Choosing the right Postgres indexes
October 25, 2024 — 10 min read

Indexes can make a world of difference to performance in Postgres, but it’s not always obvious when you’ve written a query that could do with an index. Here we’ll cover:
- What indexes are
- Some use cases for when they’re helpful
- Rules of thumb for figuring out which sort of index to add
- How to identify when you’re missing an index
What is an index?
By default, Postgres reads data by scanning every row and filtering out results it doesn’t need. This might be fine when your dataset is small, but as your tables grow this becomes inefficient and slows things down.
An index in Postgres is like the index at the back of the book. So if you’re looking for a particular topic in a book, you have two options:
- Read the book cover to cover. In Postgres, this is called a sequential scan, where Postgres goes through every single row until it finds what it’s looking for.
- Jump to the relevant section in the book, using the index. In Postgres, this is called an index scan, where Postgres finds the relevant rows faster by skipping large parts of the table.
To demonstrate this, let’s create a users table that has 500k rows. You can visualize how Postgres will query this table by using two methods:
EXPLAINshows the query plan (i.e. a tree structure of nodes which shows how a query will be executed) along with the estimated cost.EXPLAIN ANALYZEdoes the same, but runs the query too so the cost is more accurate.
Here’s an example of using EXPLAIN ANALYZE to filter the users table.
-- Input
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'someone@example.com';
-- Output
Seq Scan on users (cost=0.00..21500.00 rows=1 width=64) (actual time=0.025..215.000 rows=1 loops=1)
Filter: (email = 'someone@example.com')
Rows Removed by Filter: 499999
Planning Time: 0.065 ms
Execution Time: 215.150 msUsing the sequential scan, Postgres would take 215ms to execute this query. Let’s see what happens if we add an index first.
-- Input
CREATE INDEX idx_users_email ON users(email);
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'someone@example.com';
-- Output
Index Scan using idx_users_email on users (cost=0.42..8.44 rows=1 width=64) (actual time=0.010..0.020 rows=1 loops=1)
Index Cond: (email = 'someone@example.com')
Planning Time: 0.062 ms
Execution Time: 0.050 msThe execution time dropped to 0.05ms using the index scan - nice!
Note that if this query was to fetch a user by ID, we might not of had this problem because Postgres automatically creates an index for primary keys.
What are the disadvantages?
So if indexes are great, why don’t we use them all the time? Well unfortunately, indexes don’t come for free. They require extra disk space and slightly slower performance on writes (inserts, updates, and deletes), because the index needs to be kept up to date. So while indexes are great for speeding up reads, you only want to add them for queries where they’re necessary.
So when do I need one?
Because of the overhead, we only need to add indexes for frequently ran queries. But how can you tell that a query would even be suitable for an index?
(1) When the query discards a high proportion of the rows it reads. This can happen when you filter rows with a WHERE operation, or when you have a JOIN on a small number of rows.
- For example, at incident.io we regularly fetch resources for a particular organization, and the relevant resources are usually a tiny subset of the whole table. Therefore when we add a new table, we usually create an index on the
organization_idandarchived_atcolumns:
CREATE INDEX idx_users_organisation_id ON users (organisation_id) WHERE archived_at IS NULL;(2) When the query needs rows to be returned in a particular order. This can happen when you use an ORDER BY clause. If you have an index that matches this, Postgres can retrieve the rows directly from the index, avoiding the need for a separate sorting operation.
- For example, let’s say we need to frequently return users for an organization in the order they registered. We could add an index for this:
CREATE INDEX idx_users_organization_id_created_at ON users (organisation_id, created_at);(3) When you want to enforce uniqueness. You can achieve this by creating a unique index.
- For example, we have a constraint which means that every user should have a unique email address for an organization. We could add this index:
CREATE UNIQUE INDEX idx_users_unique_email ON users(organization_id, email);What type of index should I add?
Most of the time, you’ll want a b-tree index—it’s Postgres’ default and works well for most use cases. You can add one like this:
CREATE INDEX idx_users_email ON users(email);Order matters
Note that if you include multiple fields in your index, you should place the most frequently queried columns first so that you can re-use the index. For example, Postgres would be able to use the below index to filter incidents for a particular organization_id, even if you didn’t filter on reported_at. But you wouldn’t be able to re-use this index if you only filtered on reported_at. This is not totally obvious!
CREATE INDEX idx_users_organization_id_reported_at ON users (organization_id, reported_at);Don’t over-index
You should always prefer indexes that cover the most use cases, even if that means your query isn’t solely relying on an index scan. This is easier to understand with an example - let’s say that we regularly fetch all users for an organization which are in the viewer state. We could create an index on organization_id and state but this wouldn’t be reusable for other places in the app which fetch all users for an organization, regardless of state.
CREATE INDEX idx_users_organization_id_state ON users (organization_id, state);You might be better off just creating an index an organization_id , which your query would use before sequentially scanning on just a few rows. This is fine, and the index is much more reusable!
CREATE INDEX idx_users_organization_id ON users (organization_id);EXPLAIN / ANALYZE are your friends here for figuring out what index would be appropriate for the shape of your data. Note that if using your index isn’t more efficient, Postgres is smart enough to ignore it when planning a query.
Exclude rows you’ll never need
It’s also worth thinking about whether your index should exclude some rows (in Postgres this is called a partial index). At incident.io, we only ever want to return rows to our production app that haven’t been soft deleted in our database. Therefore most of our indexes are constrained to rows where archived_at is null.
CREATE INDEX idx_users_organization_id ON users (organization_id) WHERE archived_at IS NULL;This means that the index is smaller, so less disk space is used to store it. It is also faster to scan because there’s less data to sift through.
It’s worth noting although b-tree indexes solve 90%+ of problems, there are other types of indexes to consider if your use case is more specific:
- GIN and GiST indexes are great for full-text search and geometric data.
- Hash indexes are optimized for equality comparisons, but b-trees often do the job just as well.
- BRIN and SP-GiST indexes also exist. You can compare all index types in the documentation here.
Identifying when you are missing an index
It’s all good and well to know that we need to add indexes, but in practice it’s very easy to add tables without any indexes, which only become a problem when the number of rows have built up. So it’s likely you’ll end up proactively add indexes to tables in the future, when you notice requests slowing down.
To help identify index-related problems quickly, we added section to our Postgres performance dashboard in Grafana which highlights database tables that are commonly involved in sequential scans. This is especially handy when we get alerts related to high CPU utilization, because a spike here indicates that we’ve started running code which isn’t making use of an index.
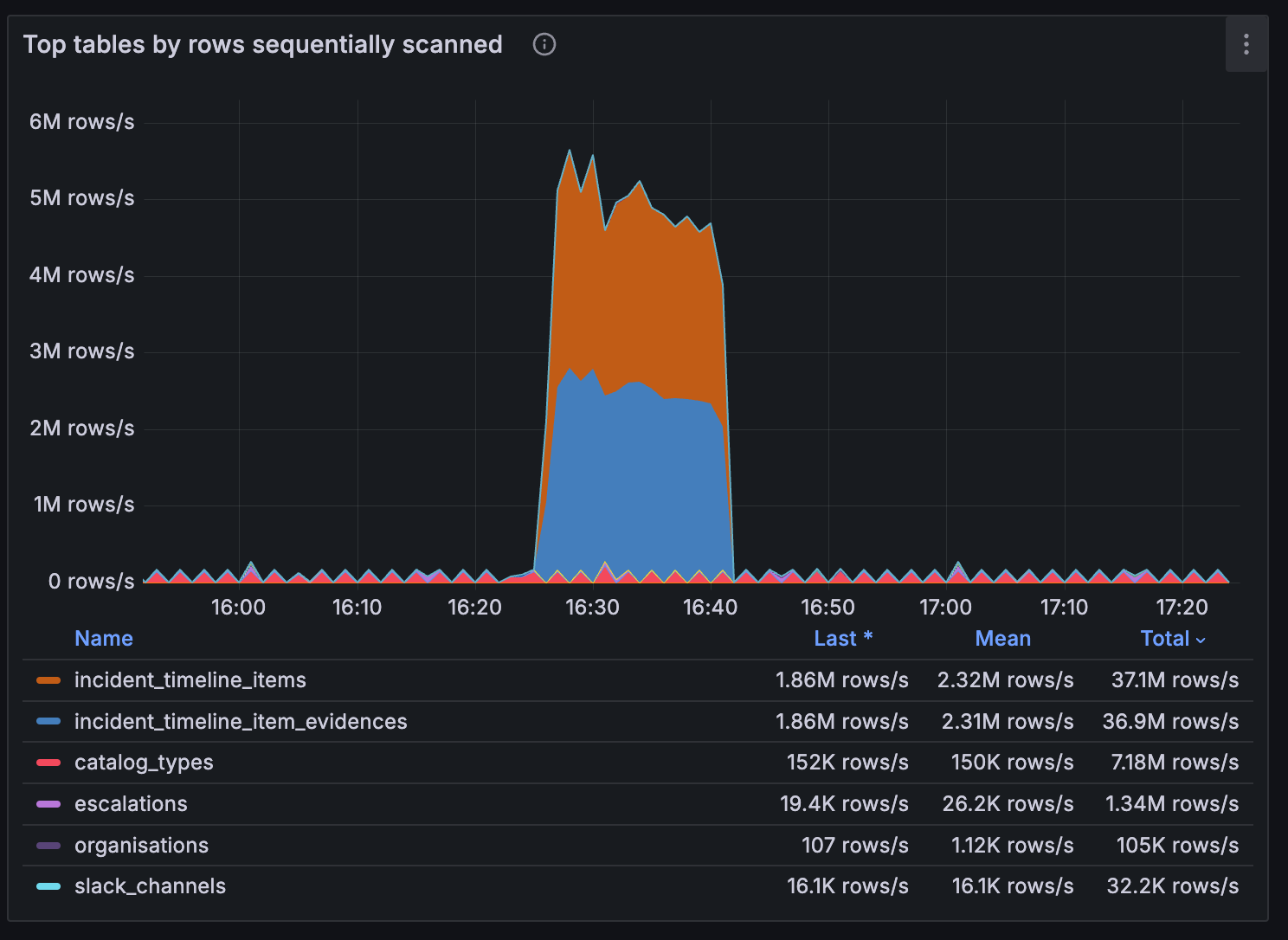
The code for this chart is as follows, so to recreate this yourself you’ll just need to add a metric like pg_stat_user_tables_seq_tup_read which tracks the number of rows fetched by sequential scans on a particular table.
topk(10, max by (relname) (rate(pg_stat_user_tables_seq_tup_read{project="$project"}[$__rate_interval])))If you don’t have Grafana, you could consider using Query Insights in Google Cloud SQL or pgAdmin. Once you’ve used one of these tools to identify a table which might be missing an index, you can follow these steps to resolve the problem:
- Inspect the most frequent queries that are being ran against this table
- Run
EXPLAIN ANALYZEto confirm your suspicions about how a frequently ran query is being executed - Check the existing indexes to see what might be missing
- Go ahead and add a new index!
Summary
Adding the right indexes can significantly improve the performance of your queries, but it’s important to be mindful of when they’re truly needed. Here are the main takeaways to keep in mind:
- Debug your queries:
EXPLAINandEXPLAIN ANALYZEhelp you visualize how queries are executed, revealing whether a sequential scan or index scan is being utilized. - Identify when to index: Adding an index is beneficial for frequently ran queries, where:
- The query discards a high proportion of rows
- Or the query requires results in a specific order
- Or you want to enforce uniqueness
- Choose the right type of index: A b-tree index is the go-to for most use cases. Ordering columns correctly in composite indexes can enhance reusability, and excluding unnecessary rows can make your indexes more efficient.
- Leverage available tools: Utilizing tools like Query Insights in Google Cloud SQL or performance dashboards in Grafana can identify tables with high sequential scans, and therefore might require indexes.
By carefully considering these factors, you can create a robust indexing strategy that enhances your database’s performance while balancing the overhead of maintaining those indexes. Happy indexing!

Milly Leadley
Product Engineer
See related articles

We rebuilt our post-mortems from the ground up
Today we're launching our new post-mortems experience, and I want to walk you through what we've done and why.
 Pete Hamilton
Pete HamiltonMarch 17, 2026

Bloom filters: the niche trick behind a 16× faster API
This post is a deep dive into how we improved the P95 latency of an API endpoint from 5s to 0.3s using a niche little computer science trick called a bloom filter.
 Mike Fisher
Mike FisherNovember 14, 2025

My first three months at incident.io
Hear from Edd - one of our recent joiners in the On-Call team - how have they found their first three months and what's it been like working here.
 Edd Sowden
Edd SowdenSeptember 1, 2025
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


