Buffer is a social media management platform that has been helping creators and small businesses grow for over a decade. As pioneers of social scheduling, they serve millions of customers who rely on their platform's reliability to reach their audiences consistently.
With incident.io, Buffer transformed its Slack-based incident response into a structured, company-wide process, achieving a 70% reduction in critical incidents, a 5-minute average response time, and a 50% reduction in incident response time.
"We empower every teammate to declare an incident early: smaller fires beat big ones. We log more incidents because we see them sooner and fix them faster."
Raf Leszczyński, Senior Engineering Manager
The challenge
Buffer's incident response was fragmented across disconnected tools, resulting in inefficiencies during critical moments when reliability was most crucial. The problems spanned engineering coordination, customer communications, and organizational learning.
Buffer's incident coordination was centralized in a single channel that couldn't scale with their growth. "We used a single Slack channel for all incidents," explains Raf Leszczyński, Senior Engineering Manager. "When something happened, somebody would post a message, and the incident would become a Slack thread that might get to 200 or 300 messages. Engineers joining mid-incident had to wade through hundreds of messages to understand what was happening."
While engineering wrestled with massive Slack threads, customer advocacy ran parallel processes to coordinate their response. "We would have a separate thread going on in one of our advocacy channels coordinating around customer communications," says Hannah Voice, Head of Customer Advocacy Operations. "We'd create templates in Notion with all the customer communication tasks, then coordinate in Slack, updating all those places as the incident progressed—all while keeping one eye on the engineering thread to stay informed.”
From the Customer Advocacy side, getting through an incident could be a big job, and customer communications often relied on manual processes that left room for error. "We survived on checklists, lengthy documentation, and copying and pasting from templates," Hannah explains.
The complexity created a cultural problem where team members avoided raising issues unless necessary. People became hesitant to declare incidents because they didn't want to "bother engineers," meaning smaller issues often went unreported until they became larger, customer-impacting problems.
Buffer's biggest challenge was the lack of a consistent, systematic approach to learning from incidents and preventing recurring issues. "Postmortems were either really inconsistent or they were just skipped," notes Raf. "We'd find out we were repeating the same mistakes or not following through on things discussed in a Slack thread. The same critical incident would happen two months later because we didn't address the root cause."
The fragmented tooling created unnecessary friction and complexity. Alerts were sent through PagerDuty, coordination occurred in Slack, customer communications were managed via Atlassian status pages, and documentation was stored in Notion. During high-stress incidents, jumping between all these systems added cognitive load and increased the chance of missing critical steps.
The solution
As Buffer's leadership recognized the need for change, Hannah and Raf championed a comprehensive evaluation. Their focus wasn't just finding better software; they wanted to drive cultural transformation across the company. After evaluating multiple solutions, Buffer chose incident.io over competitors because of its intuitive design and user experience focus.
The Slack-native experience was crucial for Buffer's distributed team, but equally important was the user-friendliness for non-technical staff. Buffer needed a solution that could bridge engineering and customer advocacy teams effectively. "We wanted a tool that wasn't just for SRE engineers, but also for our peers from advocacy and other non-technical team members," says Raf. "The polishness and friendliness of the UI was deeply aligned with how we build our own product."
Beyond the platform itself, the partnership and cultural fit were significant factors in Buffer's decision. "The incident.io team were really great to work with," Hannah notes. "We saw features being shipped even while we were on the trial, which showed strong momentum. We felt aligned with incident.io's ethos, and the support was excellent—our questions were always answered quickly. That combination of great people, rapid development, and responsive support made the decision clear."
Buffer took a methodical approach, prioritizing adoption over speed, focusing on building confidence and competence across their teams. Hannah and Raf were conscious of ensuring success through comprehensive buy-in rather than rushing implementation. "We were very conscious of the fact that we wanted to make this successful and make sure everybody was bought into it, so we actually did quite a lot of work," Hannah explains.
They started with a small working group, then had everyone complete incident.io's tutorial. Most importantly, they ran comprehensive "fire drills" with test incidents across every engineer and advocate across all timezones. "We ran them as real scenarios so everybody got practice with their roles," Hannah explains. "Most people were in multiple test incidents before rollout, so they knew what they were doing."
incident.io replaced Buffer's entire incident stack: their manual Slack workflows, Atlassian status pages, and inconsistent postmortem processes all gave way to incident.io's unified incident management platform.
The results
The transformation delivered measurable improvements across engineering and customer advocacy, with impact extending company-wide.
