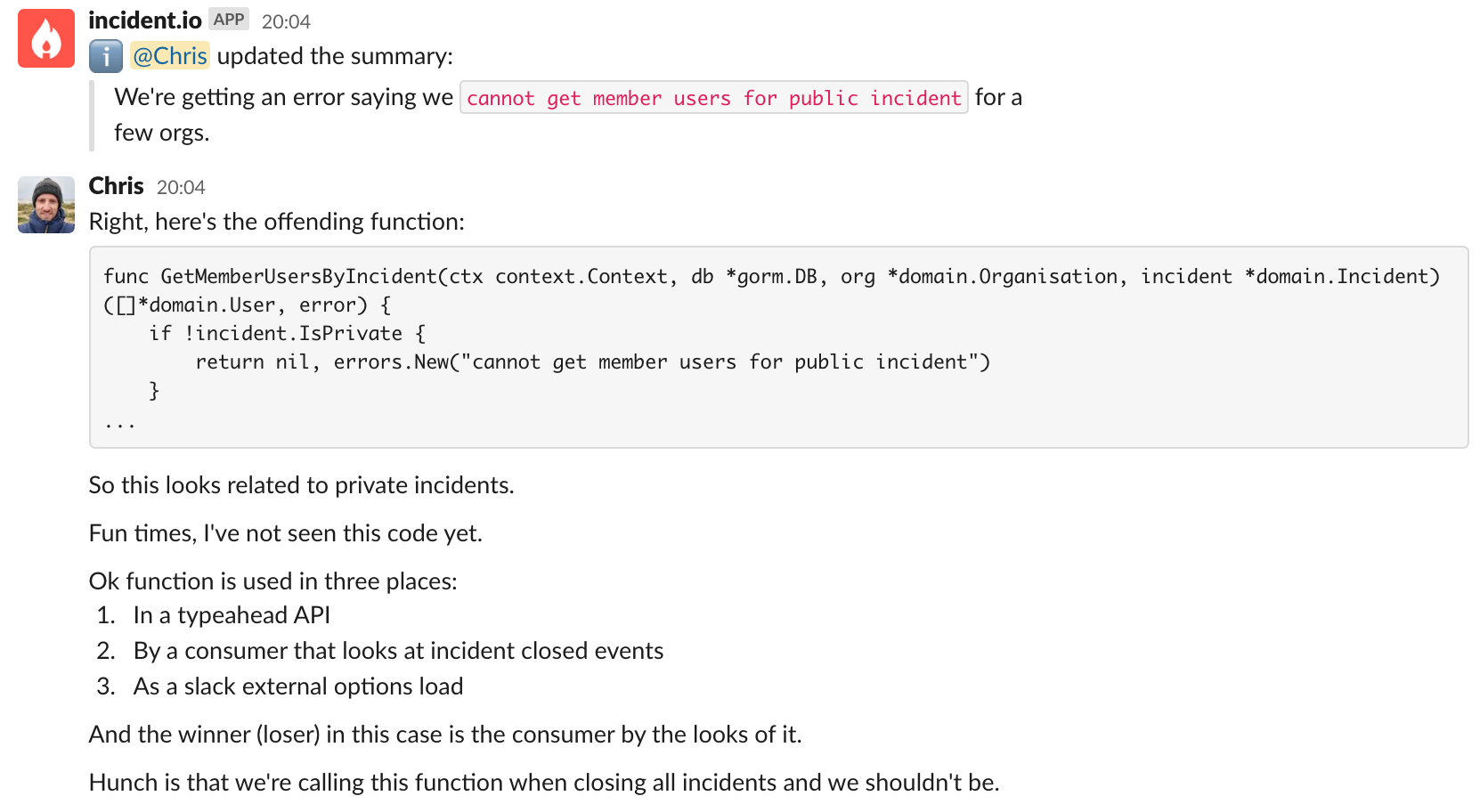
Debugging trails are a fantastic source of information on both the particular problem being investigated, and the processes and tools folks are using to debug things. I’ve learnt a heap of tricks with our observability setup by seeing what others are posting.
Practically speaking, we advise posting logs, error messages, screenshots of graphs and traces, and exactly what you’re thinking into the channel. If someone joins to help out, they can see exactly where you’ve been and mobilise quickly.
Keep your customers in the loop
In the early days, you’re unlikely to have zillions of customers (if you do, kudos!). As we’ve posted about before, good incidents are founded on good communication, and that extends to your customers too.
We’d strongly advocate for over sharing, whether that’s by putting your public status page up, posting a tweet, or messaging customers directly. You’re small, and your customers are early adopters that are likely to be forgiving!
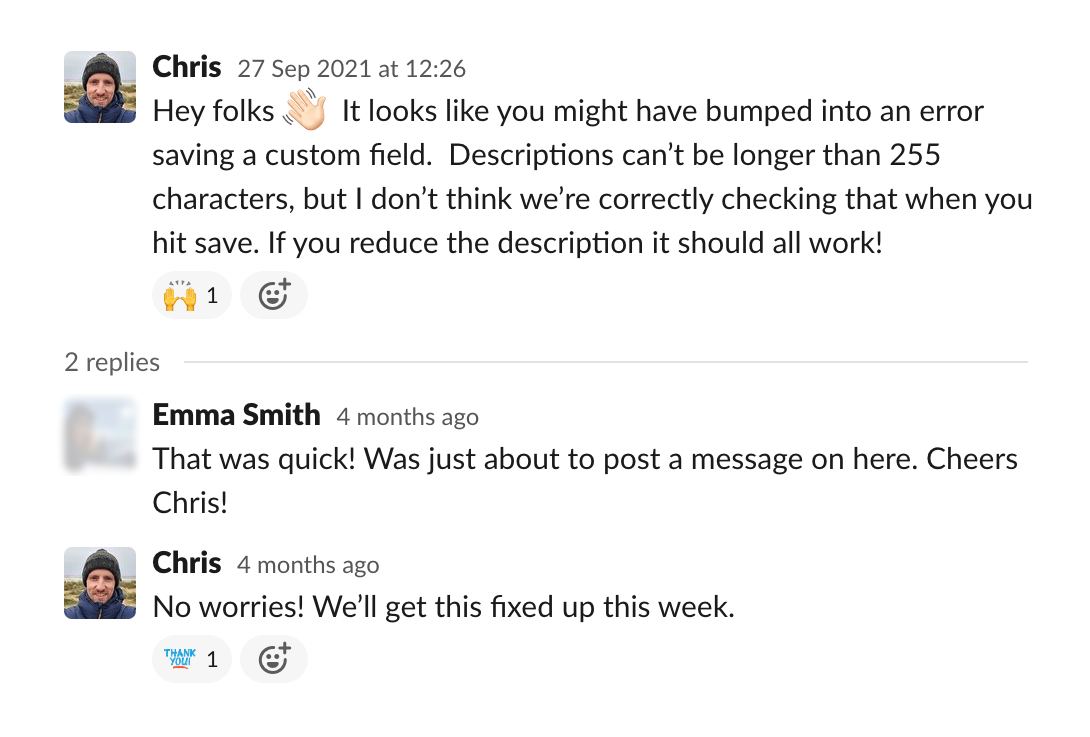
In our experience, a swiftly fixed bug that’s communicated with a customer works wonders for building trust.
After an incident
Avoid wasted time on lengthy post-mortems
This point might be a little contentious, but I wanted to add it anyway. In all of our time at incident.io, we haven’t run a single formal incident post-mortem, and I think that’s ok.
I’ve worked in bigger organizations where thorough debriefs have been both necessary and hugely valuable. As complexity increases – whether organizationally or technically – it’s incredibly hard to understand what went on without taking the time to talk to folks who were involved, and dig into the full story.
In a sub 25 person startup where time is your most precious resource, I think it’s hard to justify the ROI. This isn’t to say you shouldn’t do them, but blindly importing this practice from bigger orgs shouldn’t be your default.
