"The dashboard looks broken!": How should data teams respond to incidents?
November 21, 2023 — 8 min read

Data teams are adopting more processes and tools that align with software engineering, and from talks at the dbt Coalesce conference in 2023, there’s clearly a big push towards adopting software engineering practices at enterprise scale companies.
At the moment, there are a lot of tools in the data space for identifying errors in data pipelines, but no tools for responding to these errors, such as coordinating fixes.
This is exactly where an incident management platform makes sense to implement. With one, data teams can put better processes behind how they respond to data errors and be more efficient as a result.
“The key metrics dashboard looks broken, can you take a look?”
If you're on a data team, it's likely that you've fielded this question many times. Bonus points if it’s on a Friday afternoon.
Breakages in data pipelines are inevitable: continually changing data models, business logic, dashboards, and upstream data make it a reality that it’s a case of “when” rather than “if” it happens.
But just because it’s inevitable, doesn’t mean that you shouldn’t take steps to make the process of identifying and fixing these breakages as smooth as possible.
Let’s consider how this flow typically looks:
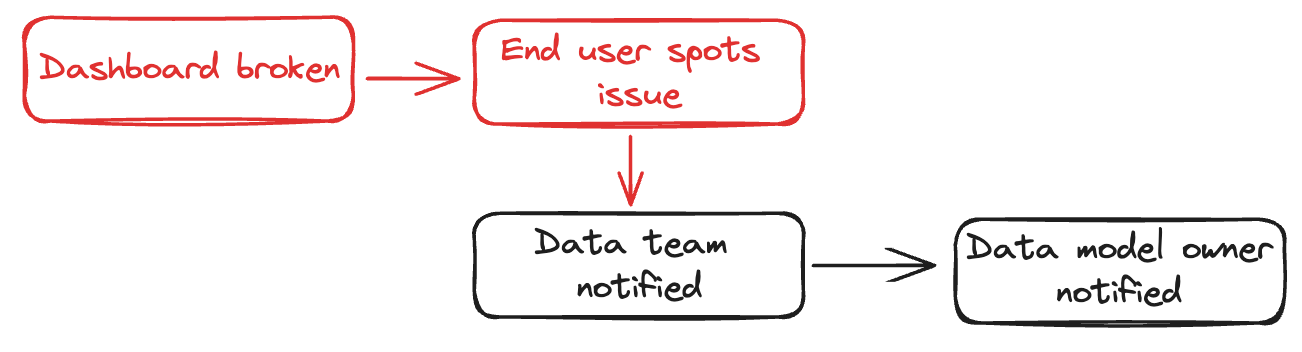
This, unsurprisingly, is flawed for a few reasons:
- Bad or broken data shouldn’t be reaching dashboards in the first place
- The end user’s trust in the dashboard is gradually lost the more it happens
- There are three separate, manual steps before the person who can fix it is notified
Identifying breakages, earlier
Automated tests implemented with tools like dbt helped catch problems with your pipeline, earlier. Observability tools, like synq, went one step further: identifying repeatedly failing tests, routing failures to the right owners, spotting anomalies (like your table row count suddenly halving), and even sending messages to tools like Slack for debugging.
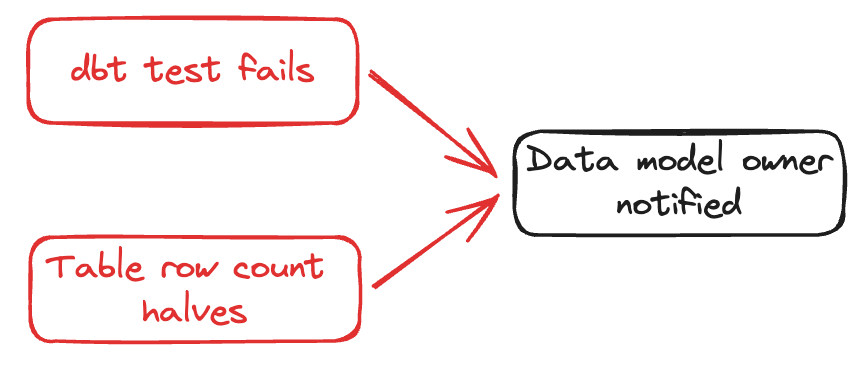
This flow is a lot more effective. It’s shorter, automated, and the more common consequence is dashboards becoming stale, not broken.
But the concepts of automated testing, observability, and routing failures aren’t new: it’s part of a larger shift amongst data teams towards adopting the types of tools and processes used by software engineers.
After all, why try to reinvent the wheel?
So we now have a better way of identifying when something is broken, but what happens next?

Chaos
Let's imagine this: you’ve got a stakeholder who has spotted a problem with your dashboard, or you’ve been notified of a problem with a critical data model that will cause stale or incorrect data downstream.
What do you do next?
There are observability tools which will allow you to resolve a data incident outside of Slack/Teams, but ultimately communication to stakeholders and collaboration with people who you’re fixing the issue with will always trickle back to these messaging tools.
The bulk of the messaging will happen in a channel or a thread, like below.
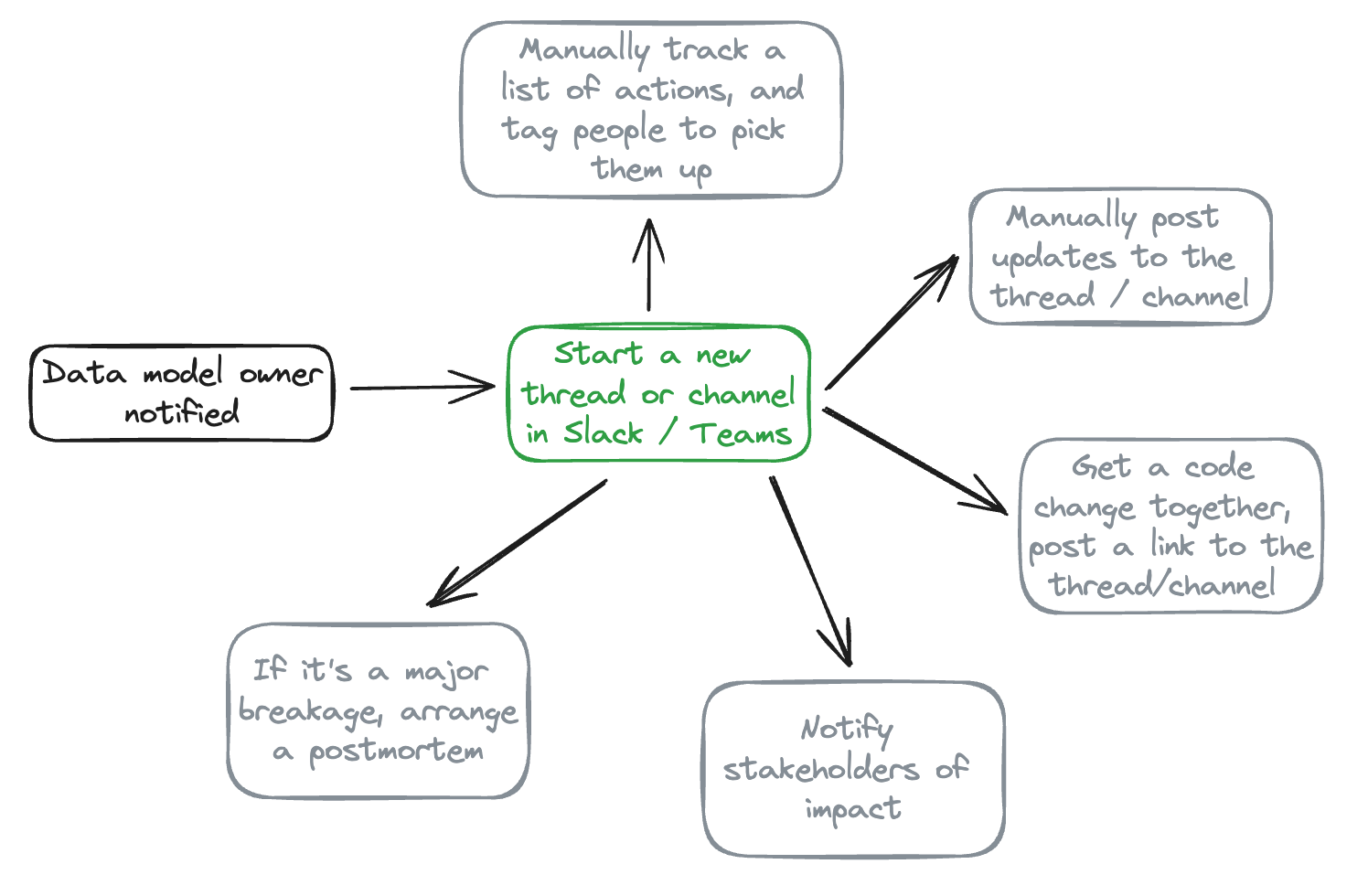
This causes a number of problems:
- Noise: filtering through what messages are debugging, updates, etc., is tricky for stakeholders. People fixing the issue have to manually surface updates
- Ownership: figuring out who is doing what, and when, is a manual exercise and becomes exponentially more complex the more people are responding to the issue
- Tracking: if a data model breaks tten times in a month because of an upstream issue not caused by your team, then it’s hard to quantify the time you’re spending resolving it, or spot longer term trends
The last point is particularly painful. Being a data team that’s downstream of consistent errors can be quite demotivating, especially when the only evidence is in random messages and threads.
(Organised) chaos
Data teams have adopted a lot of the tools and processes used by software engineers to help identify issues, so why not extend this to resolving these issues?
We use our own product at incident.io when things go wrong in our data pipeline, and having fixed data pipelines both with & without an incident management tool in place, I thought I’d share some top tips for responding to data incidents.
Channels > threads
This is what I’d consider as “table stakes.” It’s tempting to debug everything by replying to the thread where the issue was raised, but this results in a noisy mess that gets worse the more complex the issue is to fix.
Each data incident should have its own dedicated channel.
Once in a channel, it’s a lot easier to keep things tidier—such as having a single thread for debugging a specific issue, or posting standalone updates that you pin to the channel.
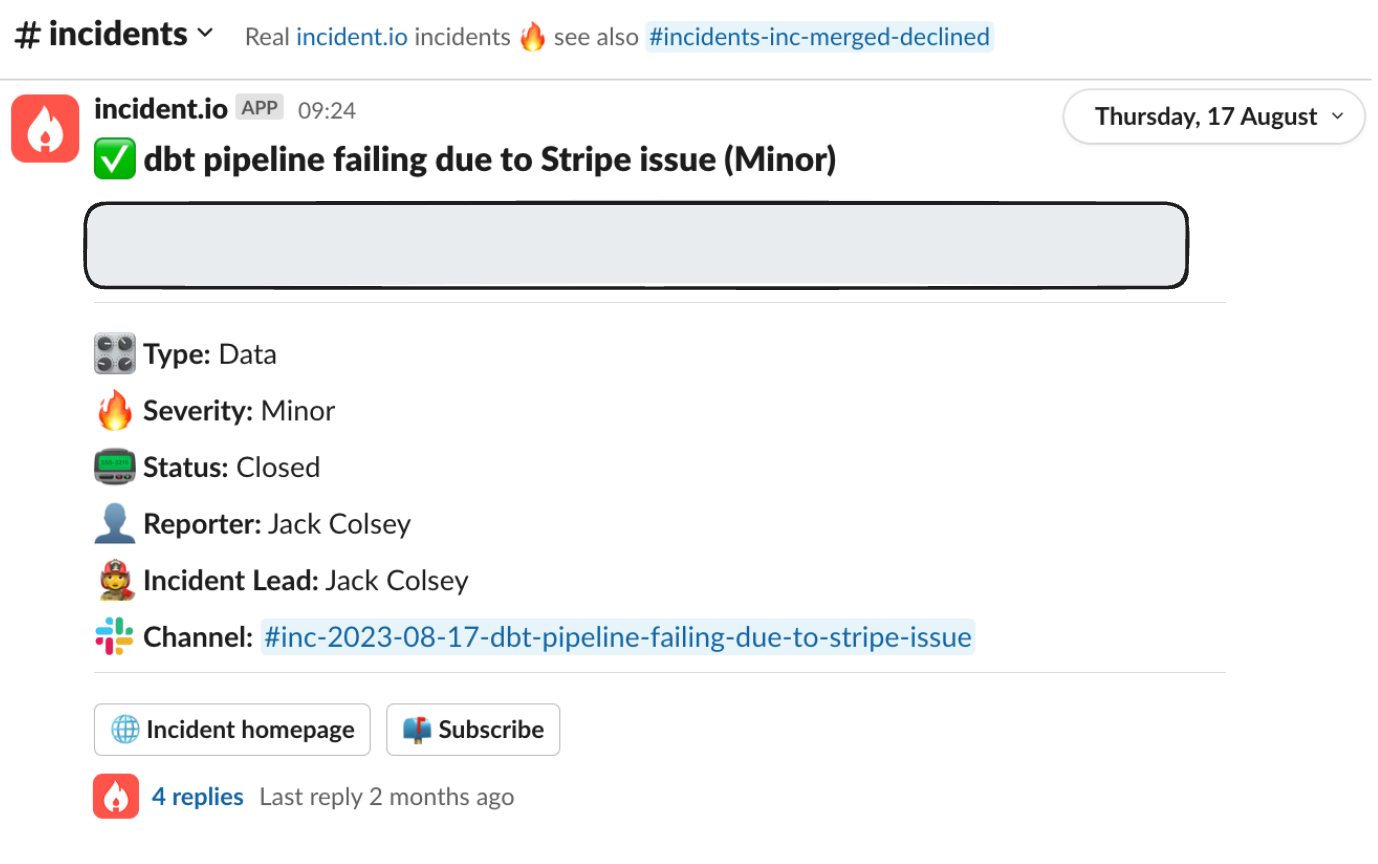
Make it easy to get updates
Channels are a lot better for people responding to incidents, but they can still be a bit overwhelming for a non-technical stakeholder who’s just looking for updates.
You should provide a way for people to stay in the loop outside of the channel you’re using to respond to the issue.
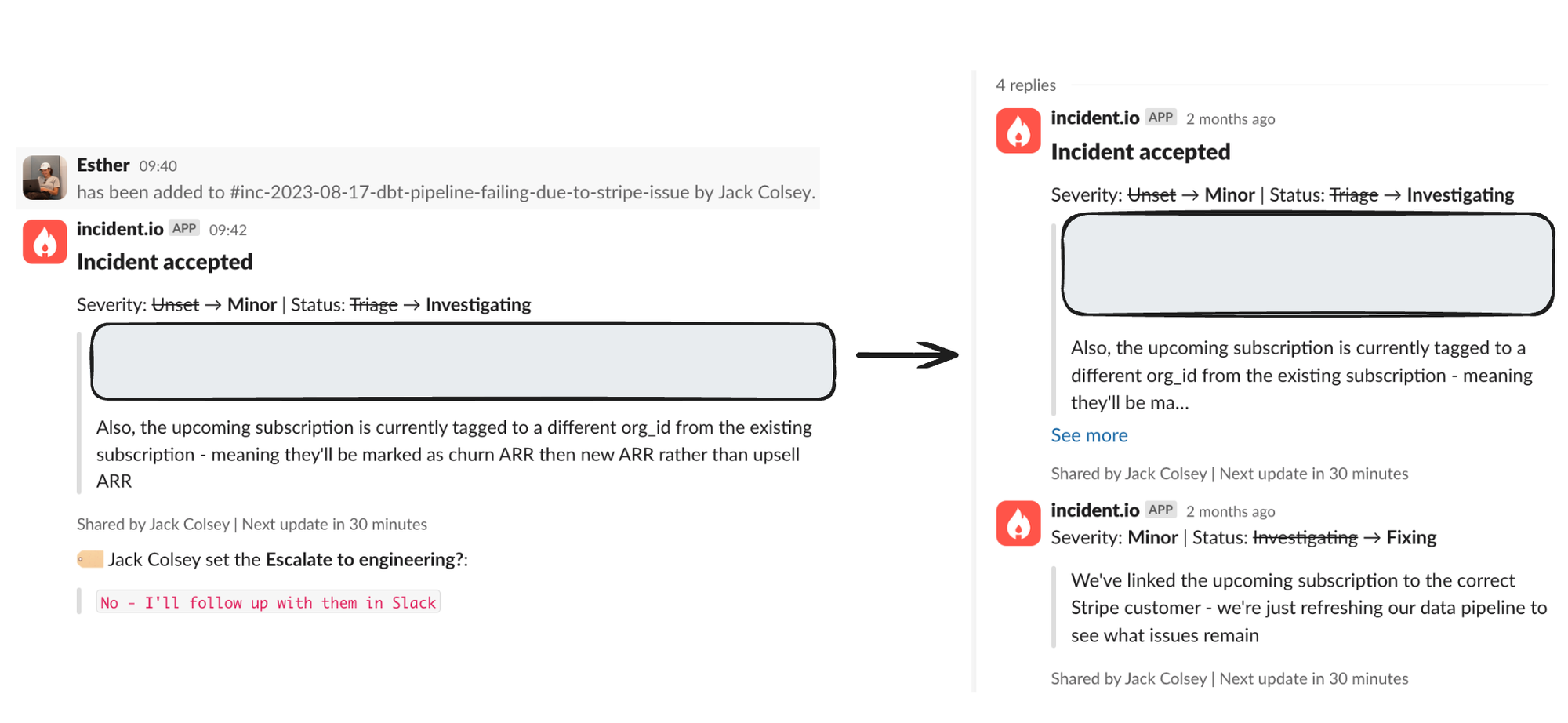
Updates created in the channel are automatically threaded against the original Slack message where the channel was created, and sync with our web app
Clear actions, clear owners
Every incident should always have a lead. This doesn’t mean that person is responsible for fixing everything, but they are responsible for coordinating the response and keeping people updated on progress.
A similar approach applies to actions—it should be clear who is owning what fixes, this is especially important with incidents where multiple people are collaborating on fixes.
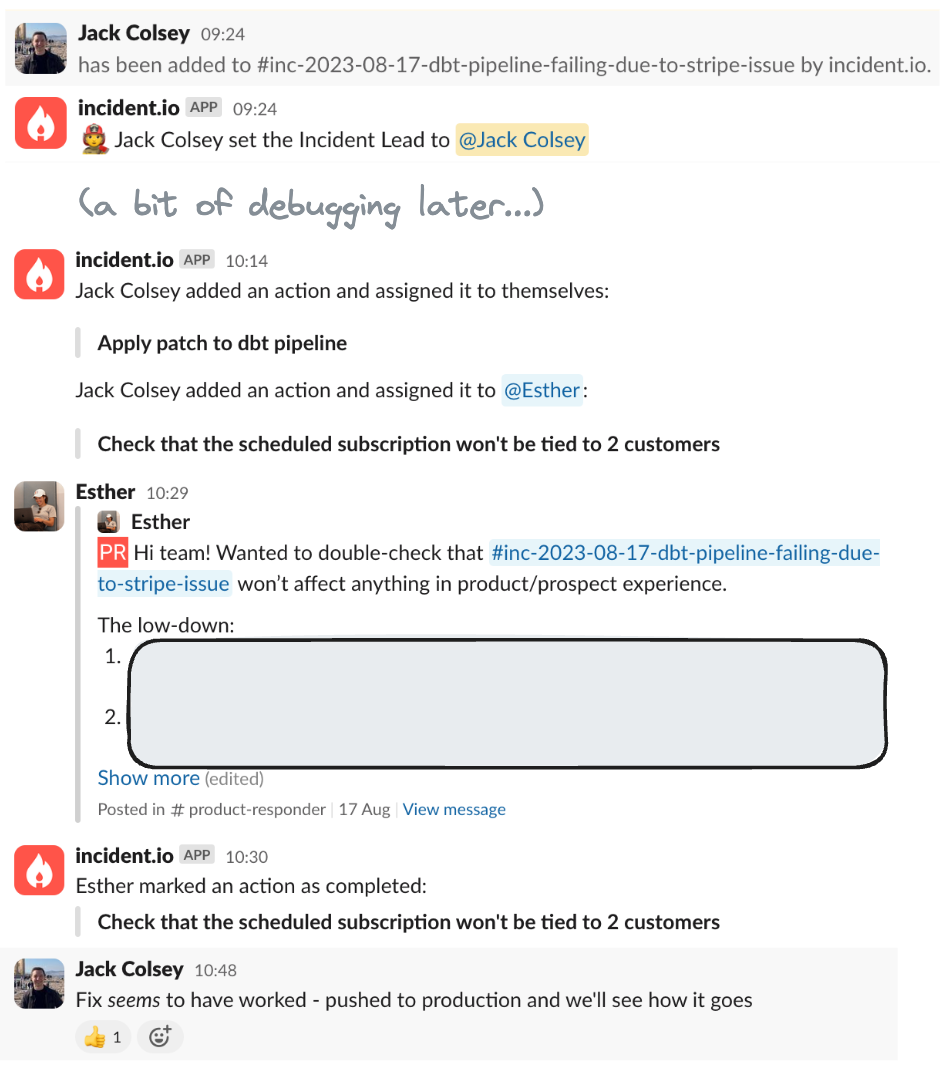
Track
If a data team is downstream of a lot of data quality issues then a lot of their time will be spent on identifying & resolving issues they didn’t create, and not on value add activities. In short bursts, it can be manageable, but over time it can sap a team’s capacity and be quite demotivating.
A great tool to help combat this is, of course, data! Even tracking the number of data incidents, and some form of useful tagging for the root cause (e.g. upstream system) can go a long way to getting budget allocated to fixing the issues upstream.
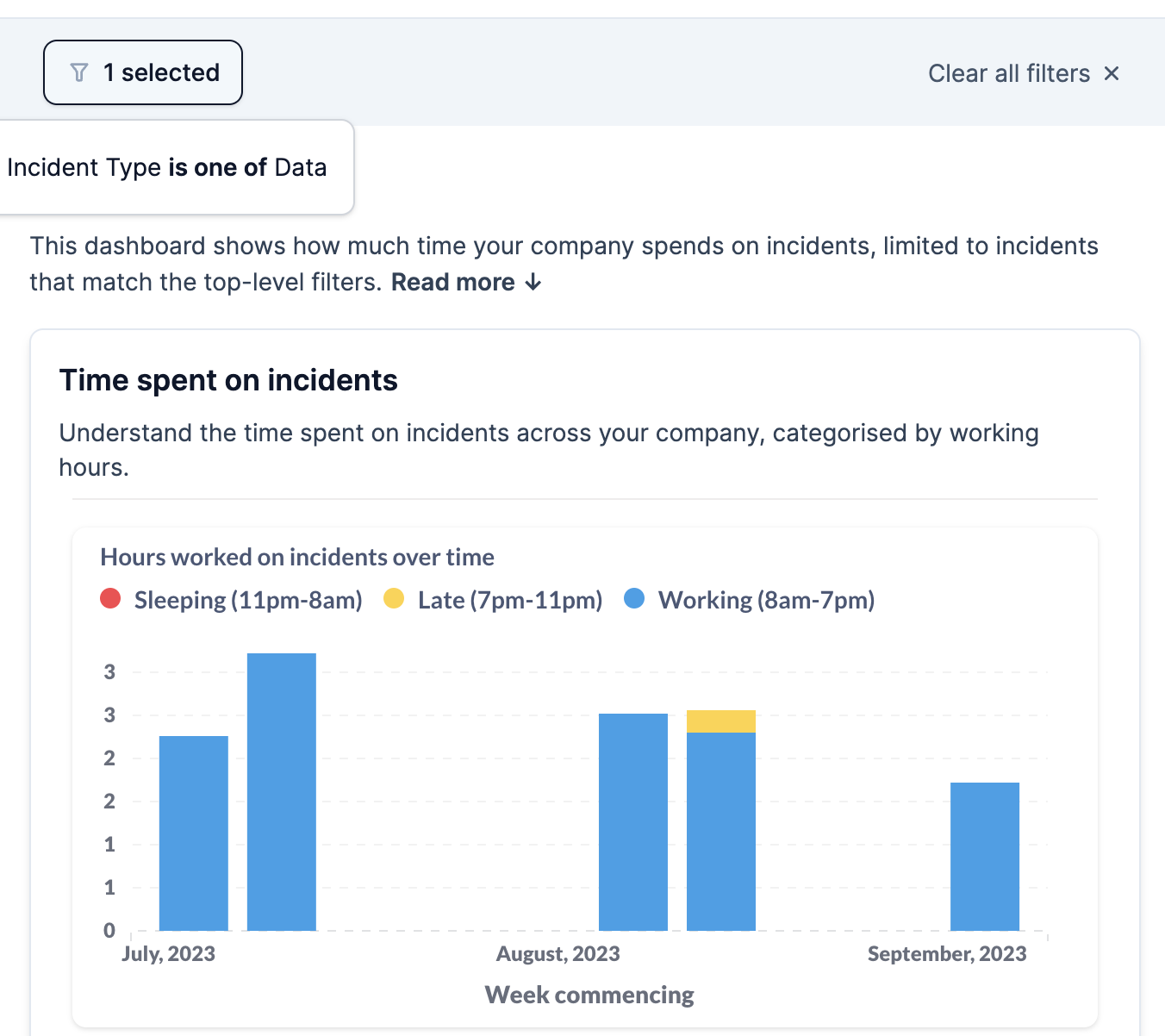
We calculate time spent on incidents using time between items in an incident channel (messages, updates, actions) and infer whether it’s continuous time spent.
Incident management can be for data teams—and the entire organization

As the tools that data teams use to identify pipeline errors (earlier) grow in maturity, it’s important not to forget how you respond to these issues and get the right processes in place to do so.
We only need to glance over at how software engineers do incident management to know that Data teams don’t need to reinvent the wheel, a small amount of structure goes a long way!
If you want to learn about more ways that data teams, and organizations as a whole, can integrate incident management into their processes, then check out our guide: Incidents are for everyone.

Jack Colsey
Head of Data
See related articles

Your genie is vanishing: introducing the Opsgenie rescue program
Today, we're launching the Opsgenie Rescue Program to make that landing soft: simplified migration and free overlap so you never pay two vendors at once.
 Tom Wentworth
Tom WentworthJuly 9, 2026

De-risking a PagerDuty migration: the objections we hear most, and how to clear them
Often, switching on-call platforms isn't a technical challenge but a human one. In this post, we break down the seven objections engineering teams raise most often when considering a PagerDuty migration, and share exactly how to address each one.
 Eryn Carman
Eryn CarmanJune 9, 2026

Customers over control: how we measure On-call reliability
Instead of thinking about reliability as an exercise in figuring out what we can control, and ignoring anything beyond that, we think about what we'll be really proud to offer to customers.
 Mike Fisher
Mike FisherMay 28, 2026
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization