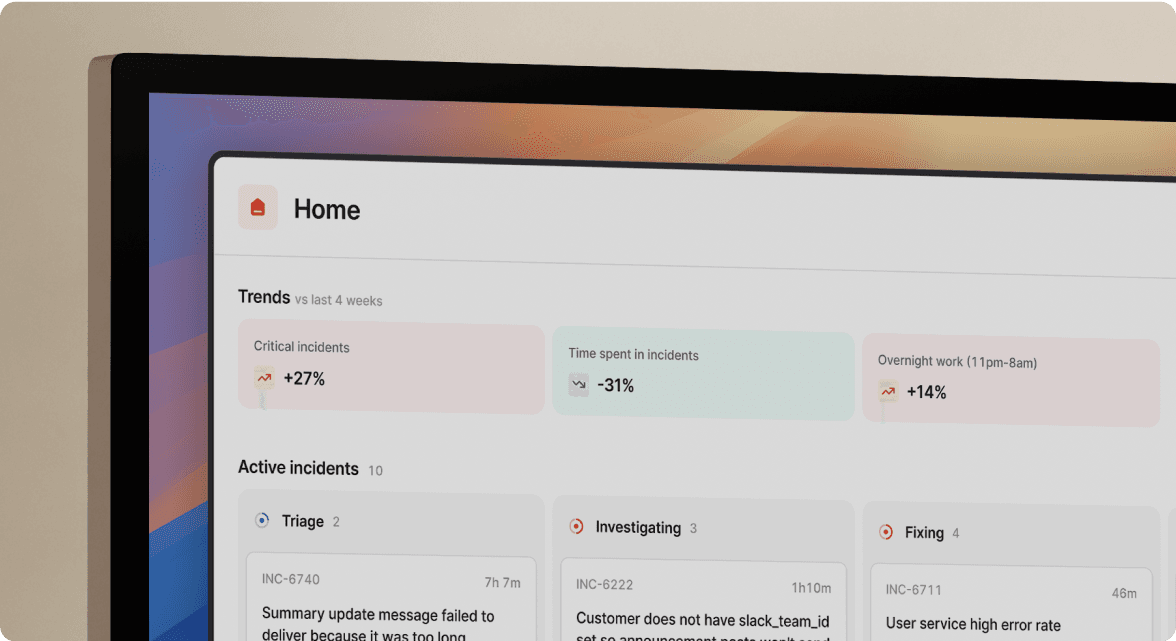
Buffer achieved quantifiable improvements in their incident response metrics. "I was doing the report for Q1, and it turns out we reduced the number of criticals by 70%," reports Raf. Response times improved dramatically: "It takes us on average around five minutes to acknowledge and be in the action of investigating and debugging."
Adopting incident.io helped reduce hesitation around declaring incidents and encouraged more proactive reporting. Previously, teammates were sometimes unsure about raising an incident if they thought it might be disruptive. Now, the team feels more confident about declaring incidents early, which has been a big win for catching and addressing issues sooner. As a result, Buffer now logs more incidents overall while spending about 50% less time on them, allowing them to resolve minor issues before they escalate.
For customer advocacy, incident.io transformed incident coordination and communication. "The coordination is a lot smoother now when it comes to completing tasks and updating customers," Hannah explains. "Not every Advocate needs to be fully involved in an incident. Each incident has a Comms Lead who decides if additional support is needed. Otherwise, the rest of the team can stay focused on keeping the inbox running smoothly."
The switch from Atlassian to incident.io status pages made a significant operational difference. "It was always difficult, even just logging in to update our Atlassian status page," Hannah notes. "It's so much smoother with incident.io, and we have templates now which we didn't have before."
How's this? Most crucially, Buffer now has systematic learning from every incident. "We have a clear structure where everybody knows who is leading, who is responsible for communications, and what the next steps are," Raf explains. "We also have a good way to analyze our metrics and see how we're doing, something that wasn't easily accessible before."
True to their transparency values, Buffer is considering making portions of their postmortems public to give users insight into how they prevent future issues. "For us at Buffer, it wasn't just about introducing an incident response tool. It was a cultural change to onboard our team into what it means to do incident response," reflects Raf.
Looking ahead
Buffer continues to expand its incident.io usage, planning to explore a migration from PagerDuty to incident.io On-call for complete centralization. They're particularly excited about the new AI SRE product, which could further automate incident response. "The whole vision of an incident happening and having an AI agent do debugging and investigation before we even get an engineer paged. That's amazing," says Raf.