Review incidents you weren’t involved in
If you’re looking for a time efficient way to level up your expertise and understand on something, and you’ve done everything else in this guide, you’ll find a proverbial gold-mine of information in your individual incidents.
Take a look, reinforce the behaviour you want to see more of by leaving feedback, and iterate!
Getting all of this in 5 mins
As promised, the sales pitch. incident.io can provide this setup out of the box, and if your Slack workspace has fewer than 25 users it’ll only cost you £149/month.
We’re a great default for small organizations, and you can go from zero to fully-configured in 5 minutes. If it takes you longer, message us @incident_io on Twitter and we’ll give you your first month free.

Chris Evans
Co-Founder & CPO
I'm one of the co-founders, and the Chief Product Officer here at incident.io.
See related articles

Who's on call? How Claude helped us calculate this 2,500x faster
A look at how on-call schedules work, and how we made rendering them 2,500× faster — through profiling, smarter algorithms, and some Claude.
 Rory Bain
Rory BainApril 28, 2026

How it feels to run an incident with AI SRE
For the last 18 months, we've been building AI SRE, and one of the things we've learned is that UX matters more than you think. This week, I used AI SRE to run a real incident, and I walk you through it end-to-end.
 Chris Evans
Chris EvansApril 23, 2026

What does using AI for post-mortems actually mean?
Everyone is using AI to help with post-mortems now. We've built AI into our own post-mortem experience, pulling your Slack thread, timeline, PRs, and custom fields together and giving your team a meaningful starting point in seconds. But "AI for post-mortems" can mean very different things.
 incident.io
incident.ioApril 23, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization



