Engineering nits: Generating code faster
December 11, 2023 — 5 min read

Here at incident.io, we use Go for all our backend. As with many Go apps, we generate a lot of code which can look a bit strange if you’re coming from another language, but is incredibly powerful. This is a mixture of open-source tools like mockgen and our own custom tools.
As our app has grown however, running go generate was getting slower and slower, making simple tasks take much longer than you might expect, and just being frustrating.
In this blog post, I’ll explain how we made one of our code-generation scripts 97% faster, saving around 3 engineer-hours per week.
What we are generating
Before we dive in, let’s talk quickly about what we’re generating here. We’ve talked a bit about this before with generating builders for our partial-structs library, but we also generate type-safe gstruct matchers, which look like this:
package eventmatchers
// BookmarkChanged creates a Gomega matcher for event.BookmarkChanged against the given
// fields. Matchers are applied first to last, with subsequent matchers taking precedence.
var BookmarkChanged = BookmarkChangedMatcherFunc(func(opts ...func(*event.BookmarkChanged, *gstruct.Fields)) types.GomegaMatcher {
fields := gstruct.Fields{}
for _, opt := range opts {
opt(nil, &fields)
}
return gstruct.PointTo(
gstruct.MatchFields(gstruct.IgnoreExtras, fields),
)
})
type BookmarkChangedMatcherFunc func(opts ...func(*event.BookmarkChanged, *gstruct.Fields)) types.GomegaMatcher
type BookmarkChangedMatchers struct{}
// Match returns an interface with the same methods as the base matcher, but accepting
// GomegaMatcher parameters instead of the exact equality matches.
func (b BookmarkChangedMatcherFunc) Match() BookmarkChangedMatchers {
return BookmarkChangedMatchers{}
}
func (b BookmarkChangedMatcherFunc) OrganisationID(value string) func(*event.BookmarkChanged, *gstruct.Fields) {
return func(_ *event.BookmarkChanged, fields *gstruct.Fields) {
(*fields)["OrganisationID"] = gomega.Equal(value)
}
}
func (b BookmarkChangedMatchers) OrganisationID(value types.GomegaMatcher) func(*event.BookmarkChanged, *gstruct.Fields) {
return func(_ *event.BookmarkChanged, fields *gstruct.Fields) {
(*fields)["OrganisationID"] = value
}
}
...That’s quite a big lump of code, but is relatively simple:
BookmarkChangedis a function that will merge together a bunch of single-field matchers, into something which matches against the whole struct.OrganisationID()(and other similar methods) on that type define a single-field matcher for equality only that can be combined together withBookmarkChangedBookmarkChangedMatcherscreates a similar set of single-field matcher generators, but which take a more complex matcher (likeHasPrefixorBeEmpty)
That means you can write tests that look like this:
Expect(ev).To(eventmatchers.BookmarkChanged(
eventmatchers.BookmarkChanged.Match().OrganisationID(HavePrefix("O123")),
))Pretty neat!
The dreaded slow-down
As our codebase expanded, generating these matcher functions got really slow, and that really doesn’t make much sense! To generate them, all we do is:
- Use
go/parserto find structs in the folder which have a magic// codegen:matchercomment above them - Inspect each of those structs to find all the fields in them
- Template out the matcher functions and structs
That really doesn’t feel like it should be very slow, after all it’s just reading a bunch of code, running some simple logic on it, and spitting out some more code… right?
The first suspicious bit is this:
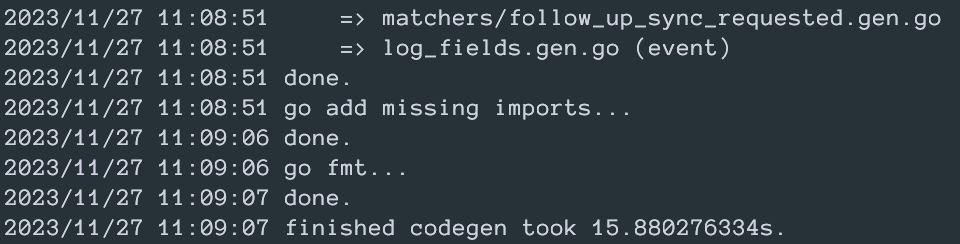
All the parsing and templating is done in under a second, but adding missing imports takes 15 seconds. Almost the whole time!
What is goimports?
goimports is a drop-in replacement for go fmt, which automatically removes unused imports, and adds imports that are missing.
There’s a really good write-up of exactly how it does this in this blog post, but it boils down to:
- Find missing imports in each file
- Check if any of those can come from standard library packages (like
timeorstrings) - If not, scan all the possible imports within our app, and all the libraries in our
go.mod.
Turns out that doing that is pretty slow, and doing it hundreds and hundreds of times is really slow.
How do we go faster?
All we need to do to make this much quicker is to reduce the number of missing imports in the generated code, since that means that goimports has much less work to do.
If that means adding too many imports, that’s fine. Stripping out unused imports is really really fast, because there’s none of that scanning of all possible imports to do - goimports can just look at the contents of a single file, go “that’s not used in here” and delete it.
There’s a smart way to do that: when parsing in the original files, we could copy across all the imports into the generated file, add the extra imports the templated code uses, and then let goimports remove the unused ones.
There’s also a really simple way: just add loads of the most commonly-used imports to the template. Building a good list is really easily with go list:
$ go list -f '{{range $imp := .Imports}}{{printf "%s\\n" $imp}}{{end}}' ./pkg/event/matchers
github.com/incident-io/core/server/pkg/event
github.com/onsi/gomega
github.com/onsi/gomega/gstruct
github.com/onsi/gomega/types
gopkg.in/guregu/null.v3
timeThat’s every package imported from the generated matchers. Putting all of those into the template doesn’t do any harm (the unused ones get cleaned up!), but makes goimports's job much much easier.
With this one change, codegen goes from around 16 seconds to under half a second.
What can we learn?
There’s two things I’ve learned from this. Firstly, something really simple can be incredibly effective. This change was about 20 lines of code, and reduces the runtime by 97%.
Secondly: investing in your development workflow always pays off. We’re a team of around 20 engineers now, so go generate gets run pretty often! Just in the few days before this change engineers were waiting for this to run for 34 minutes, which would now be about 2-3 minutes.
For a change that took about 20 minutes to put together, that’s a pretty immediate return on investment!

Isaac Seymour
Product Engineer
See related articles

Engineering nits: Building a Storybook for Slack Block Kit
We care a lot about the pace of shipping at incident.io, and we also build lots of UIs inside Slack. Slack previews lets us collaborate on designing these experiences much more quickly.
 Lawrence Jones
Lawrence JonesNovember 28, 2023

Making code-generation in Go more powerful with generics
Go 1.18 added generics to the language a few months ago. Here’s how we’ve combined generics with code generation to make our code safer and easier to read and write.
 Isaac Seymour
Isaac SeymourOctober 20, 2022

Keep the monolith, but split the workloads
Everybody loves a monolith, but you can hit issues as you scale. Learn how splitting workloads can improve your monolithic architecture's performance and scalability, and understand the trade-offs between monolithic systems and microservices.
Lawrence JonesApril 12, 2023
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization


