How incident.io gave WorkOS the confidence to declare more incidents
Since adopting incident.io, WorkOS, an API platform that enables organizations to easily implement enterprise features like Single Sign-On (SSO), has eliminated manual processes around incident response, resulting in more consistent and reliable incident declarations.
As the VP of Engineering at WorkOS, Alon Levi has always kept incident management top of mind.
Starting his career as a backend engineer at Google, Alon focused on projects around infrastructure. “I got to do a fair amount of low-level code for distributed systems, performance, and developer platforms. I learned a ton.”
After six years at Google, Alon left for Dropbox, where he spent some time before joining Quip, a productivity tool.
“It was a small company at that time. We had to build a lot of the stuff that WorkOS does today, which ties into what I'm doing now. So the themes of developer productivity, platforms, and enterprise software came together.”
For Alon, throughout all of these roles, there’s been one constant: the importance of incident management to help track, learn from, and follow up on any issues.
“You have to be really on top of things when you're building a developer platform. I learned that in my earliest days at Google. We had to have good processes for tracking, following up, and presenting maturely as an organization that took these things seriously.”
Unblocking incident response
While WorkOS had a Slack-driven incident response process in place before adopting incident.io, the team acknowledged that they needed a better, less manual way to run incidents. They had runbook-style documents that outlined response processes, but automation was nonexistent–something that they were hoping to implement.
What the team was doing was fairly ad-hoc. They would divide up responsibility for investigating, communicating about, and resolving incidents. Then, they made sure that they followed up and kept track of any post-incident actions. But this was all manual.
But because of this, onboarding was a big pain point. Incident response was really hands-on, so getting new team members up to speed on current processes would often be a big challenge.
"The team was pretty small when I joined. There were only about ten engineers. So the overhead of documenting wasn't too hard. But as we started to grow, it certainly became more of an issue. We didn't want to train people up on how to coordinate an incident."
Lowering the bar for the incident process
Because response processes were manual, they required a lot of mental overhead.
So, for Alon and his team at WorkOS, lowering the burden of incident response was a huge priority. “We liked our workflow. But we wanted it to be more flexible. We wanted to lower the burden for the incident responder to communicate with folks,” says Alon.
“So after a while, we thought to ourselves, ‘We're doing this all the time. Is there a better way?’”
Build vs. buy?
While weighing their options, WorkOS considered the classic scenario of buying a dedicated tool or building their own in-house solution. For them, it was a straightforward decision.
For us, building is more work. We'd love to use that energy elsewhere in terms of improving the content of the process rather than the mechanics of it. We’re also a company that really believes in hiring experts to build things that we don't need to. So we look to other folks who specialize in areas we want to solve a problem in.
How incident.io has helped WorkOS transform its incident response
Today, WorkOS has not only cut back on manual incident processes but also has a more streamlined way to learn from them as well. The result is a team of incident responders that not only manage incidents better but actively encourage them.
[incident.io] allowed us to broaden the definition of what an incident is.
Now, with incident.io, the overhead during incidents is gone, leaving response teams feeling more confident throughout the process.
Automated workflows to remove mental hurdles
One of the biggest benefits of adopting incident.io has been the introduction of automation. As one of WorkOS’s top priorities, it was important to get this right. Thankfully, not only has automation proven to be viable, it’s been a game-changer.
“Being able to automatically create a hub for incidents that everything is connected to is key. In the past, we had to do some digging if we wanted to look back and investigate what actually happened, what lessons we learned, or if we even resolved the incident.”
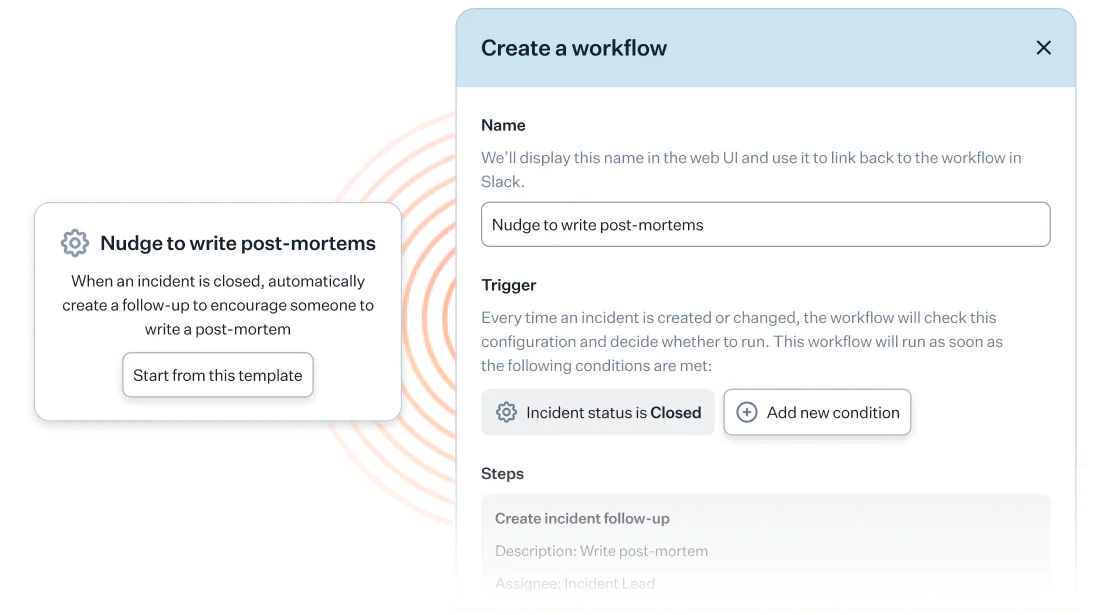
incident.io’s Workflows feature, in particular, has driven a culture shift of declaring more incidents.
Workflows are really impactful. Because we're declaring more incidents, being able to have rules around what happens during them is really useful. We've leaned into creating automation around what types of incidents need to have more of a focus on them.
Follow-ups to facilitate a culture of improvement
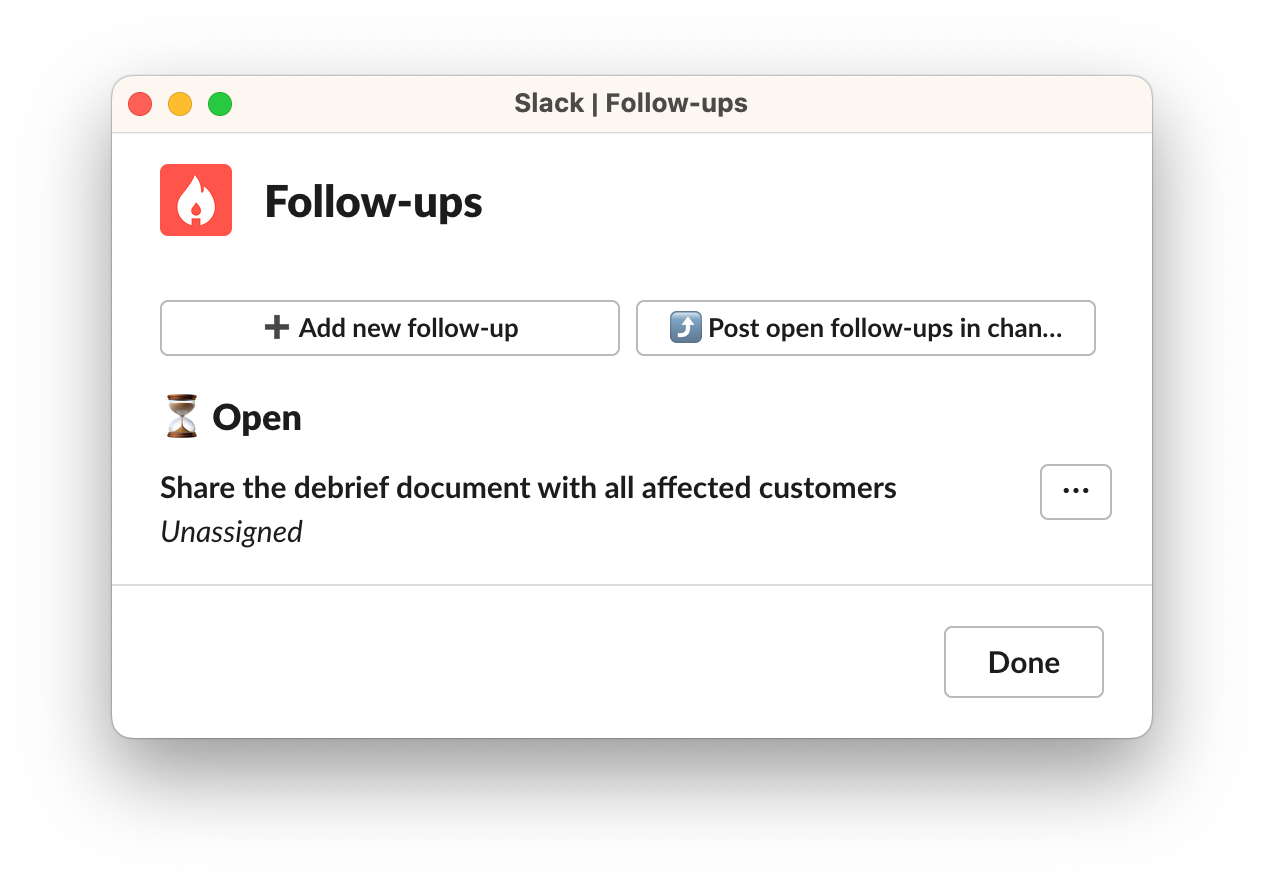
At WorkOS, incidents don’t end once they’re closed out. Often, this just marks the start of the work. And thanks to incident.io’s follow-up’s feature, Alon and the WorkOS team have a better way to track and manage any post-incident work that needs to happen.
Follow-ups are a key part of incident.io’s post-incident functionality. With them, responders can record specific actions that should happen after an incident is resolved, for example, adding new tests or investigating a system that contributed to the incident. And with the ability to automatically export and synchronize follow-ups with their issue tracker, Linear, staying on top of progress has never been easier.
“This feature has been really helpful. The transition from them into the postmortem process has helped us be consistent in tracking post-incident workloads.”
Incidents across engineers, customer support, and beyond
With incident.io, WorkOS has been able to lower the bar for incidents, which allows them to manage issues in more sensible ways.
“The biggest shift for the team has been the realization we can include anything reactive as an incident.” says Alon.
Now, incidents can be customer questions, anything that requires an investigation, or even a migration we have to track.
Not only was WorkOS able to be more inclusive about what an incident is, but they were able to get non-technical teams bought in as well.
“The consistency and common touch points across all incidents make it really easy for someone to know what an incident Slack channel is. It allows different people with varying degrees of technical comfort to dig in deeper, which I think is really valuable at our stage.”
More incidents, no problem
And finally, while the appearance of more incidents can be a sign of trouble, for WorkOS, this increase is by design. Because of the automation that incident.io enables, its intuitive UI, and the ability for non-technical teams to get up to speed in no time, WorkOS has been able to scale up its number of incidents with confidence.
“It allows for incidents to get funneled into a process that's well defined. More focused communication and a clearer beginning and end to incidents are a huge benefit. Tracking when something started. Keeping tabs on the status of it. Fewer of these things are left open. Now we have more consistent, reliable tracking."