Easier on-call: streamlining your setup
August 9, 2024

We’ve had a busy couple weeks improving incident.io On-call. While we like to ship big features, we’ve lately taken some time to sweat the details.
Improved manual escalations
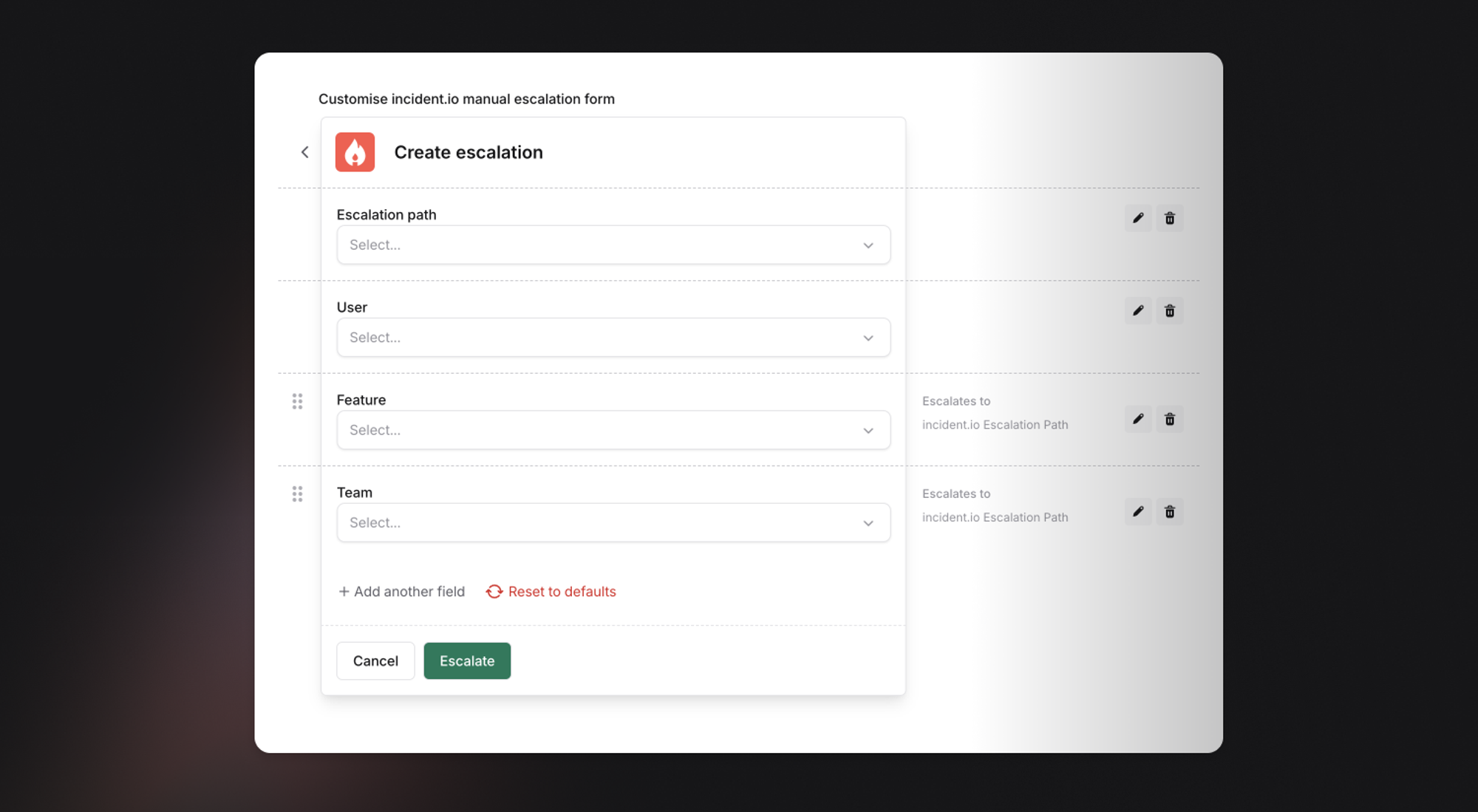
If you’re in the middle of migrating to incident.io, you might have some teams using PagerDuty or Opsgenie, and other teams using incident.io. When users are manually escalating to a team, it can be confusing to remember which teams are using which provider.
Now, you can configure manual escalations so that you just have to pick a Team, and we’ll figure out if we escalate through incident.io, PagerDuty, and/or Opsgenie, based on what’s configured for the chosen team in Catalog.
You can even use this after migrating to incident.io to make it easier for people in your company to get in contact with the right team. Rather than having to remember which team owns which feature, you can use Catalog to define that Ownership. Then, in the heat of an incident, you just have to search for the Feature, and we’ll handle escalating to the right team.
Learn more about setting this up in our help center.
Workflows for attached alerts
When an alert comes in and creates an incident, you often want to build automations that use details of your alerts to take an action. Previously, the only way to access those alert details was through a complex series of steps involving custom fields and the “incident created or changed” workflow trigger.
This required a lot of setup, and didn’t feel like the best experience we could offer. Additionally, representing these alert attributes on incident fields isn’t quite right—a trace ID isn’t something part of the incident, it’s on the alert!
Now, when an alert is marked as related to an incident—either by someone clicking “mark as related”, merging an incident with alerts into another, or having the alert attached automatically to an incident created by an alert route—you can trigger a workflow in response.
We use this ourselves to drive workflows like:
- When an alert has an "affected user" send a message to the incident channel with a link to that user in our data platform.
- Provide a link to the GCP BigQuery console and a SQL query you can run that shows failed test results.
📅 Smarter scheduling
Once a schedule is live, it's very common that you want to onboard new people onto the schedule, or change the order of the rotation.
When we shipped support for deferred schedule changes, we made it possible to have your changes take effect in the future, which made it safer and easier to adjust your schedule without affecting the current shift. However, you still had to do the hard work of figuring out how you should adjust your schedule handover date for the rotation to transition naturally.
As of last week, we will automatically calculate a new schedule handover time, so that your current on-call shifts aren't disturbed and you get an intuitive rota change, with zero effort.
New Alert Sources

We shipped three new native alert sources last week. These are:
Azure Monitors
Get alerted whenever one of your Azure Monitors fires, we support the whole suite of Azure Monitors so you can get alerts on anything from a log search to events in your Azure activity log!
BugSnag
Whenever an error occurs in Bugsnag, or you reach a threshold such as an elevated error rate, you can now bring that through to incident.io with our Bugsnag alert source.
Monte Carlo
Monte Carlo is an observability tool for your data stack, and with our native alert source, you can now be alerted to data quality issues and anomalies in incident.io.
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.

We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


