10 new alert sources for enhanced monitoring
April 9, 2024

Alert sources allow you to ingest alerts from third-party providers and bring them into incident.io - from there, you can set up routes to create incidents and notify your engineers as needed.
Since launching Alerts, we now support over 10 additional alert sources to help you achieve your specific workflows - here’s an overview of some of our most used integrations.
Setting up an email alert source is particularly useful when you want to automate a support issue to incident process. This alert source will allow you to cover complex support use cases, such as the following:
- Receive an email from priority customers
- Based on the email domain, map this email to a customer in your catalog
- From there, create a new incident with rich context around your customer
Google Cloud
With our Google Cloud alert sources, GCP customers can get alerted for scenarios such as the following:
- Get notified when a Pub/Sub queue is backed up
- Get notified when your database is under extreme load
- Get notified when your billing goes above a set threshold
Grafana
The Grafana alert source allows you to ingest your Grafana alerts into incident.io. We’ll automatically link you to the Grafana panel that created the alert, shortening the time from firing to resolved by allowing your engineers to jump straight in.
As a bonus, with our AWS SNS integration, we now also support AWS Managed Grafana as a first class integration.
Other alert sources
We’ve also released plenty of other alert sources that have their own full set-up instructions. Some of these include:
- New Relic
- Runscope
- AWS SNS
- Cronitor
- Pingdom
- Honeycomb
- Checkly
To get started, head over to Alerts > Sources > New alert source, and follow the instructions as provided for your chosen provider. You’ll also see a full list of all supported integrations (over 20 and counting!).
Don’t see the alert source you’re looking for?
If you don’t see your alert source in the list, please send us a message and we’ll be happy to check if it’s possible for us to build an integration with your provider. In the meantime, you can use connect via the generic HTTP alert source to quickly get going.
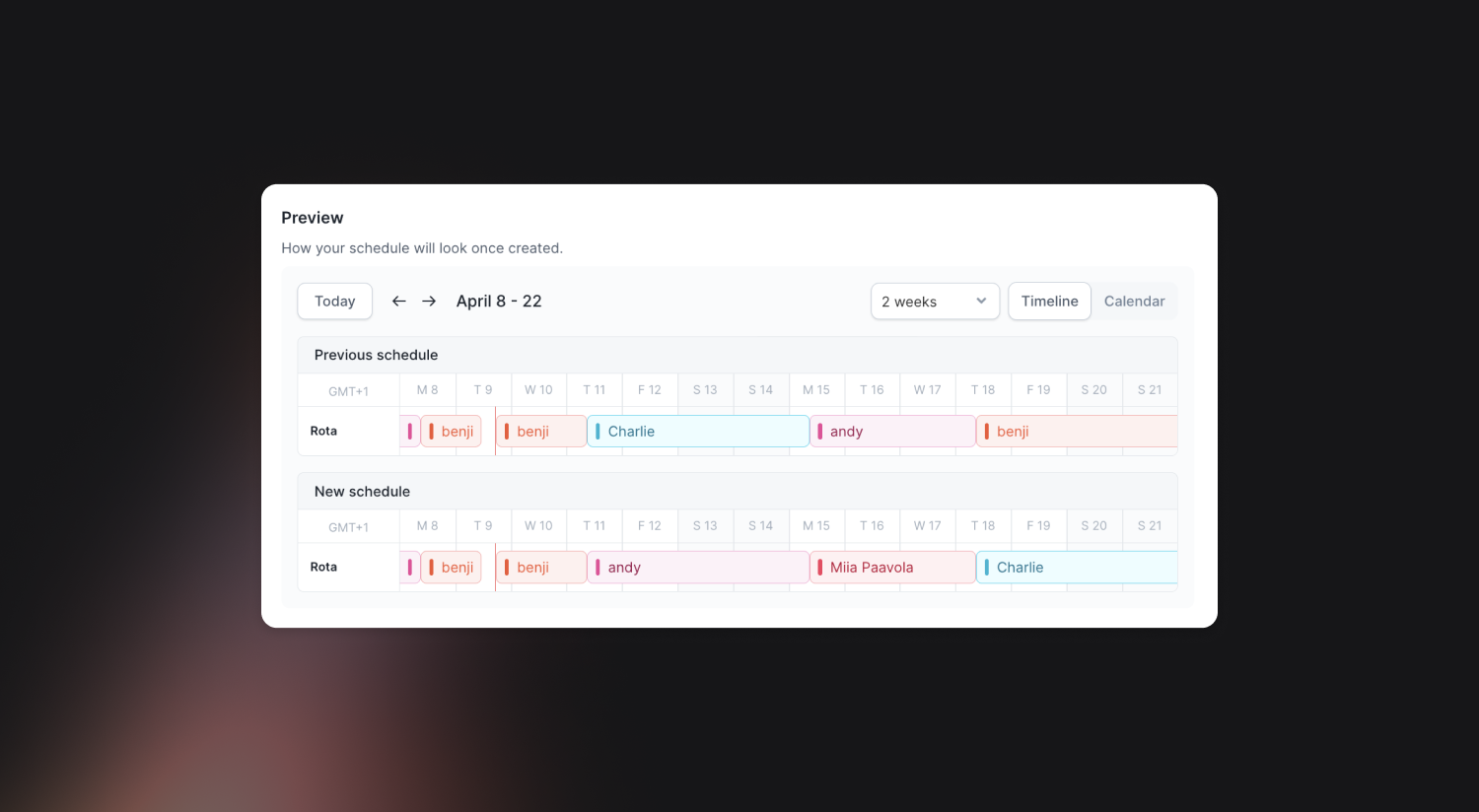
Schedule previews while editing
You can now see both your current and previously edited schedule previews together when making changes to a schedule. This can help you understand the changes you are making and decrease possible mistakes happening when editing.
🚀 What else we’ve shipped
New
- It’s now possible to configure status pages to automatically route users to the correct regional subpage based on their location. This isn't yet configurable in the UI, so reach out to us if you're interested and we'll help you get set up!
- Public API for incident updates now includes ID of any merged incidents
- You can now look for catalog types using the CMD+K search in the dashboard
Improvements
- We’ve improved the performance of external calendar feeds for schedules, which fixes an issue where they sometimes didn’t update
- Improve the way we handle date and number translations within status pages using Localize
- See weekends highlighted in grey in the schedule timeline
- incident.io logo can now be clicked on in the dashboard to go back to the homepage
- Support closing dashboard drawers with the
escapekey - Users without permissions will no longer be able to open the schedule drawer from the On-call welcome banner
- It's now more obvious what causes a status page view spike alert to be triggered
- We now surface interval validation failures on schedule creation or edit
Bug fixes
- Fixed a bug preventing users from resubmitting a schedule creation or edit if the request already failed once
- Fixed a bug showing cover requests mobile notifications in UTC timestamps rather than local time
- Fixed an issue where you couldn’t see the preview of alerts for an alert source when using an expression that returns an array
- Fix a bug marking a user as active when they log in with SAML for the first time
- Fixed a bug where we would sometimes incorrectly choose a post-incident cycle when resolving from Slack
- Fixed a bug where you couldn't reconnect to Notion
So good, you’ll break things on purpose
Ready for modern incident management? Book a call with one of our experts today.
We’d love to talk to you about
- All-in-one incident management
- Our unmatched speed of deployment
- Why we’re loved by users and easily adopted
- How we work for the whole organization



